
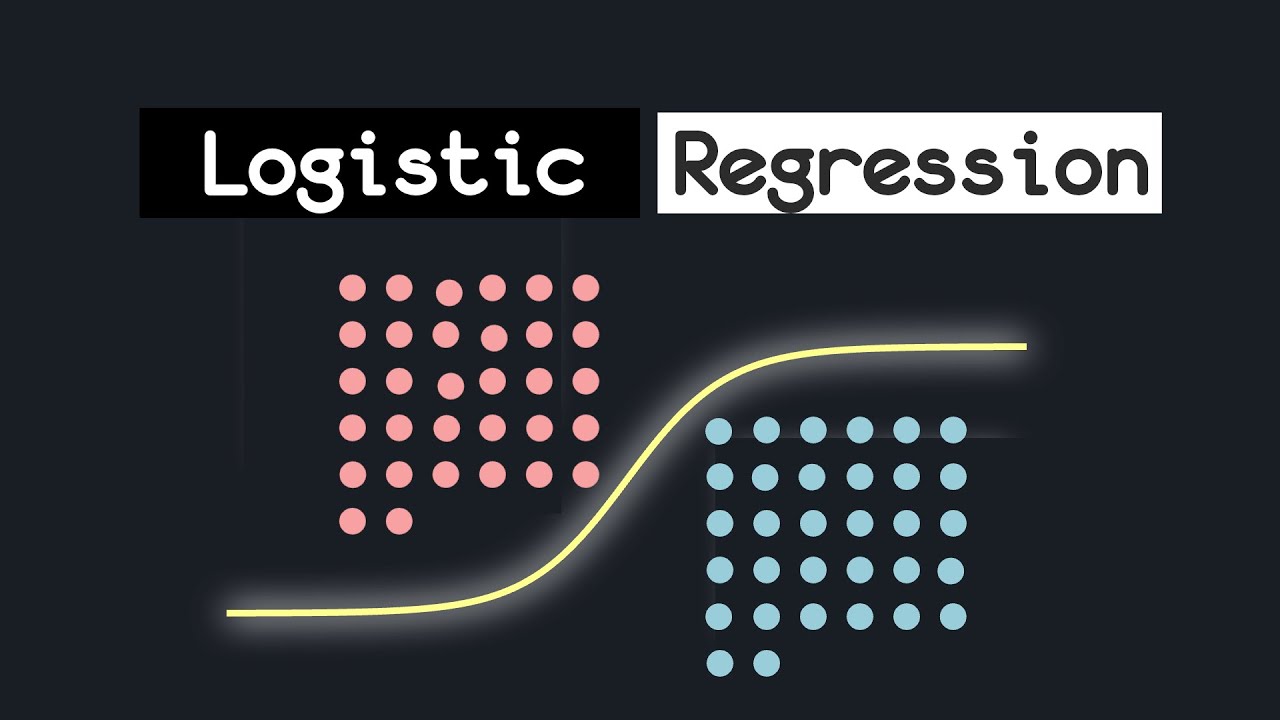
Decision Trees - VisuallyExplained
Machine-readable: Markdown · JSON API · Site index
Machine-readable: Markdown · JSON API · Site index
![[RE-UPLOAD] MOMENTUM Gradient Descent (in 3 minutes) *** No Background Music***](/thumbnail/qfb2ezDWGIU.jpg)

Экстракты и дистилляты из лучших YouTube-каналов — сразу после публикации.
ПодписатьсяЛучшие методички за неделю — каждый понедельник