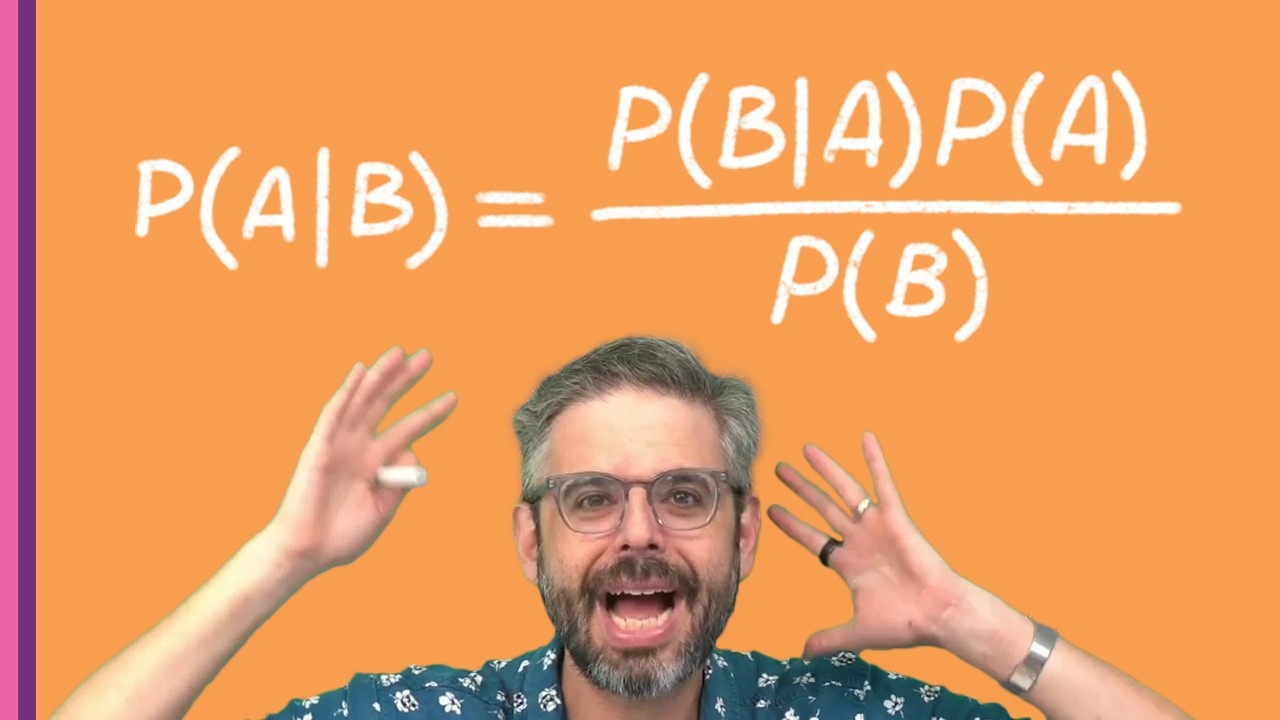Warning, this live stream was a mess and is probably unwatchable! But if you choose to continue you'll see me attempt to build a Naive Bayes text classifier from scratch in the p5.js web editor! I start by explaining the core concepts behind Bayes' Theorem (multiple times) before diving into the code. You'll see my raw, unedited process of structuring the data, implementing the algorithm, debugging issues, and finally building a simple interactive sentiment analysis demo.
Code from live: https://editor.p5js.org/codingtrain/sketches/vZQKzBXJT
Polished code: https://github.com/Programming-from-A-to-Z/bayes-classifier-js
https://youtu.be/unm0BLor8aE
https://youtu.be/RPMYV-eb6lI
https://youtu.be/fxQ0B6BkfKo
https://youtu.be/HZGCoVF3YvM
00:00:00 Choo choo!
00:05:35 Welcome & Announcements
00:10:49 Fall Plans
00:14:19 Technical Difficulties: Whiteboard Setup
00:23:20 Main Topic: Bayesian Text Classification
00:33:03 Whiteboard: Explaining Bayes' Theorem (Attempt 1)
00:44:02 Technical Difficulties: Muted Microphone
00:45:52 Whiteboard: Explaining Bayes' Theorem (Attempt 2)
01:24:54 Live Coding Begins
01:32:42 Re-recording the Introduction for Edited Video
01:40:13 Technical Difficulties: Camera Overheating
02:04:10 Coding Resumes: Building the Classifier
02:51:10 Explaining Laplacian (Additive) Smoothing
03:12:20 Normalizing the Final Probabilities
03:24:12 Coding Challenge Complete!
03:24:43 Reviewing a More Polished Version of the Code
03:30:35 Good bye!
🚂 Website: https://thecodingtrain.com/
👾 Share Your Creation! https://thecodingtrain.com/guides/passenger-showcase-guide
🚩 Suggest Topics: https://github.com/CodingTrain/Suggestion-Box
💡 GitHub: https://github.com/CodingTrain
💬 Discord: https://thecodingtrain.com/discord
💖 Membership: http://youtube.com/thecodingtrain/join
🛒 Store: https://standard.tv/codingtrain
🖋️ Twitter: https://twitter.com/thecodingtrain
📸 Instagram: https://www.instagram.com/the.coding.train/
🎥 https://www.youtube.com/playlist?list=PLRqwX-V7Uu6ZiZxtDDRCi6uhfTH4FilpH
🎥 https://www.youtube.com/playlist?list=PLRqwX-V7Uu6Zy51Q-x9tMWIv9cueOFTFA
🔗 p5.js: https://p5js.org
🔗 p5.js Web Editor: https://editor.p5js.org/
🔗 Processing: https://processing.org
📄 Code of Conduct: https://github.com/CodingTrain/Code-of-Conduct
Оглавление (17 сегментов)
Choo choo!
Come on. Okay, check one, two. I'm testing my audio to see if you can hear me. Uh, let me know in the chat. I realize the balance might be a little bit off with the music. Uh, but I won't be playing music while I'm speaking otherwise. So, hopefully it's um sounds good to you. Okay. Be live in about a little over a minute or two. I guess I am live now, but properly starting in a minute or two. This is going to be a little rough today. Okay. But I can do it. Okay. See you. See you soon. Yes, James, you are hearing me correctly. I think I have a cold. I was wondering if anybody would notice. Ah, so much for my starting date of September 15th, but I'm starting anyway. Heat. Let's go.
Welcome & Announcements
Hi. I guess my timer needs to be adjusted if I'm going to play two songs before I start. Should also let everybody know before I begin. There is a bee flying around this room. Seems to be mostly attracted to the brighter lights, so I don't think it will come and sting me. Hopefully, I'm not muted. No, you can hear me. I'm checking out the chat here. Oh, new comments. Ah, I haven't been reading the chat. Okay. Hi, everybody. It's Monday, September 15th. I don't know. I feel like I'm h things are a little rough for me these days. I mean, they really aren't in the grand scheme of things. I'm doing quite well. You should not be worrying about me. But I suppose if you want to indulge an old man who's been on YouTube for a decade in his own woes and angst. I mean, I'm really trying to figure out a way to get this coding train back onto the tracks in the way that it once was. But maybe that will just never happen and it will just be what it will be, which is what it is. Hi everybody. Where are you watching from? I love to hear that in the chat. Uh DJ Manga says, "Oh, I can I don't even have to uh I forgot that I have this way of doing this, which is uh DJ Manga says, "Morning Dan. Nice to see you live. First time in a while I've been able to attend. Thrilling. " Well, um thank you for being here. Uh I'm also going to add this comment which is audio is good. You got a cold? I think so. It's ve it's I only started to feel it this morning. Could be allergies, but my head is cloudy. I'm a bit congested. I have a bit of a headache. My mind is not operating on full capacity. So bear with me. I had and what I was saying and I think this button here will take the comment off the screen and I can click over here and kind of keep an eye on the chat. Huh? Chairless crocodile watching from Greece. Where in Greece? I have many connections to Greece and I was there over the summer. Many connections. I have like one connection but um and so Germany and Italy and Turkey. Incredible. India. I love to see people from all over the world. Okay, let's have a little pow-wow for a second because I do not want to well what is wasting time if anything? I don't know. I don't want to use up a lot of time with my banter. Uh I want to get into building a project on today's live stream. But if you will first indulge me. So, and I let me do a little um experiment here with um uh using this uh vibe board for a second just to try to um where did I put the I mean, you can't see me right now, but I have no idea where I put the marker for this thing. It's not a marker. It's like a Ah, here it is. Okay. Um, don't look at me. Don't look at me typing in my uh code. Okay, hold on. Come back over here. This thing goes to sleep after like one minute. I've got to find that setting. Uh, okay. All right. Um, somebody put Oh, I need like um one new feature I want on my live stream is I want to be able to press a button. type. Oh, this would this is easy. I could build a web app to do this for me, but essentially I want to be able to put in a timer and press a button and have a big sound effect go off when it's over. Because right now, no more than maybe, let's say, seven minutes, 10:45. Oh, I'm not I'm talking to the wrong camera. Um, 10:45. I don't want to be talking about my plans anymore. Okay, this camera is weird. Weird, but maybe it's fine. I'm doing my best. Deep breath, everybody. Okay, if you tuned in to any of my live streams over the summer, first of all, if you didn't and you like want to go watch them, I mean, that's wonderful because my channel views are very down. It's fine. But I did three live streams. One, I just talked for a while about like I'm trying to get back into the coding train. Two, I had Kit from P5JS talking about P5 2. 0. Three, I had uh Dr. Christian Hubiki. And by the way, I should say Dr. Kit Kenok. I mean, I don't know. I don't know why sometimes I use the doctor title for people and sometimes I don't. Anyway, I had these wonderful guests. They're both doctors, but uh Christian came on and uh talked about uh robot controllers, and we have grand plans to do many more streams and video topics together. I don't know how I'm gonna find the time to do that, but I have a goal for this fall that I have to complete. And honestly, it was kind
Fall Plans
of a goal for the summer. I didn't even at least get started, but I want to remake all my P5 beginner videos. And I might try to start that today. But here's the problem. I have like this I have this challenge for myself, which is that okay, let me put it this way. There's a kind of video topic that I'm very comfortable doing, which is just teaching a concept in programming and implementing it and kind of talking spontaneously about it. I feel this I don't know obligation. I feel this importance, but maybe I really shouldn't. And I should just toss it to the side to at the beginner of these videos at the beginning of these of this video series which is uh all like little mini tutorials in P5 to do uh give you some background what is creative coding and its history up until P5. So, I've been working on some slides to cover this in a sort of short hopefully 10 or 15 minute way, but they're not done. So, I feel like can I really do the I just pulled a muscle in my neck, I think. And I know the lighting is kind of off. I'm just I don't know. It's not terrible, but um one thing that's good here just to show I want to make sure this is working is if I come over here. No. Come on. Ah, why is this not working? Shoot. Uh, okay. I'm back here. Uh, people are talking about the YouTube views being down. That's not really my problem. I understand. I We could go off on a tangent. I I've been following a lot of people talking about views being down, but my issue, my views are down because I'm not making any videos. Uh, but anyway, ah, okay. Okay, let me back. We have an issue though that's going to have to be fixed. I'm going to finish it. I only have three more minutes. Okay, so I want to do this. The other thing is there's this whole thing where there's all this AI stuff and I feel like I need to talk about that and have a point of view around it in order and I mean that relevant that's relevant to everything across my channel. So, I actually was hoping today to spend my live stream covering a lot of this stuff, but didn't really finish these slides. I don't I'm um got this cold now. The setup is still I'm kind of getting used to it even though it's the same setup I've been using for a while, but some new stuff here. So, I think we'll see. This is not what I'm going to start with today, but I wanted to talk about this. First of all, if anybody is interested in helping with these slides, uh, join the coding train discord and give me a tag uh, at wait the codingrain. comisord. Press a button, the URL comes up on the screen. It's not happening because I don't have that feature right now, but um, that would be welcome. Okay, put this over to the side. I think that's actually So, um, all right. I need to
Technical Difficulties: Whiteboard Setup
fix an issue. So, please, it was working earlier this morning when I was getting everything set up and now I don't know if it's like a simple issue or a complicated one. So, uh, please I'm going to please bear with me for a second. Something very important here is I am hoping the point of doing this is uh all sorts of interesting questions um in the chat here. Come on people. Okay. Uh all right. Um let me see what's going on. I need to No, it ah the camera source is correct. Okay. I think there's a small issue if you will. I'm just going to work. I'm going to try to What I'm trying to do is make sure I am recording the direct feed of what I'm drawing on the whiteboard to disk. So, um let me come up here. Um just check something. Okay. Oh, nope. Okay. So, that's that. And that's not okay. Um, I'm going to I don't know how to fix this. There's a few things I need to figure out here. I'm sorry, everybody. Let me just put on some music for you. One moment, please. Um, all the sources are correct. So, there's a scene here. Sorry, I'm going to show which camera it is. Don't understand. Oh, wait, wait, wait. I might just do this manually right now. Hold on, everyone. Let's just try something. I know it doesn't show you anything. I know it's a black screen right now. How do I tell it which camera to use? No. No. Cancel. Don't. That's not what I'm trying to do. This is Ah, there we go. I got it, everybody. Okay. Now, the question is, I go here. How do I switch this one? Oh, unlock. Ah, it's locked. I see. Okay, we're almost there, everybody. Okay, now. Okay, I think I'm good. Okay, me talking to you. Me showing what's on my laptop talking to you. I don't know what that little interlude in me standing in front of this whiteboard talking and drawing on the whiteboard. And finally, the direct feed of this whiteboard where if I'm over and actually drawing on it, oh, that's the eraser. Uh, it live animates. Fantastic. Okay. So, I'm reading some of this chat. Um, this is an interesting question which I will address. Uh, I know coding train the comments or layout is off. Generally only covers creative coding topics, but you reckon some sort of networking topics could be covered as well. Yes. I would like to do some I was like this is a good question I will answer it and then my mind went to a blank and all that popped in was yes. So actually I think the reason this came up this question came up let me bring this question onto the screen is um there's a bit little bit of a competing I have some competing interests here and what I'm really hoping to do with the coding train and I'm struggling with this mentally time management wise technically um is once a week cover on the coding train the different topics that I'm doing in my actual classes um at NYU and You might be wondering, so you know, just as we're getting started here, you might be wondering like, what do you mean at NYU? So, there is a program in NYU. It's part of TISH. It's called ITP. That is where I work. That's my full-time job. I teach classes there. The one of the current class um that I'm teaching is an intro to P5 class essentially. Uh um you know, I could say more about it, but that's ultimately what it is for total beginners learning to code with P5. And then the other class I'm teaching which is what will form the subject of today and this is um let me see if this programming from I just trying to memorize a URL here. There we go. Okay. So oh and I my pinned repo is off but here is a class that I'm teaching and I think I'm going to scooch this over just a wee bit here. Um this is a class that I'm teaching. Uh you can read all about it in the syllabus and uh one of the topics for the class is on text analysis and many of my videos which are on this syllabus here you'll find about associative arrays and word counting. I did a coding um a word counting um coding challenge and I talked about this other system called TF and I mean I've been teaching this class for a really long time and many years ago I made a lot of videos for it and many are they're kind of out of date but the concepts still hold true they kind of work fine but I never ever got to make a video on basian text classification which is kind of a quaint topic now in the age of deep learning if that's even like the term deep learning is quaint I suppose at this point in the age of AI giant like echo dramatic effect um but by golly I want to do it so that's so you asked about networking but this class and other classes venture off into working on server side programming and working with different kinds of systems and APIs and I'm doing some machine learning stuff and I want to do a lot of stuff transfers are just too many topics. So, I'm trying I guess I think what's going to happen is I teach a lot of different things every week at NYU and I'm just going to have to pick out of the hat one thing to focus on my Monday. So, every Monday I'm going to be doing this live stream. Uh someday, some Mondays I might have more time to do maybe two parts, morning and afternoon session, get more stuff done. I think with this cold that's coming on that's kind of unrealistic. Um, so, um, and I appreciate that Yousef is saying to that you'd prefer if the sound was up a little louder. I I've gotten that feedback. I wish there was a way I knew how to, uh, fix my settings right now. Right now, I would say like just turn your volume up. Um, okay. So, today's topic
Main Topic: Bayesian Text Classification
Basian text classification. So, in uh by at 11:00, I got to just be I can't have more than a half an hour of like futzing around here. I've got to be into that topic. But what I want to say is I feel I very much want to uh remake my beginner p5 tutorials. That's what I'm teaching this semester. So, um stay tuned about that and all the stuff I said before. Okay. Actually, let's just get let's get a move on here. Um so, One of the nice things I could make a new canvas, but I like that I can just kind of move this off to the side, which is what I'm going to do. Let's see. Let me title this rename. Uh I'm just going to make the date, which is probably stupid, but uh 15. And then I'll do uh Baze. Okay. just as a knowing what the Okay, so this is my whiteboard for base. Okay, now the other thing that I'm confused about that um is an important question. Is does this really make sense to do in the p5 web editor? Oh, look at me with my guest on the screen by accident. pressed the wrong button. Um, no guess today. Um, it doesn't really, but I don't feel in the in the trajectory of the class. I haven't really covered node and loading text files there. Um, maybe I'll just do a quick demo. We'll I'll sort of create the algorithm and make a um an interactive demo. Let me u and let me get this set up in a way where it will make sense. And um and I want to get rid of this and make sure the background is white. Uh okay. So, and how's this font size for people? Let me know. What is it actually? 28. I think I'm going to stick with that. Okay. So, I got to just rip off the band-aid and start doing some of the stuff. So, okay. The other thing I'll say is I'm hoping that this live stream works as a standalone experience that somebody could watch if they want to learn about basian text classification. And I should have said this right at the start. uh some point later this week, hopefully later today, even as soon as later today, there'll be time codes in the video description. So, if you are if you've been watching this whole live stream archive, you're like, "Can you please get to the various parts that I'm interested in? Go look for those time codes. " Okay. Uh somebody help anonymous because I can't uh with this very important question. Can someone explain what's going on new here? Not me. I can't. I don't know what's going on anymore. Uh but welcome and somebody will help you out in the chat. But I'm going to get started. What's going on right now is I'm about to build in p5. js a basian text classification web application and you're going to learn and the other thing I'm having trouble here because this is what I was saying is so this standalone live stream you should be able to watch. However, just like many years ago when I was a wei YouTuber who never thought that would be a YouTuber, um I would live stream and then we'd sort of chop out parts and upload them separately. That's the idea. That's what's going. This is well, let's see how it goes. Uh the goal would be there will be a edited version of this coding challenge that you could watch hopefully in a 20 to 45 minute maybe even up to an hour uh video that's going to um cut out all of the filler and uh wasted time speed through uh some of the sections as well as possibly have a little bit of extra annotated uh overlays. But um Matia, if you're watching or if you're looking at this later, I think the goal is like this just got to be done by next Monday. So, we're not going to do a lot of elaborate post-production. Okay. Hi, Carlos. All right, we got 200 people watching. I think that means it's time to get going. This is why I'm having trouble though, is like, oh, do I need to like how do I figure out to record an in? Do I like do I change at some point? I'm like, "Oh, I'm no longer the live streaming person babbling. I'm now the beginning of the coding challenge vid video person babbling. " I'm going to try to do very little stopping and starting almost none. Inevitably, something might go totally ary if that's the right term and I'll have to double back and repeat something. Okay. Thank you, Yousef. Okay. I I'm sorry everybody. I'm uh Okay. And the other thing is there's some lawn work, yard work going on that's kind of loud, but I think you're not hearing that. I think some of the sound filtering stuff. Did you hear it? Just a mower just went by the window. Anybody hear that? Okay. All right. So, let me Uh, there we go. Okay. Very faintly. Okay, great. Didn't hear. Okay, that's good to know. Uh, just give me a second. I was muted. Thank you. Yes. Yes. Muted. I'll wait for the chat to catch up. I forgot what I was saying. Somebody will have to read my lips. Don't worry. It's I fixed it. I fixed it. Got it. Got it. Okay. Okay. I was just saying how I love this topic, but I don't know it that well. So, we'll see what happens. All right, everybody. Hi everybody. Welcome to a coding challenge. This coding challenge is part of my programming from A to Z class. Oh, wait. Let's have this just up on the screen. Um, which Okay, remember I said I wasn't gonna start over. Okay. Uh, all right. So many good questions. I like I'm going to do some Q& A later before I leave. So, save your questions till there. All right. The thing is like I'm like we got to this point where I was recording videos without doing a lot of stuff on the screen and we were doing all that in post-production like recapturing web pages and I just can't do that anymore. So, but like my mind is still in that mode. So, I got to pretend I have to pretend as if the only thing that could ever be shown is what's here on the screen with me. And then if we have the capability of some of like moving some things around if we need it, but mostly don't know. Okay, let's just get to the good part because I got to write that B formula.
Whiteboard: Explaining Bayes' Theorem (Attempt 1)
Hi everybody. I'm making a video again and today I'm going to cover basian text classification which you might be wondering oh boy why is anyone going to watch this video well you're watching it so there is a topic that I'm really interested in it's definitely a quaint topic at this point that uh has been superseded swallowed abs totally overtaken by so many newer transformerbased deep learning text analysis, classification, generation systems, and I'll make some videos about all of that. But I think it's really valuable because you're going to learn so much if you watch this video. You're going to learn about probability. word counting and you're going to learn how to make a text classifier with your own data that you can open up, look at, and totally understand how it works. Run it in p5 js right in the browser. really quickly, really easily. So, um, so I guess I'm branding this as a coding challenge video. Uh, I have a programming from programming with text. I stopped and started. Stopping and starting. Just go. Just You're in a classroom. When you're in a classroom and there's students there, you don't stop. Like, let me take that again, students. I have a cold. My life is so good and easy compared to I don't know what, but it feels very hard right now. Okay. Um, uh, I've And the other thing is I could just talk and we could just like take stuff out. So, um, all right. So this video on some level is part of my programming with text series which hasn't been updated in over eight years but I think I'll brand it as a coding challenge. Uh so it'll just sort of stand alone as basian uh text analysis but it is part of my programming from a toz course at um which um a and part of the word counting module. So, you might remember seeing a video about counting words, about TF. This is kind of the next um the next step here. H what am I saying? See, I don't know. No, I'm going to keep going. Okay, let's see. Um that's not really important. All right, this topic really builds off of other coding challenges that I've made. The uh concordance coding challenge where I just count the to Let's look at that. Let's bring these things up. Oh, I guess I Let's see. Word counting. No. Why is my I really got to work on these tags. Uh, okay. I guess I can do it this way. Oh, wait. Oh, because it's in parts. I see. Oh, look at this old thumbnail. Okay. This is from on some level. This on some of this challenge is really, dare I say, a part four of my word counter in JavaScript coding challenge where I looked at how to take a text file and count the frequency of all the words in it. We did that in JavaScript. I did it in Processing. And then I also looked at this algorithm called TFIDF term frequency inverse document frequency which looks at the relative frequency of any given word across a collection of documents which might allow you to see a given word as a to see I my lost my no just talk it's fine what is term frequency inverse document frequency is an algorithm that looks at the frequency of words across multiple documents. So, for example, if I have a uh an article about uh curling, the Olympic sport of curling, and then I have an article that explains the physics of a rainbow, we're going to see the words like the and is very frequently in both of those documents. But certain other kinds of words like ice or stone might appear very frequently in the curling one and you know wave or wavelength rainbow would appear frequently more frequently relative in the other one. It's a way of doing keyword extraction. Another kind of classic dare I say uh I mean could that does it really count as machine learning? Maybe not. But it's a classic algorithm working with text that isn't a giant you know four bazillion trillion gillion bazillion parameter uh language model just to you know just the thing I don't like what I'm saying and so I just okay last time I swear but you know it's fine because I'm and then I swear I'm not. That's it. That's it for me. Choo says harp code. Thank you. Choo to you, too. All right, so this video really is kind of like a part four of my word counter series that I did. Can we find the date for this? If I click here, uh, — welcome to another challenge. It was only 20 minutes and it was eight years ago. Hey, this one only has Come on people, watch this video a little more, please. A 50K is great. I'm thrilled. Um, so, uh, but you can see in this video I covered how to count the frequency of words in a document. And I also did some other parts where I looked at the relative frequency of words in a document, uh, across multiple documents, which is a way of extracting keywords. Basian text classification is the logical next step. So where is a good starting point? First I want to tell you about Baze theorem. And I should say if you really want to learn about B theorem there are some excellent videos on YouTube. Uh there's a three blue one brown video find it. Uh — imagine your side project just by thinking about it. my side project to life. — The goal is for you to — This video is fantastic. I think there's a Veritassian video on base theorem. There's many more. I'll link a bunch in this video's description. I'm going to give you a quick chaotic overview in my own words and look at it specifically in the context of text classification. Give me a second here because the VI board went to sleep. Okay. Um, and I have
Technical Difficulties: Muted Microphone
muted. Wait, why did the mic get muted? I didn't press mute. How long did the whole Was it muted the whole time? Okay. Uh, I appreciate I when I'm at the whiteboard, I can't see the chat. I love my drawing there, though. Looks my whiteboard looks amazing. When did it start muting? Only when I went to the whiteboard. That's what I need to know. scene trans. Oh, hold on. Let me just Oh, because I had mute the mic was muted the last Oh, that's a I didn't realize it does that. Okay, that's fine. We're going to do this again. I actually felt I did that well, sadly. Okay. Not muted. Not muted. Not muted. Just checking. I'm not muted. Okay. I need to blow my nose. And I'm not going to mute the mic. Actually, I am gonna mute it, but Okay, I just got to make sure I'm unmuted. Still unmuted. Okay.
Whiteboard: Explaining Bayes' Theorem (Attempt 2)
Okay. In order to explain the Baze theorem, I'm going to create a scenario for you. Imagine a giant library full of books. And in that library, 1% of the books are science fiction out of Okay, that's right. Now, in all of those science fiction books, 80% of them have the word 80% of the sci-fi books have the word galaxy in the title. Now, I know that's probably unrealistic. A giant collection of sci-fi books won't have 80% having the word galaxy, but this is for illustration purposes. Now, in Why does it keep moving as I like I guess I have to like be careful about my body in this. Okay. Now, for nonsci-fi books, there are non-cifi books that have the word galaxy in the title. Non-ci-fi, 5% of them have the word galaxy in the title. So, the question is for you to think about to develop an intuition for. If I have a random book and the title has the word galaxy in it, what is the probability it is a sci-fi book? This is a question. This is a scenario that Baze probability theorem will calculate for us. Now, so we're going to use B theorem in a minute to calculate the exact probability number, but don't even worry about doing any math in your head. Just intuitively, what do you think the probability is? Pause. Take a minute, pause the video, think about it, I'll check the chat just to make sure there's no disaster going on. Okay. Okay, you got your answer. I mean, maybe a starting point might be this is the wrong answer. Oh, 80%. But it's probably not 80% because there are also books that are non-cifi with galaxies. So like 80 minus 5 and you could come up with all sorts of ways to calculate it or think of it. But let's look at how BA theorem does this. Now let me write B theorem. I'm actually going to move away from this for a second and just write it out for you with the original notation. Wait, where's my notes? I can always forget. B or A is where? Okay. Yeah. Okay. So, here we go. Here is B theorem. You're over there. B theorem is over here. This whiteboard thing is really in my way. First thing is what is even this notation? So this is standard probability notation. And once you've used it for a while, it no longer feels this way. But when you first use it, it might feel a little bit backwards to you. What this means is the probability of A given B. Actually, that's not backwards, but so I'm trying to think of a um I suppose if I wanted to read it in the forwards way, I would say this is the probability of a given b. Let's come up with an example. Let's say it's sunny outside. What is the probability that means it's summer? You know, maybe it's 30%. I don't know. It could easily be winter or fall or spring, but it's like a little bit more likely than a quarter to be summer if it's sunny because it's usually less sunny in winter. I don't know, but you get the idea. If it's sunny, what's the probability it's summer? That's what I mean by it being a little bit backwards. Okay, so in our case, what I'm saying is what if A book title has the word galaxy in it. What is the probability that it is a sci-fi book? Okay, let's go back to here. So now I'm going to have my other notes here. which I will just put. So let's write this formula again, but let's use G for the word galaxy is in the title and S for it's a sci-fi book. So what is the probability that if G is in the galaxy is in the title of the book, it's a sci-fi book. It is the probability of if it's a sci-fi book, Galaxy is in the title times yes the probability that it's a sci-fi book in the first place divided by the probability that a galaxy appears in the title at all. So a couple things to note here. Um, and I don't like Can I move something around? I don't like the way that I wrote that so close to there, but I'm gonna have to keep it okay. I just don't like having a no view into the chat. But, uh, but um I'm just checked it and it looks okay. Okay, we're going to get to some code. I promise. Okay. So, I also I think it'd be worth sort of labeling some things here for a second. Let me go back to here. Um, where did I want to make sure I get this right. My notes here. Yeah. Um, just heard a Discord message, which I don't sometimes that means something's important, but come look at it. Okay, so another thing that I think is let's just look at a couple u some let's look at some terminology here. This is generally referred to as the posterior. This is the probability we're looking to calculate. Um, and an really important piece here, the one of the things that really makes the Baze theorem tick is this concept of the prior probability. So, we've got the posterior probability. That's what we are looking to calculate. We've got the prior probability, right? If what are we looking for? What is the probability that the word galaxy appears in a sci-fi book type book title? No, no, no, no. What is the probability that if a book title has the word galaxy in it, it is a sci-fi book? Well, it that is entirely dependent, right? We picked a random book. What's the probability? What's the prior probability that this is a sci-fi book at all? Remember that was just 1%. That is a very important concept here. This is often referred to I think as the marginal probability. I like to think of it as like the evidence which I think is a term that gets used. What's the probability that galaxy appears across all books is a relevant piece here. What is this called? Conditional likelihood. No, no. This would be like the condition. Everything's a conditional probability. All of these are conditional probabilities. I hate doing this where I'm imagining the edit later. I have to like get that out of my brain. One way to get out of my brain would just be like not have an edit later. But this is Pra. First of all, I don't know if this is really like a video that anybody will want to watch later. So, it's sort of like practice. It's practice. Okay, I think this is often called the likelihood. Okay, so I wanted to just show you what is the formula, what are the terms and now I think in order to understand the formula and how it works, it would be worth illustrating it. so let's not even do the math just yet. Let's borrow from a much better video by three blue one brown and let me draw my own diagram of this library. Okay, we have this giant library. This is our library. What did I say? 1% of the books are sci-fi. So, this won't be drawn precisely to scale, but let's just say this little sliver is 1% of the whole library. Now, 80% of this sliver of sci-fi books, right? These are the sci-fi books. 80% of this, let's take this and shade this area here. 80% have the word galaxy in the title. Okay, 80%. Now, of the rest of the library, all of the non-cifi books, which is this whole extra area, this all of these non-cifi books, right? These are all nonsci-fi. 5% and again, I'm not going to get this exactly right. 5%. And oh, and I should use Can I undo? Dare I try a color? I don't even I can't even imagine using a color. That is the worst shading ever. But hold on. Can I do this and erase? Oh, no, no, no, no. Like a tiny. I don't I want to Hold on. Ah, no, no. Undo. Let me go back. Just excited to use color here. I made now I made this hard for Matio which is the whole point not to do this but I'm practicing. Okay. So this blue area all of the sci-fi books that have the word galaxy in them. Do you guys hear the lawn work going on? It's fine. It's very loud. You can keep that in. See, it's fun to keep those things in. It's so loud. Okay, now let's keep going. This little sliver are all the sci-fi books with the word galaxy in them. Now, remember 5% all this whole area here, these are all the non-ci-fi books. and 5% of them. Again, I'm not going to draw this precisely to scale, but let's say it's this much. And let's use a different color. Try red here. These are all the nonsci-fi books that also have the word galaxy in them. So, we have these everything shaded in with some color has the word galaxy. these this blue area sci-fi books with the word galaxy red so let's ask the question I'm going to pick a random book with the word galaxy is it more likely to be a non-ci-fi book or a sci-fi book well we can see even though like only 5% of the non-cifi books have the word galaxy there's so many more non-cifi books that's much more likely that it would come from this area and this is the whole idea of basian in probability. We have this sort of like initial piece of information that 80% of sci-fi books have the word galaxy. But once we learn the prior probability and more evidence, we adjust our probability. And that's what the formula calculates for us. Let's now work out the actual math. Hold on. This I guess this being here is kind of a problem. So I'm just going to erase it. So I should have started a new um literally like cutting all the grass out here. Okay, 11:30. That's not so bad. We're going to get to the We're almost through this part. Okay, so looking at this based off the geometry, I might guess like I don't know what's this like 15% of this area. I don't know. But we can actually do the math now. So I want to calculate given the word galaxy, what's the probability that's a sci-fi book? So the first part of this equation is if it's a sci-fi book, what's the probability? It's so loud the grass cutting. Okay, I have to pause for a second. We'll look at the chat. Oh, I'm losing viewers fast. We're reading the chat here. Okay, thanks for all your uh Okay, I'm scheduling having some scheduling trouble. Okay, it's also starting to get warm in here. See, I'm like turning beat red here. Okay, that B is getting dangerously close to me. I had to keep going here. Okay, the probability that a sci-fi book has the word galaxy in the title we've established was 80%. 80%. times the prior probability that any book is sci any book is sci-fi at all which is 1%. I'll wait. It's going to be done in just a minute. Okay, now we have this new problem which is what is the probability that any book has the word uh galaxy in it. So let's just do this with some intuitively and then maybe I'll try to write out some notation for this. Okay, so we have this whole area of books. we know uh what I'm looking for is what is the probability that any random book any book that I pick has the um uh sorry has the um well the the uh the lawnmowing went away and now I feel like my brain is lifted. What is the probability that any book in the entire library has the word galaxy in the title? Well, it is the all these are all the books divided by these are all the books, right? The red and blue area with the word galaxy divided by the total number of books. You know what would be really helpful here? I just realized is we should just use an actual number of books in the library. Ah, I should have done that in the first place. I can't really go back now, can I? But it's fine. Let's keep going with this and I I'm gonna wrap it all up with a specific scenario. Okay. So, one 80% of 1% of the books have the word galaxy in the title. Oh, look. We just did that. 80% times 1%. Plus 99% of the books 5% of 99% this is 5% of 99% also have the word galaxy in it. So, this might be a little bit confusing. How did I go from here to there? Let's actually look at a specific scenario, and I think this will help make more sense. Okay, now let's look at this library. Let's say the library has 1,000 books in it. This means 1% which is just 10 books. There are 10 sci-fi books. Eight with the word galaxy. Then there are how many non-ci-fi books? 990 nonci books. How many have the word galaxy in it? 5% of 990. I can't do that math. I mean, I could do 5%. I could do 5% of a thousand. That would be 50. Let's use a calculator. Oh, yeah. 49. 5. That kind of makes sense. Why do I have to have a half? I hate having I hate that the scenario has a half. I guess I need like 10. What if I did 4%. No, that's not going to help me. Uh, yeah. I hate that I have a half here. 49 because it kind of ruins it. Well, the answer is 49 and a half books, but you can't have a h I should have picked a different number where I'd get a whole number, but let's just I guess let's round that up. Um, we're to do an approximation. Let's see. I guess I could do um I could have said 10% and then we'd have 99. Galaxy is a very popular word in the title of these books. Anybody have a suggestion how I can like nicely resolve this question? 2,000 books. Make the total 2,000. All right, fine. I hate how the number is 49 and a half. So, let's do 2,000 books, which means I have 20 sci-fi books. 80% would be 16 have the word galaxy in it and then I forgot already 1% so 99% so 1,980 books then are not sci-fi books. And how many of those have the word galaxy in it? 98 5% should be 98, right? 99 you dummy. I mean 99. I'm going pause for a second to let anybody like correct me if I'm wrong here. 99. Okay. This means the total number of books in the library that have the word galaxy in it is 99 + 16 or 115. So, if I were to pick a book with the random book with the word galaxy in the title, how likely is it that it's one of these blue ones, a sci-fi one? It is 16. There's 16 of them out of a total of 115. 16 out of 115 equals I got to go to my calculator. Why do I have like a different answer? Oh, no. I have the same answer. 13. 9%. Boy, my handwriting is getting worse and worse over the course of this video. That is the likelihood that a random book which has the word galaxy in the title is a science fiction book. And I think you will see that this math that we did down here which goes along with this diagram is the same exact result of what we would get here which is uh 80%* 1% is going to be 0. 008 008 divided by 80% * 1% which is you know again the probability essentially um that a science fiction the probability yeah the probability book has the word galaxy in it relative to all the books essentially. I don't know if that's a nice way to say it. I don't think I need to say anything more. We've we've kind of done this. Just cut that part out. I don't uh plus 99%* 5% which is going to be well Uh zero. I boy, this is really hard because it's going to be how many zeros in the 49. All right. 0495. Yeah. Did I Oh, I put too many zeros there. I put one too many zeros here with the eight. 049 five. Yeah. Okay. And I think if we do this math out, we're going to get exactly this number. I'm pausing here for a second. I realize you probably can't see this super well. Just out of curiosity, let's put this here. This looks better. Did I have an extra Oh, the numerator. Oh yeah. Why' I put an extra um zero there? 8%. No, no. I'm right. 8 80% times 1% there's 0. 008 10% of 80% would be um would be 08. Yeah, it's correct. Okay. Now, why did I spend all this time fairly awkwardly trying to explain to you Baze theorem, its components, and looking at this example scenario. The reason why I did all of that is the following. And I'm trying to let's use the reason is it will serve as the basis for building a simple text classification web application. I'm trying to think of so I want to encourage you to use this algorithm and concept in more creative ways. But I think a standard way of starting with this would be sentiment analysis. I also think it's very important to emphasize that you don't just need to have two categories. uh is it sci-fi or not sci-fi for example but so let's just think about let's say we have a um we have this concept of sentiment analysis and I want to be able to determine whether some text document is positive neutral or negative Is it which one of these categories is it? What I am looking to calculate then is and I kind of want to zoom in on this a little bit. The probability that given Okay, wait. I think I just have to keep it smaller or move to the side or underneath it. Let's do underneath it. Yeah. What I'm looking to calculate then is the probab the probability given a text that it is in any one of these categories. So let's just say that it is positive. This is equal to guess what? All of that stuff that we did before The probability that a positive text document document contains that text. So let's put a finer point on it. Let's say that text is I am so happy. What is the probability that a positive document contains that text times the probability that there's a positive document in the first place divided by the probability that this text appears in any document at all. And so obviously this is a little bit different because I'm not just looking at one word, right? I could say what's the probability that a positive text contains the word happy times the probability of the word happy existing at all plus the probability of happy existing across all of the text in the entire known universe or at least in my training data set. This is what we're doing. We're actually doing exactly the same thing that we did with the sci-fi and word galaxy. The difference is my category is not sci-fi or other. It's positive, neutral, and negative. My word is not a single word. My text word galaxy, but rather a collection of words. But guess what? What we're actually going to implement is something called the naive bay theorem. It's not the naive base theorem, but I'm uh I'm what I'm actually going to implement is naive bay, meaning I'm going to take this sentence and chop it up into separate words. And then I'm going to say, hey, the appearance of these words are totally independent from each other. And I can use this concept of multiplying probabilities. What is the probability of two things occurring together? It's the probability of one thing times the probability of the other thing. Right? What's the probability of flipping a coin heads twice in a row? It's one out of four because two times one out of two. So essentially what I can do is I can turn these into this is hard picked our challenge. Here's my test video stream coding challenge. What I'm going to do is look at what is the probability that the word I appears in a positive text times the probability oops times the probability that n appears. in that positive text times and so on and so forth. So I'm going to multiply all these probabilities together to get that probability that a positive text contains all of these words times the prior probability of Hold on. Let me just look at my notes here. Oh, yeah. Times the prior probability of positive texts divided by and I'm going to do something funny with this later. So, let's just put a pin in that and come back to it. Okay. Any questions from the chat because now I'm ready to start coding. All right. Um, oh boy, you really can't see that when I zoom out, but that's okay because we have uh this. Okay. Um, come back to here. Okay. Yes. I wish. Okay. Let me fix this.
Live Coding Begins
All right, we're ready to start coding. Dingleberry, hi Dingleberry asked, "How will you get those probabilities? " Well, this is exactly what I need to figure out next. Good question. Here we go. Yeah. I almost What would be How would you guys feel like is there a way for me to do a poll? I used to be able to do a poll. Well, explained. I was like I was kind of like almost want to just go redo that whole thing. Now that I kind of like went through it, I could probably reexlain the whole thing with it fresher in my mind and uh be a little bit more cogent about it. I'm gonna Where? How do I do that? The poll thing. I mean, there's a way. Okay. Oh, I do it here. Is this how I do it here? Engage with your audience. Start a poll. Expl Oh, explain it again and see if it's better. Okay. Huh. This is fascinating to watch people vote on the poll in real time. I I should be able to I should bring it up to display it. This is like one of my uh white whales basian text classification. Um people are you know it's I'm happy to see this that you're all willing to kind of go with me and like listen to this again. But you should redo the whole thing but not now. That's not a choice. Uh, you should redo the whole thing, but just not now, please. Yes, that's not a choice. I'm very sorry, Palmira Media. Um, but uh, Maki is saying, "Oh, God, no, not you could. If you don't want to see me do it again, you just go take a walk outside, get a tea, you know, do something else. Leave this on in the background. Explain while coding. " I mean, you know, I got 39 votes and the votes are clear. People are like, you know, do it again. I mean, I'm gonna be explaining it while coding. gonna have to. But I kind of would like a more I don't honestly like the point of this video is like I would never have um I could never like expl I don't think that I could possibly first I don't have the skill to do this. Plus it's a totally different scenario because I'm doing it in real time off the top of my head. Uh thank you Melissa. Melissa is uh who's helped me with a lot of things. I take her advice very seriously. Um I don't think that I could ever um possibly explain it as well as like the three blue one brown video, but that's not the point. I want to have like my own like five to 10 minute version of it that can just get me into the code. Um so use 10,000 books. I think that's also that's good. and also better to explain it from so yeah so this was hard to understand let's try this again I kind of wanna I can't stop the All right yeah all right you all I'm going to let the votes go um but they're moving towards me doing this again which I think find fascinating um and uh now I'm going to what I'm going to do is actually make a new canvas because I don't want to erase that Uh, and I'm going to call it um, B 2. And did I spell theorem right? Yes. Okay. All right. Uh I'm sorry. I'm fascinated by your comments, so I'm just taking a minute to read them. 10,000 I think this recommendation for 10,000 books is a good idea. Um the thing is the the the important thing here is yeah that um I'm sorry I was uh the this live stream will always be available. So if somebody wants to if there's a later video somebody wants to go back and uh watch the whole thing. Okay, I'm going to end the poll because it's pretty clear um pretty clear result um that will now be there. All right, I think I lost about 10 viewers who were like, "Oh gosh, I'm closing this tab. " Uh all right, I'm also sniffly coding part I think won't be as hard. I should not say that. Oh my god, it's noon already, though. Crap. Okay, well, we're doing this. Okay, I could take I might take a short break and come back and do the code. I have a good fair amount of time, but let's see. Let's see what happens. Okay. Uh, hold on a sec. Okay, I'm not muted. Okay. I mean, I don't really need to do the beginning part again, but I'm going to anyway because I want to get my head into it and make it shorter because who wants to watch a long video? No, nobody these days. All right. Would code first help explain the theorem better? It might. That's a good point, Michael, but let me try. Hi, everybody. Welcome to a coding challenge video. This one I don't know. I'm gonna do it anyway. Um, this is really a part four of a bunch of videos that I made many years ago. Uh
Re-recording the Introduction for Edited Video
— welcome to a video — eight years ago apparently where I looked at how to uh count the frequency of words. Oh, this one here. I looked at how to count the frequency of words in a document. Did it in JavaScript. I did it in processing with some visualization. And then that leads to all sorts of other kinds of text analysis applications like you could generate the key words for a document by looking at the frequency of words term frequency inversely proportional to the document frequency. So words that appear a lot in a certain document but not across the others would be highly relevant to that document. Like if I have a the a document, I keep saying document is weird, but like if I have an article about the Olympic sport of curling, it's going to have words like ice and stone in them much more frequently than any random article I might pick out of a hat. But words like and, is, or those would be equally likely even if they're very frequent across many documents. So that was one example of taking word counting to the next level. The other example is applying B theorem. So I've got a really challenging task ahead of me which is to attempt to explain B theorem to you. Now the good news is you don't really need me to explain it to you because there are many excellent videos on YouTube. This would be I think probably one of the best ones if not the best one. The three blue one brown video on B theorem. I highly you know pause this. You could go watch that and come back. I'm going to give you my own explanation. So maybe stick with me and see how I do and go watch that later. But the point of this is not for me to give you the best most comprehensive explanation of B theorem, but look at how to apply it in the context of word counting. And the other thing, oh this is the syllabus page for my class, which is also relevant. I'll put all of these links in the video description. The the most re the the important thing though that I want to say to you however is you might be thinking what's wrong with you? Don't you know we have AI now and deep learning and all sorts of giant transformer models to do classification with text. Yes. And I would actually like to look at how to do that. And I want to cover things like word embeddings and text embeddings and how you can use that for classification and sentiment analysis all that. But this is a classic algorithm and I think it's such important foundational knowledge to these newer fancier systems that exist today. Not to mention the fact that I've got a p5. I've got the web editor here in p5. I'm going to write the entire basian text classification algorithm just in a little p5 js sketch in the browser. We're going to run it. We're going to load text into it. it's going to work. I don't need a GPU or a cloud server or some pre-trained model. None of that stuff. So, I think it's useful to look at this for those reasons. And, you know, maybe you agree, maybe you disagree. Let me know in the comments. I'm so happy I redid that. That was so much better. Okay. Uh, but I didn't do the hard part yet. Okay. So now I'm gonna go here. How's everybody doing? I feel good. All right. Um All right. So let me first just write out B theorem for you. Actually, no, I'm not going to write it out. Let's look at a scenario that's going to be relevant to text classification. Imagine a giant library. I'm going to draw it like this. And in this library, 1% of the books are sci-fi. That means 99% are not science fiction. I'm even gonna I'm going to give you some hints along the way. I'm going to borrow from three blue one browns geometric visualization with my poorly drawn diagrams. So these are all the sci-fi books. Obviously not drawn perfectly to scale, but that's maybe 1% of this big library of books. 80% of those books, the sci-fi books have the word galaxy in the title. I got to learn how to use colors here. How do we get the black? Okay. Now in the rest of the library, 99% of the books are not sci-fi. 5% of those non-cifi books have the word galaxy. So this is a scenario that we can use B theorem to calculate the answer to a given probability question which I'm going to ask right now. Given a random book that I'm pulling from this library, what is the probability? Oh, wait, wait. Let me start over here. But this I got confused. Given any random book that I pull down from this library that happens to have the word galaxy in its title, what is the probability that it is sci-fi? Pause the video. Think about what your answer might be. Now there are many famous scenarios that different I'm trying to think of. This is an example of a common kind of scenario that's often posed to people like there's um you can you I'm trying to think of what I'm trying to say here. I don't have the references in front of my head my in front of me. Now this is a again this is a very common kind of probability problem. I sort of made up a weird scenario here but there are more usual ones that people pose related to uh medical diagnosis or other kinds of uh scenarios where
Technical Difficulties: Camera Overheating
shoot. That's all right. It's just this camera going off. Good thing I caught that. Now, I'm using a kind of madeup scenario here, but if you start to research Baze theorem and look at other stories and now I'm just using a madeup scenario here. This camera, I think we have an issue. I think it's an overheating issue. So, I'm going to leave it off for a second. Oh, coding train is never. Things were going so well and coding train fell apart and went off the tracks. Okay, come back over here and uh use this camera for a second. Um, check the chat. Did I say something wrong? But, uh, I don't want to draw the red region yet. Okay. What do I do about this camera? We were doing so well. Wonder if there's a setting. This is the Sona Sony Alpha 7. I'm blowing on it to cool it down. We made it through that whole section. The problem is once it starts to shut off, camera needs a fan. Does indeed. I have a fan in here somewhere. Don't think so. I have a space heater. That's the opposite of what we need. I also could just come back in like half an hour. Pause. Is there like a setting on the camera? Hold on. Let's look. Uh, find the setup. Go to power setting option. Change the auto power off temp setting from standard to high. Run for longer durations before shutting down. What could possibly go wrong with this? Okay, let me try this. Uh, hold on. Let me put this on the screen here so I can see it. Okay. The thanks AI overview. I'm sure it's completely accurate and nothing could possibly be wrong here. Okay. Problem is I have to turn the camera on to do this which So I'm going to go to menu uh setup. I'm in setup and uh power setting option. Okay. Oh, I see it. I found it already. Incredible. Auto monitor off does not turn off. Auto power off temp standard high. The temperature of the device may rise to prioritize recording time. Would you like to change the setting? Okay. Okay, I've done that. Okay. All right. I'm just turning it off again. So hopefully this is going to help us. Wow. Okay. All right. We're going to see how this goes. Oh, and I'm in the wrong Okay, now I don't know what answer you came up with. This is a bit of a strange like madeup scenario that I may that I made up, but there are many common ones if you start to research base theorem and watch some of these other videos around medical diagnosis and other types of important scenarios in life where people just get have a really incorrect intuitive understanding of the probability of a given situation. here. If you were to be way off, one reason why you might be way off. I said I was going to stop stopping and starting and just do my thing. But um just give me one more chance here. I did a good job of not stopping and starting anywhere in there. And uh this the camera temperature thing messed me up. So that's my excuse. So this is a madeup scenario. I don't know what answer you got. Um, there are other scenarios if you research base theorem a bit more. I'll put more information in the video description around different kinds of medical diagnosis that people's intuitive understanding of how a positive test, a diagnostic test might really be uh mess up your sense of the probability that you have a given disease. No. See, I I wanted to mention this, but like any way that I do it is like awkward and weird and uncomfortable. So, I think I should just move on. But I'm I uh I'm going to move on. So what answer did you get? Now this is a madeup scenario. If you are interested in the resources I'm providing to you on base theorem, I'm sure you could find many other psychological tests and medical tests that Jeff Ben what are you even talking about? Okay. What answer did you come up with in your head? Now, this is a madeup scenario. I'm not really trying to trick you, but Baze theorem really comes up often as an example of how people's understanding and intuition about probabilities can be way off. And if you research it more in particular, you'll find about how doctors often get probabilities incorrect based on uh positive uh result on some type of diagnostic test. But I'm not going down that road. Let's stick with this. If you were to have gotten it wrong, you might overweight the fact that sci-fi books, 80% of them, which is kind of absurd. I mean, 80% of sci-fi books do not have the word galaxy in them. But if that were actually true, you might think this book has the word galaxy in it. The probability is like really high. I don't know, 70%. But it's not. And the reason why it's not is let's keep going with my diagram here. So remember this is the little sliver of 80% of sorry of one 80% of 1% of all the books that have the word sci-fi in it in the title. Now remember 5% of all of the non sci-fi books also have the word galaxy in it. So again, not drawn perfectly to scale, but let's just say, you know, Whoops. Whoa. Oh, it selected that. I don't want to do that. Go, go away. Unselect it. How do I unselect it? Okay, got out of there again. Whoa. Way not drawn to scale. Undo that. I mean, if this were 1%, that would be drawn to scale. This 1% is way too wide. So, I'm gonna I'm going to draw the 5% also too wide. Again, not drawn to scale at all. But presumably all of these books, 5% of all the non-cifi books, also have the word galaxy. So, if I were to pluck a random book that has the word galaxy in the title, it's got to be one of these. It's a much smaller chance that it's a blue book than a red book. What is the exact probability? Let's calculate it. And then we're going to go back and look how the baze formula is actually the formula for the calculation I'm about to do. So, I'm gonna uh move some stuff to the side here. Going to shrink this a little bit even though I like how big it is. Whoops. Okay, let's say there are 10,000 books in the library. Total 10,000 books. How many books are sci-fi? 1%. 100 books. How many of those have the word galaxy? Have the word galaxy in the title? 80%. 80 books. 80 sci-fi with the word galaxy. Okay. Now, how many nonsci-fi books have the word galaxy in it? Okay. 5% of 10,000 is 500 books. No, no, no. Oh, not 10,000. Ah, so remember we had 100 books and 80 of them. So we need 5%. Let me do this again. 10,000 books, 1% are sci-fi. So 100 books are sci-fi. 80 of those books then have the word galaxy in them because that's 80% of 100 sci-fi books. Perfect. Now, how many non-cifi books are there? Well, 99% of the books are not sci-fi. So that's 9,900 nonsci-fi books. 5% of those I wish I made it 10%. 5% of those non-cifi books have the word galaxy in it. So how many of those? 10% would be 990. So 400 and 45. No, 495. 495 of those have the word galaxy in it. We're going to lose our drawing for a second, but that's okay. So, what that means is if I pick this random book with the word galaxy in the title, what's the chance that it's one of those 80 and not one of those 495? Well, it's 80 divided by the total number of books that have the word galaxy in them. 80 plus 495. And this equals, because I did this math earlier before I got here, uh, this is going to equal about 13. 9%. Let me just double check this with a calculator. Okay. Yeah. Okay. So, we worked out the scenario a little clunky, a little awkwardly. You might want to pause. go back, do this yourself on pencil and paper, but hopefully it kind of makes sense to you. Okay, I get it. Like, we figured out what's the probability that a book with the word galaxy in the title is sci-fi based on this scenario. We actually used B theorem here. I just never called it that and I never used any mathematical notation. So, this video really isn't about the mathematical notation and the theorem itself. But, let's double back and see how that let's see how it actually is the same thing. So, I'm going to just move this completely off and I'm going to write out B theorem to you for you. Where are my notes? Just to make sure I get it correct. Okay. Yeah. AB AB. I always don't know why I can't remember that. Okay. So, first of all, what is this notation? This is standard probability notation. It's a little bit confusing. What it means is given the given b what is the probability of a? So I might say like um I uh given I just heard thunder, what's the probability it's about to rain? So B would be the event of thunder happening and A rain. So we're looking in this thinking about event probabilities. So it's you could sort of think of it backwards, but you could also read it left or right. What's the probability of A given the existence of B? So in this case B would be uh given the word galaxy being in a title of a book, what's the probability of a that it's sci-fi? And BA's formula is well it's equal to the probability of B given A times the probability of A I think yes of course A divided by the probability of B and this actually makes total sense because that's what we just did basically here we did it with actual numbers of books but it works out to say like Oh, what is the probability that a sci-fi book has the word galaxy in it? Well, that was 80%. Times what's the probability that it's a sci-fi book in the first place? Oh, that was 1%. Divided by Oh, we have something weird now. What's the probability that galaxy appears in a title of a book at all? Well, it's the sum of all the sci-fi books with the word galaxy and all the non-ci-fi galaxy. Well, that's what we did. But we could make that a probability formula. It's the probability of a book. It's the probability that a sci-fi book has the word galaxy in it plus the probability that a non-ci-fi book has the word galaxy in it. Right? That's all of the books, the non-cifi and the sci-fi total. What's the probability that any of them have the word galaxy in it? I believe if you do this math out now, which was BA's formula, you will get also 13. 9%. So, a couple notes about this. the real the sort of key here, you know, is that we're this uh so some terminology which I think could also be useful just for the sake. So in thinking about this there's a really key term that's essential to basian probability and it's this idea of prior probability and that's really where people will often sort like not have an intuitive understanding of what the prior probability is really where people get what can um people will often forget about when trying to sort of guess what the probability of a given scenario is. So in this case, like you can be you might be thinking like, well, 80% of the sci-fi books have the word galaxy, so it's just really likely. But if there's such a small chance it's a sci-fi book in the first place, then it's kind of unlikely it's going to be sci-fi. Uh there are other important terms here. Uh this is usually referred to as the posterior. you know uh these are conditional probabilities this syntax here uh what's the probability of a given b um what else I put in my notes here uh this is sometimes referred to as the marginal probability or I like to think of it as the evidence and that's really kind of what we're I guess this is and that's really what we're I don't know if I need this part but Um but uh but this is really the idea of base theorem. We are adjusting our probabilities given the existence of new evidence. Let's forget that. I think I'm good. Okay. So I'm going to move to writing the code in a second. But this is actually the core concept of there's a bee. Is it about to f Are you going to see it on the camera? No. My god, it's flying right above me. I really wanted it to come across. There's that bee. I'm just going to pause and look at the chat here. Make sure I'm not muted or anything. Uh, okay. All right. I think this is much better for sure because it's more succinct. Okay. So we have to remember why we're doing this and um one of the original articles that proposes basian probability for text classification although no this is not I don't want to say it that way like okay so I'm actually doing text classification here what I'm saying is I have a book it has a lot of words in How can I classify this book as sci-fi or not sci-fi? And it doesn't have to be uh a uh I don't have I I can do this without only having two algorithm and this and actually like saying sci-fi or not sci-fi is too limiting. I could say like okay I have this book it has all these words in it based on the frequency of all the words in the book. What's the likelihood it's a romance novel versus a thriller versus sci-fi? This is what I want to do. And we can actually use the word counts um in a bunch of existing sci-fi books and existing romance books, calculate all those word frequencies, apply them with this formula to classify new text coming in, and that's what I'm going to build into the code. I could keep going with diagramming this out. I might have to come back to it as I'm writing the code, but let's stop there. The one thing though that I do want to mention is that what I will actually be implementing is known as naive bay. And what do I mean by that? So, let's say the word the phrase um let's say instead of just having one word, I was going to say long ago in a galaxy, right? So, obviously I'm kind of getting this slightly wrong if you're thinking about the given pop culture reference that I'm thinking of, but the idea here is right, forget about it being at a title. We're looking at all the words and the number of times they appear in a given book. What I'm want what I'm trying to figure out is given all this is my variable txt. Well, let me fix that. Given my variable txt, given this text, what's the probability that this book is sci-fi? What I'm actually going to do is chop this up, whoops, long ago in a galaxy. I'm going to split it up into multiple words. And when I start to do things like, well, what's the probability that a sci-fi book contains the word long? I can chain multiple events together, right? If I want to know what's the likelihood I'm going to flip heads of a coin twice in a row, well, once in a row is one out of two. Twice two times one out of two. One out of four times. And I can do the same thing. So the probability in my basian formula which I'm trying to figure out this whole block of text, which category is it? I can chop it up into words and multiply the probability of each individual word appearing in that category together. That's what I'm going to do in the code. Okay, everybody, we did it. I did the whiteboard explanation. Um, there's so many interesting things in the chat. Astro says this isn't how you would typically do text classification. Um, so I also just want to mention so on my syllabus there I would also recommend um if you're looking for more background reading a plan for spam by Paul Graham you know that's from 2001 post describes a applying everything I'm talking about to spam detection. And what's really powerful is it is not based on some universal world of what makes a spam email for anybody. It's an algorithm that can be specifically tuned to your own emails. For example, I get a lot of spam emails maybe that have the word mortgage in it. So the word mortgage appearing in an email might make my uh message very likely to be spam. But if I were a mortgage broker, that wouldn't be the case. So, we've got to count the words and look at their probabilities of appearing uh for any given individual case. okay. So, that's a great article. I encourage checking it out. and some of these other uh videos and things again all linked in the video description. Okay
Coding Resumes: Building the Classifier
I need some data now. I realize I have a problem. Also, good note. I think that chat is kind of reminding me. I'm just going to turn the whiteboard camera off. and I'll let it kind of cool down. Okay, I think I'm going to do I mean I could get chat GPT to do this for me in two seconds, but I really refuse. Okay. Oh, let me Yeah, this is fine. Yes, I know it's a very small amount of data. Okay, in the spirit of this being just a toy demonstration of the concept, I'm going to hardcode some data here. Uh, ideally, I would like to load much larger uh bits. Okay, in the spirit of me making a toy demonstration that just implements the algorithm and runs very quickly and easily in the browser, I'm going to hardcode in a very tiny amount of data. For this really to be interesting and to work in any meaningful way, I would need to load much larger amounts of data from text files. I might even want to move this to like a server side code to manage the loading of all that files. I'd be thrilled to come back and talk about that or demonstrate that and include some examples in that direction. But for now, I'm going to do it this way. Some notes. Where's my other paper? I guess it's here, right? Docs per category work. Okay. The other thing I need is a big empty JavaScript object which will store all of the various counts of all the words across the different categories. Okay, so this is my empty JavaScript object that's going to have that in it. Okay, so the idea is and now that I think of it, maybe I don't need these arrays to do this in such a hard-coded ways, but I want to say something like classifier train. And I'm going to get this sentence. I am happy from this array of positive data. And I'm going to train my classifier basian model with the category positive. Let's take out this autofresh. It's trying to run my code. And um it's not an object. I'm not making So I also should make like a class. Maybe I will. Let's do this. Forget about having it be an object. I just like called a function. I'm like my brain has moved 10 steps ahead. Let's put all of this into another file. We're going to do all this in setup right now. Okay. And my classifier object uh needs to store a bunch of things. It maybe should have a list of all the categories. I don't know. And it has should have a list of all the unique words. Again, I might not use all these things. I'm just kind of literally doing this off the top of my head. Um, and then I need to have the word frequencies. So, I'm just thinking about how to do this. And the chat is saying I could use a set or a map. There are sophisticated JavaScript data structures that would be useful here, but I'm just going to use plain vanilla objects. They'll work just fine. Uh they might not be the most efficient. Um but I think I'll be able to explain and show what I'm doing best that way. Okay, it's going to be an object. Okay, I think I've Let's just start with this. Then I'm going to have a function called train. It gets some text in. The first thing I'm going to do is split that text up into words. I have a whole set of videos about regular expressions you could watch, but essentially I'm going to split by anything that is not a word character, letter or number. And the way that I do that is backslash capital w plus. Um, that should split everything up. Then I uh and I also I'm going to say do I just say lowercase or too lowerase? Uh, JavaScript string lowercase is the name of the method I want. I'm just going to make everything lowercase and not worry about that. Okay. Now, I'm going to go through all of these words. Oh, I'm going to need the total count. Ah, okay. I got it. I got it. Let word of word frequencies. And I might need to rename these variables. They're not the right. No. Word of words. Okay. First, I need to check is this word part of have I counted it before? If this word frequencies word exists then this wordword frequencies word. count++ count plus+ this should be the count of the word across all the documents and then I need to check if this word oh this is okay we need the else here if it doesn't exist this is fine let's do this then the count then it's the first time so this is me this is my standard word counting algorithm and again all sorts of other ways you could write this. Just trying to be verbose and simple about it. So if and I know I've spelled frequencies wrong in a bunch of places. If I found this word before, increase its count. Otherwise, if I haven't found it before, start its count at one. Now if I found it before I also need to determine if this word frequencies uh word category exists right if it exists for a given category then I also need because I need its total count across everything and its category and its count per category. Again, one could be extrapolated from the other, but let's store everything right now. And I can't seem to spell frequencies. Word frequencies word category plus+ increase it. Otherwise, it equals one. And if I haven't found it before, I also not only need to increase the start the total count, but start the count for that category. Again, redundancies, efficiencies aside, I can't wait to hear all of your comments about how to write this code better. I think this will work for my purposes. And again, I don't know that I actually need these separate lists of the unique words and the word frequencies. We'll get to that later. I love seeing this done by hand. Oh yeah, by hand versus Python tutorials that just import NLTK. That's comment is making me very happy. Okay, now I just want to see and I think actually forget about these arrays. Let's do this in a very silly way because Oh, and let's keep the erase. I just they're bothering me up there. Okay, I just add some line breaks. So, um All right. What I'm doing now is I am just putting in some examples and I'm going to console log the classifier and let's take a look at what we get. Okay, what new? Oh, I forgot to add classifier. By the way, I'm using Oh, I forgot I have this on screen here. Um, okay, it's fine. This can be This could be sort of like skipped to. Okay, so I'm just very briefly putting in three one sentence from each of those hard-coded data sets into the train function. And then I'm going to just look at the classifier. Um uh and I need to make sure uh I have class add Okay, yeah, I add classifier. js to my index. html file. And by the way, I'm using um p5 2. 0. I'm not using any features of p5 2. 0 in this particular demonstration, but I'm starting to put that as my version of p5 in everything I do. And you know, stay tuned and find all the videos on my channel about p5 2. 0 that may or may not exist yet. Okay. Uh, setting count. Oh, well, what am I missing here? Oh, okay. I see. I can't just make up a property where there's the value of word frequencies word was originally null or undefined. So what this actually needs to say is equals count like that's me in creating this initially and the same thing I could just put the value in there. Uh I see. Do I want a count or do I just want the number? You know what I I'm doing it I don't think I need the property count. So let's actually set it equal to one and then there's no need for this count property. I'm just increasing it. That's what I did in the first place. Yeah. Yeah. There was I only used count in the top. This is now correct. I could put a whole object there with the property count equal to one, but I'm just going to store the value one. I might regret that later. Category is not defined. Oh, no. I do need an object because category is then an object. Okay. So, this is now going to be an object with the count as one. So, count goes up. And then this could be boy, am I doing this right? Should it be category word? I don't even know. This might all be a mistake. This is why this video is going to be two hours long. Um, now this should be fine. But maybe to be consistent, I should do this. And then I should use dot count here. We do not need the canvas at all. Maybe I'll use this is why I shouldn't be using the p5 web editor also, but it's fine. Uh, oh, sorry. Uh we're going to use count everywhere. Okay. So now just to cover this again, this is this makes this probably makes your head hurt because it makes my head hurt. We're going to see the data structure that I've defined once it console logs correctly and your head will hurt less. That also needs to be a new object. Jeez, how many times can I get this wrong? Yeah, the else is wrong. If this word frequencies word exists, then increase the count. Check if it's a category that exists and increase the category count. Otherwise, set the category count. If it hadn't existed, people are saying line eight. I don't see line eight is just train Oh my god. That's why you're saying line eight this whole time. Ah, I'm passing in the text and the category. There is no category. Where do I get the category? I get the category here. Okay, now we're getting somewhere. If the word frequencies word exists, then okay, dot count does not equal this. Okay. Uh, okay. This dot count should not be here. Okay, I've got it. Now we can look at this. Look at word frequencies. Every single word like let's look at the word m. It is a total count of two times. In a positive text, it appeared once and in a negative text it appeared once. All of that work was for me to separate uh all of the data, the input data into a giant list of words. know the total amount of times that word appears across all documents as well as its individual counts for each category. Great. So let's now fix now that works, let's actually do this for let um you know uh data of positive data. I'm going to do it this way. Um again this is very inefficient but we're just going to do this let data of positive data train positive data of negative data train negative and data of neutral data train and neutral. Let's run this again and take one more look. Okay, the is in positive once, negative ones, neutral twice. Awesome, by the way, is in positive ones. It doesn't have a zero for the other C categories, but that's fine. we'll be able to determine its zero by knowing that it doesn't exist. Okay. Now, the next thing I need to do is I need the results of classifier. I don't know what this means. This error message that I just got is very bad, but I'm gonna just assume everything's okay because I don't know what else to do. Okay, I see the chat but okay. Now, now what I need, I need to classify a new phrase. Just looking at these, let's make something up. Okay, so I need a function that's going to take in a new phrase and calculate that final probability of uh for each of the categories according to B theorem. Uh by the way, it's almost 1:00. I'm losing steam, but we're going to get through this. Uh, just give me a minute here to turn the whiteboard back on because I think we're going to need to come over to there. It's funny all the ambitions I had of doing other things today. Okay. Oh, this camera is off. Let me just put this picture on the screen so we have it just in case. Okay. So what do I need to do looking at this formula? I need to the look at every word in the text that's coming into my function to figure out um it's probability. Okay, wait. Hold on. So what do I need to do? I need to I have some string. Okay, remember I have some input text. It's got a whole bunch of different words in it. So what I need to do is look at those words one at a time and apply Baze rule. I need to say like okay if it's a positive category how likely is that word long to appear times I don't know why I didn't finish this before the probability that uh the prior probability of the positive category existing at not existing at all. Times the prior probability for the positive category. Okay. So, we've got a new classify function. I need to chop it up into words. I also need a object called results. And what this is eventually going to contain is the final probability for each category. Um, oh, I'm not keeping the total words in the category. Okay. So, what is the probability that a given word appear given a category? How often does that word appear? I'll call that the word probability. Okay. Oh, I think I need Okay, I need to keep track of some other things. the category counts. Let's do that separately. Okay. So, if this do let's do uh I've got an idea. Hold on. I'm thinking through this. I need more information for my probabilities. I need to have the total number of documents. That's just I need to know that's going to help me with my prior pro probability of how what's the probability that a document is positive at all. And I need to have category counts which is the total number of words in each category. So, do I need the No. No. The total number of I do need the total number of words in each category. I picked such a hard problem for today that I'm like struggling here. It's hot. I've been doing this for hours now. 10:30, 11:30, 12:30. Oh, two and a half hours. It's not That's reasonable. Three hours is usually my complete limit. I haven't taken a break. I should really take a break, but let me map out what I need. This is going to help. I need to know total docs the total amount of documents. I need to know the total docs per category. That is what I need for my prior probability here, right? I need to know what's the probability that any given document is a given category. So that's what I need. Uh Okay. Now for words, I think I have what I need for words already. But I have the total number. Ah, I need the total words per category. That's what I'm missing, right? Because for the words I don't I actually don't need the total word count. Okay, this is what's going to get me this. In order to know what's the probability a given word is in a given category, I need to know its count. This is for a given word. I need to know its count per category. And then I need to know the total words, total all words per category. This is something I'm not storing. This is what I don't have in my code yet. So I need to add that. I don't know if this makes sense to you, but bear with me. Let's go with this. So every time I talk every time I call train the total documents goes up by one. If the category counts category exists already then and I'm just going to uh I guess I'll do my count is one no increases otherwise this is me just counting the uh frequency of the categories across the documents otherwise it equals it starts with a count of one. Okay, so this here this is for the prior probability. Now I'm keeping track of this. Now I have this count per cate. I have the words count per category that is right here. The words count. Okay, hold on. The words count per category. That's here. I also have the words total count, but that's not actually what I need. I need the categories total count. So this should be reversed. I'm just thinking about this. I would really like to have it category word because then I could have category count. Okay, I'm gonna rewrite this with this new way of thinking. The first thing I need to check is does the category exist? So, this is going to end up being the same code. I'm just rewriting it again. Does the category exist? If it does, the total count for that category goes up by one. Otherwise, is a new counter that starts at one. Okay. Now once we know the category exists I have to check if that word I'm just doing this in the other way has been found before in that category. Has that word category? If so, its count goes up by one. Otherwise, it gets a fresh start count. What have I got wrong here? What did I miss here? I can't see the syntax error. Oops. Does somebody see it? I should have taught basic P5 drawing today clearly, but I can't stop now. I mean, is it just like my variable names are spelled wrong now? Where's the bracket out of place? I know it's terrible, but I would happily clean it up if I could just see what I got wrong here. This is a great comment from DJ Mangus. Well, maybe somebody uh the problem with this is I don't know that uh why not just prepare a copy of a blank object with all the zero counts and that would work but it like requires knowing the categories in advance which is not a good generic way to write this but it's a very good comment. Nobody will help me. I'm going to have to help myself here. Okay, let's run the good question. Unexpected token classifier 48. Oh. Oh, the issue is I was doing more stuff down here that I forgot about. The syntax errors are below. So, let me comment that out. There we go. My code was right all along. Okay, let's just take a look. at the classifier with the new way I'm organizing the data. Okay. So now just looking under category counts I have three positive documents, two negative documents, two neutral documents, seven total. That's right. Word frequencies. Each word um each category is the root property. And under positive there's a total number of words in positive and m appears once. The probability of m appearing in the positive count is 1 divided by 15 which is exactly the math I need. Now we're ready. I have the pieces. Just to reiterate, that's the math I need to know how frequently a given word appears in a given category. So I both of these are the core probabilities that I need that map directly back to BA's formula. Oh, we are so close. Uh, okay. Clemen says, "If you ever have the word count, it will mess the count up. That's kind of a very smart comment here. I'm going to ignore that. that issue right now and come back to it later. Good point, though. Okay. All right. For every word I need the word probability. Ah wait wait wait. I need to um first do every um every category for uh and I have all the categories in category counts. Uh wait wait wait. So I actually need to get this list of positive, negative and neutral. Those are the keys to the category counts property. This is very awkward. I'm gonna show you. By the way, I've actually written a version of this that's I think much better, but I'm going to go with my messy style. We'll talk about how to refactor this later. Play cue the refactor song. So, categories equal and although I guess what I could do, you know what? Let's I have a better idea. Let's put this this. categories back in and you'll see and then when uh when there's a new category I will just push it into that array. So, I'm going to store my own list of all the categories because now I first want to do for you hear my stomach growling. For every category of categories, results index category equals some object. And now let's go over. We're going to do these. Uh what is the right or uh I'm not going to worry about the correct way to do this. I'm just going to do this a way that it will work. It will be redundant because now I'm going to iterate over all of the words. We need to multiply them together. So we're actually going to Start with a word probability of one and then we're going to say the word probability equals. So what do I need? I need the thisword frequencies for this category for this word divided by this dot category counts. No, no, no. Dot count. All right, let's do it this way. Let word count equals the number of times this word appeared in that category. Let category count equal the total number of words in that category. And the probability is and I'm going to chain them all together. The word count divided by the category count. That is the numerator of BA theorem. Actually, that's not the numerator because I also need to multiply the prior probability, but I'm going to do that at the end. I'm just doing I'm chaining all the word probabilities. I don't like this category word count. Let's call it that. So the word count the number of times this word is in the category versus the total number of words in that category. Then so this is P of uh A given B essentially then I need to multiply it by my prior probability of A which is the total uh the total category counts for that category divided by the total number of documents which is just this. Total documents. Oh no. Whoops. Hold on a sec. Okay. Uh, naive bay. I'm just putting some comments in. Multiplying all the probabilities together. Okay. I just want to finish this function. Get all the words results. Look at each category. Look at all the words for each category. Times the prior probability. Why can I not get my brackets right? Oh, there are more brackets down there. That's why. Okay, my brackets are right. So now the results for this given category is equal to the word probability. I haven't done the denominator yet. So earlier I talked about how I'm going to do something different with this denominator and you'll see that in a second. So I'm ignoring the denominator, but I've now calculated the numerator for a given category. So this is actually done. This is done. I chained all of the individual probabilities for how for um a word. Oh jeez, it's so hard to say this. This is done. Okay, this is done. Let's look at the results. Okay. Let category of categories. What's wrong here? This categories All right. What's the uh what's the category here? Oh, yeah. Okay. So, I need to uh there are going to be words that don't appear in a category. What if the word doesn't appear in that category? Well, I'm going to need to
Explaining Laplacian (Additive) Smoothing
apply something called llassian smoothing. Basically, what I want to do is consider every word appearing at least once. So, I'm saying here word equals word frequencies category word. count. I'm going to say or one. And I gotta do a little bit better than this in a bit, but and actually um yeah, or one. I'm actually gonna say plus one. Uh there's got to be a better way to do this. I don't know why after doing this for 10 years, I haven't learned the lesson that these like big complicated projects I um it's very hard to do them live and turn them into a video and over hours and hours I lose all my energy and steam. I don't know what I'm doing with my life anymore. Okay, we're going to make this work. At least that's going to be a success for today. Those of you who are sticking with me here. Uh, all right. I'm trying to think. Let's just let me just do this for a second. Um, just going to put these in here for a second. Oh, but if the cat wait hold on cannot read property of undefined. Hold on. Let's just console log. What is even the category here right now? Word, comma, category. What? Positive. Okay. Right. There's no what here. So, that's fine. But why shouldn't this work? This is also like this is where the p5 web editor cannot handle me doing this project. Like I just need a different way to like debug. So I I've also like bitten off more that I could chew here. What's undefined? Okay. So, hold on. All right. I'm going to debug this properly. Don't worry. I'm gonna comment all this stuff out for a second. Let's just see. Does this work? Yes. Okay. So, you know, I'm getting these frequencies for every category. Ah, cuz word is undefined. There's no count. I see. This is what's undefined. So, this is why I didn't want to have the count property. The dot count property makes this harder. Uh, yeah. So, I'm just trying to think. I mean, I obviously can use an if statement there, but I'm trying to avoid it. I'm going to use an if statement. I'm going to show you. I I wrote this code like a while ago, and I'm sure it's like much smarter than this because I did it much more thoughtfully. But, I'm going to do it this meth. We're going to get this working. You're watching this video. You were promised a working thing. I'm going to finish it. Okay, this is undefined, so we're going to have a um Okay, we're going to say the Okay, I have the Got it. I have the word count. So, the word count is going to be assumed to be one. And if this is defined, you're going to see this. I'm going to do some like crazy stuff here, but it's fine. What I'm going to do is say word count plus equal its actual count. I'm sure again there is a better way to do it. I think we can safely assume every category uh has words in it. So this is a form of leelassian smoothing which I will try to define more uh in a better way in a little bit just but let's bear with me. What I want to do here is basically assume like every word I'm got the words coming in some of I can't have zero because zero is going to break everything in all my math. So I'm going to assume give it like the smallest amount of probability if I haven't seen it before in this category. Let's just count it once and then I'm going to if it actually has been seen before I'm going to add in the actual count. And the reason why I'm adding in the actual count instead of just overriding it is I want to keep that one. Like if I'm adding one to things that were zero, I'm going to add one to everything else too. Okay, so this should still work. Now the leloian smoothing needs another step to it, but I think this might fix all of the things that broke. Okay, better. Total documents is not defined. No problem. this dot. Okay, now uh we've got this. And when we get to the end, return results. We got to return the results. Let's go to sketch. js. Console log those results. What's the other console log that's happening? I don't want to see now. Okay, here we go. Ah, look at this. I got scores. I got it. 42% positive, 28% negative, 28% neutral weight. Those don't add up to 100%. Okay, I haven't done the denominator yet. But I also haven't finished the leloian smoothing. Let me But we're like I'm like five 10 minutes away from being done in this 472 day long video that's been the longest video anyone's ever made on YouTube. I'm just My canvas went to sleep. Is my whiteboard camera still alive? Okay, remember I am trying to calculate given a category. What is the probability that a word exists in that category? Hold on. I think I zoomed out too much. to see this stuff a little bit thicker. Okay, it's fine. I don't know what I'm doing. Okay. Oops. Okay. Given a category, what is the probability that word appeared in that category? It is the total word count. See, total word count is I don't like the way I'm explaining that. It is total count for W. It's how many times did this word appear plus one, right? That's my smoothing basically essentially saying I can't have any zeros divided by the total count for all words. Well, if all words if everything if I'm adding one to all if I've added one to the count of every word that appeared in that category then I need to add the total number of unique words that appeared in that category to the total, right? The total count is off plus uh total unique words, right? This is essentially an this line is uh Okay, hold on. Boy, this uh small eraser really makes things hard. Okay, back to this. Okay. So what I'm doing is I'm saying I have the word happy and happy count plus one and the probability happy appears in a given category is divided by the total words in that category. But if I'm assuming every word appeared in that category one more time than it actually did, then the total words is not correct. I have to actually also add the total unique words. Basically, I've added one to everything when I'm calculating the probability. So, I just need to increase the total to reflect that. Now the question is am I storing and that's this category word count here needs a needs I need to add the total number of unique words that ever appeared in that category. I think I have that. This is the total number of no that's the total number of that's not the total number of unique words because that includes the word appearing multiple times. I should put it here. Oh, or I could put it in here. Oh, count. Category counts, positive unique words. I could do unique words here. So, let's see here. When do I know I found a unique word? The moment I add that word to the category, I could say, where did I say I was going to add it? Category counts count unique words positive category unique words. So I could say this dot category counts unique words no category unique words plus+. However, if it never encountered it before. Ah, this is it here. Count one. Oh, yeah. I think the category counts already exist. They all They already exist up here. That's the first time I found a word for that category. I think this is right. The keys are the unique words. Shouldn't it just be words. length? So again, I could get the keys. Maybe that makes more sense. I'm just trying to keep track of everything in the data structure. But you're right, I could just iterate over the number of keys here, but there's other stuff going on. So, I'm going to keep track of it. Okay, let's just look and see if this makes sense. Forget about the results for a second. Let's just look at the classifier. Okay, I've got three categories. Positive, negative, neutral. For the category counts. Why is this camera overheating? I've been doing this. I think this camera is now overheating. Insanity. Or did the battery die? It's plugged in. One thing I do have is extra batteries. Hold on a sec. It might be the battery. Shouldn't be because it's plugged in. I'm going to replace the battery. This battery should be charged. I can't get this battery to go in this camera. Oh, there we go. See if that fixes it. I'm guessing it was the battery, but I don't know. Okay, I need to be reminded about this. In classifier, you're missing the line to update the probability for each word, but I can't look at that right now. Okay. For each category, I have the total number of documents and the total number of unique words for every word for and then in a so these category counts and word frequencies do not need to be different objects. I'm realizing because you can see look they have the same initial properties and then they have count and all the words. So this could be consolidated but I'm going to leave it separate for now. Here I have the total number of words across the category as well as the total number of times each word appears. Great. So I have everything I need. The only thing I need to add now is when I do this final calculation. Oh. Uh, right. Where? Oh, I I took it out. Oh, okay. This error happened again, but I'm just going to assume it's fine. I must have taken out the original pro word probability uh calculation which now is equal to the word count divided by the category word count. Now the category word count needs the smoothing. The word count as the smoothing by adding one to everything. The category word count needs the smoothing by adding the total unique words which is where that's in word category counts category unique words. Okay. So now I don't know what I'm doing here. I'm changing all the white space for no reason. Now we've got it. We've got the numerator which is uh times equal which is chaining together all of the probabilities of of a word appearing in a given category with leloian smoothing assuming if it doesn't exist let's give it a count of one divided by the total number of words that ever appear in that category. with the smoothing. Then we multiply that by the prior probability and we have the final results, the final probabilities without the denominator. That's the last piece. Oh, let's go back and look and see if the results make sense for what a fantastic and happy day. Okay. Well, these numbers are kind of impossible for us to look at now because they got much smaller probably with the smoothing that I added in. Okay, I think I've got fixed these
Normalizing the Final Probabilities
already. So, it's hard for me to look at these. But don't worry, the denominator is going to fix that. Let's go. Let's go back to the whiteboard for the very last time and talk about the denominator. Okay. I'm going to write this formula one more time and I'm going to look at my notes here. The probability Going to write this formula one last time. The probability that a given text means it is a given category. this. What's the probability this text is positive or neutral or negative equals the probability that category contains that text times the prior probability of that category existing at all divided by the probability of that text existing at all. Well, guess what? I want to do this calculation for probability of neutral, probability of positive, probability of negative for each for everything that we're calculating this number and this number is going to be different depending on which category we pick. But this is just the probability of this text appearing at all across everything. And so yes, we could calculate that. We could count up all the words in this particular text that we're looking to evaluate and divide it by the total number of words in everything we ever looked at. But this is just a constant. It's a constant for this particular piece of text that we're trying to evaluate. So you know what? we can ignore it and instead we can just normalize the values that we're getting out of the numerator because that's the point. We're gonna have to do that anyway. We're getting these scores which we want to normalize to turn into 80% 15% 5% that add up to 100%. If this is going to be constant across all of them, we don't need to bother with it. So that was what I was thinking about all along this whole video. I was like, I'm gonna get to skip that. So that's the exciting thing. So we're kind of done. All we need to do now is normalize these scores. Okay, so the very last thing we're going to do is before we return the results, I need to normalize the probabilities. So for let category of the categories I want the uh probability from that category and I want to get a sum to be zero. I'm going to sum up all those probabilities and then guess what I'm going to do? Just going to divide by that sum. I'm going to do this again. Again, you could use reduce or map or whatever higher order oneline arrow function way of doing that. Can't wait to see all of your much better code doing this. But I'm just going to run through this loop again and say results category divide by that sum. And now return the results. So this is me very quickly and easily normalizing those values. We're going to run this one more time. Ah, what did I get wrong? this dot categories. I think that's it. I really should not be using the p5 web editor for this. There we go. 85% positive, 12% negative, 2% neutral. Let's now put something on the actual web page. So, I'm going to say uh let um uh input or like text input equals create input. We'll put this in there. I'm going to do submit button equals create button. And let's put this stuff after we train the classifier. Then I'm going to have submit button mouse pressed uh and classify text. And I'm going to make another function. I'm going to do this in the most verbose, friendly, simple way. This is my event. When I press the submit button, I'm going to get let the text equal the uh text input value and then the results is the classifier. Classify that value. Let's just console log them first. No, let's not console log them. Let's put them on the screen. And let's make all of this. This is so silly, but I'm going to make these global variables just to clean this up. Let classifier. I mean, again, there's all sorts of other ways to do this. Text input, submit button, and then results paragraph. These are all my global variables. So, this is now a global variable. So, I have access to it. The text input, the submit button, and now I'm going to get the value. I'm going to put the results and then I'm going to say for oh the results is an object. So let categories equal results. Uh now I'm finally using objects. keys. I refuse to use this the whole way through but objects. If I have an object with like three properties in it, positive, negative, neutral, I can get them into an array by doing object. keys results. And then I'm going to say the uh output text. The output is an empty string. And I'm gonna say for let's see and I'm just going to say C of categories. Um I'm going to oh uh I'm going to output plus equal I need some text here. I need results index uh oh I need the category. Let's use a string literal C colon uh and then results of that category. And I'm going to multiply it by 100 and number format it. Look at all this. Look at all this I'm doing now. Multiply it by 100. Wait, I'm going to number format multiplying it by 100 to two decimal places. Who knows if what I did was right here, but this should be getting my text input, getting the results for my basian classifier, getting the list of categories, iterating them, putting them into what did I call it? It's result P, result paragraph HTML. Put that output there. Okay, ready everybody? Let's run this sketch. Can I How do I make this longer? Oh, this is going to take me an hour. Uh, text input attribute width 100. I don't know. Is that right? No. Attribute. How do I do this in p5? No. Pixels. No. Somebody know how to do this? I could use a text area. Oh, this is object. keys, not objects. Oh, why am I not using coil? I refuse to for this whole video, which makes no sense in retrospect. That's my new song that somebody will turn into a music video. text area. Fine. Create element. Uh text area. Will this do it? But then does value still work? That's the problem. I don't even know. Okay, that worked. Okay, fine. I'm happy now. Are you happy? Submit. Oh, what went wrong? Uh line 47. Something's undefined. Oh, I never made it. Uh, result P equals create P results here. Okay, let's try this again. Going to zoom in on this. Look at this interface design, people. And I know my green screen is all off. The camera got knocked because I was like changing the battery. Let me fix that. I mean, oh. Oh, it's this thing that's like loose. Oh, that thing's loose. So, it gets knocked around. Okay. What if result? I mean, come on. Does it get any better than that? Oh, okay. This is good. Why did my number format not work? And I forgot about Okay, so we need a line break. That's better. But number format. Oh, okay. Yeah. Two comma two. Do I need two things? There we go. Just Just for the sake of No, no. It's fine. I'm just going to zoom into it. Okay. Okay, everybody. Yeah, pretty pretty negative, I'd say.
Coding Challenge Complete!
Yep. Pretty negative, I'd say. Coding challenge complete. This might be the worst code I've ever written in a lot of ways, but I did explain it and I did get it to work. Let's take a deep breath. I'm not going to be spending any more time in this video than I need to right now, but
Reviewing a More Polished Version of the Code
probably should go to github. com/shiffman repositories. Um, maybe it's not here. Oh, it's in a toz. should probably go to program from A to Z repositories bay classifier. This, by the way, if we look at the insights here, well, let's just leave this. Let's look at the classifier. Let's take a look at this. Okay, this is my nicer version of this. Let's just have a little walk through of what's in here. Okay, word counts per category. Ah, that makes sense. You have the word and then each category has a count associated with it. That's one way. Category, the document count, how many texts for this category, the total words across all text for this category. There we go. Total number of documents. Vocabulary size. So that's something I kept as a separate property as opposed to like some kind of unique words. I just kept track of the total vocabulary size. That makes more sense. So when we get ah look at this there's an add word function train. So a word probability function and a category probability function. So separating these things out into separate functions makes a lot of sense because we can have all this code to just calculate a word for a category. We can have all this code for when a new word is being added to a category. So we can check does that word exist? If it doesn't, it's a new word. Increase the vocabulary size. Initialize the count for all of those words. Initialize for the category. Then the total word count. Aha. All this stuff. Train creates. And this is better. Creates this sort of empty document count. Word count. You can see splits it. Oh, I'm validating the words to make sure they're actually like a word as opposed to just some string of numbers I might want to ignore. That's interesting. Word probability. It's got the smoothing. Here's some explanation of it. Look at all this. So, I encourage you, if you somehow made it to the way to the end of this video, you've seen the sort of raw struggle of a man trying to make a basian text classification with only a very small breakfast and hours of time. This is a much more thoughtfully written version of it. I will also, it is my intention to turn this into a library that maybe you could use in Node. js and I might come back and use that in a future video if there's any interest. Okay, before we go, I got to do one more thing. I got to put something in this particular sketch with the word count in it. Now, is this going to break it? Yes, it broke. I don't know how to fix this. I didn't have the issue. The way to fix it is to use my other code where I didn't use the count properties. I guess what we could do is name all of these this. Let's do this. We're going to do a quick one way to deal with this. Not my favorite. Find count replace with unerscorecount. Won't that work? And then this has to be underscore count. I guess I did it in other places, too. I don't think there's anywhere else. I think I got it. Not a number. Where did I miss it? Line 17. Over the box. Thank you. Line 17. I missed it. Okay, we're back. We did it. Thank you everybody. See you next time on the coding train. All right. Well
Good bye!
Yeah. So, not a perfect solution, but um this has got to be it. I can't I'm done for today. It is 2 o'clock. Um so, I'm learning some hard lessons over and over again. Honestly, I don't know if this is realistic for Matio to edit it together. It'll be interesting to try um and see. I would like it to work, but I don't know. So, this might just be it. This might be my three and a half hour lesson on basian text classification that I'll have to like time code and annotate. Um, I mean it was worth it to me to kind of like understand and learn it, but I don't think I made a particularly great version of it. I don't know how well this like translates into like, oh, everybody watching this is going to make like all these basian text classification like experiments now. So, I don't know. But you were all with me for this moment in time today, these three hours, and that was something. We did this together. Uh, a lot of the stuff I talked I gotta rethink and figure out what I'm going to do next Monday. Um, I think I need to This seemed like an uh I need to get this out of my system probably, but I think that I need to focus on smaller um smaller um bite-siz things that I can demonstrate, little short tutorials um and that kind of thing. All right. Um, I was going to do some Q& A. I don't have any energy for anything. I think I'm just gonna go kind of like awkwardly like the Homer Simpson gift. Uh, awkwardly back into the bushes. Dan, you should leave a message in this for Dan who is making this again eight years from now. Yeah, eight. Stay tuned. Uh, rebrand it as learning together. No, this is what a coding challenge is for me. It's the attempt of trying to figure it out on the fly. I did some preparation because I needed to like review what B theorem is in advance. But uh so anyway, I don't know. I appreciate your comments and your thoughts. I got to shut this off. So um uh Mr. Muse Addict is saying you inspired me to plug some basian logic into some analysis tools I'm making for my work. So that is great. One small little incremental improvement in somebody's work somewhere in the universe is a positive thing. I learned a bit more. I have a better example that if I ever teach this again. And uh that's it. So I'm going to see you all. Thanks for being here for this very chaotic, long, and not perfect stream. And um hopefully this cold is going to clear up and not be too tough on me. And I'll see you all next time. Next time on the coding train next Monday. So one thing you can rely on even though the time is a little bit I mean 10:30 is when I started today. 10:30 Eastern. It's probably about when it will be. But if you're trying to like organize yourself around watching the coding drain, don't change your I mean I'm going to miss I could very easily miss next Monday. But that's my plan every Monday uh being here this semester and we're going to sometimes do stuff like this. Mirksack said, "I love this. Didn't know about analyzing text like this. " There you go. I don't need to be so negative. This was good. And I'll see you all next time on the coding train. I'm gonna hit the finish button. I'm gonna say goodbye. Goodbye everybody. Have a wonderful day.