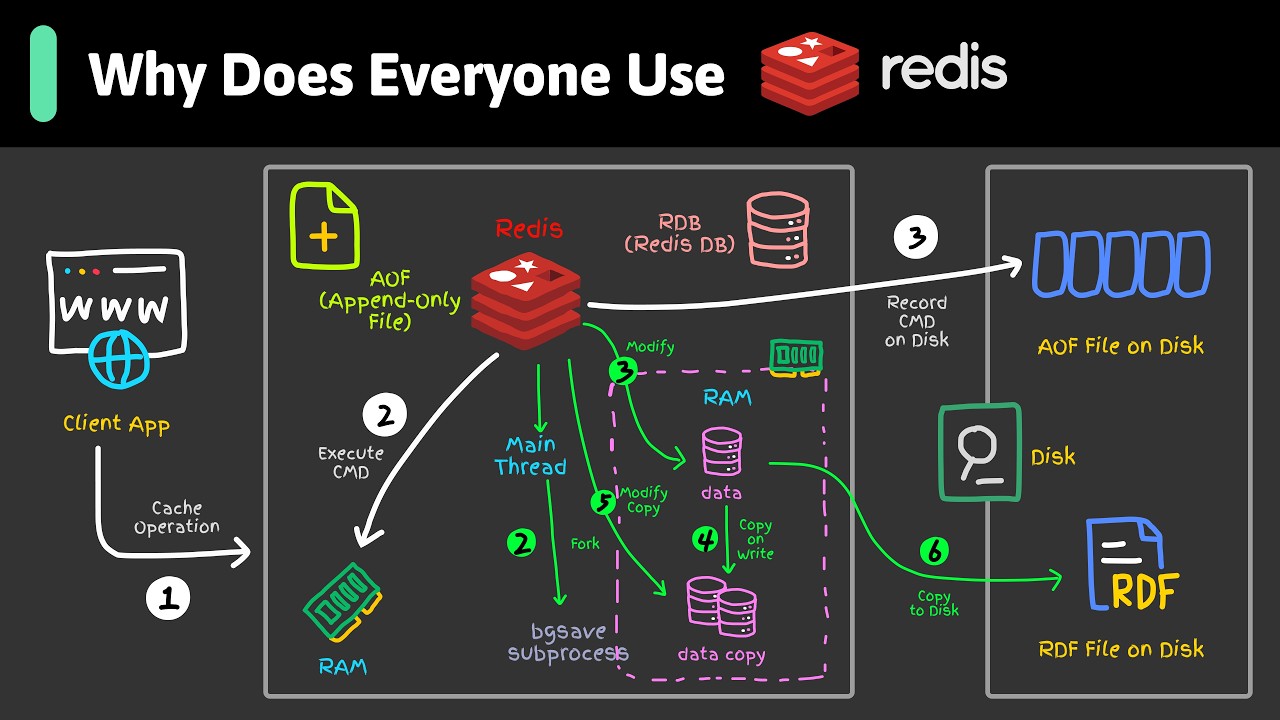
Transformers Step-by-Step Explained (Attention Is All You Need)
Machine-readable: Markdown · JSON API · Site index
Описание видео
Build better full-stack authentication and user management with Clerk: https://go.clerk.com/Q8BtT1n
--
We just launched the all-in-one tech interview prep platform, covering coding, system design, OOD, and machine learning.
Launch sale: 50% off. Check it out: https://bit.ly/bbg-yt