For the past few videos, we've been going pretty high level, especially with the aid of LLMs. Not this time! We went all the way down to "what bits go where", with honest hard-working artisinal hand-written Rust code. Specifically, we implemented an audio generator that produces WAV files with white, pink, brown, and possibly other-colored audio noise. Prior to this, I had no idea how to generate WAV files, nor how to generate those kinds of noise, so this is a good ol' "watch Jon learn as he goes" video.
Thanks to the sponsor of this video: Hudson River Trading!
http://www.hudsonrivertrading.com/gjengset
Repository commit at the end of the stream: https://github.com/jonhoo/trough/tree/33623289870346696724769cded6dc2bbb07fc1d
LLM-assissted review and polish of the code (recommended reading!): https://github.com/jonhoo/trough/pull/1
0:00:00 Introduction
0:01:14 Colors of noise
0:08:42 Writing a WAV file
1:24:26 The Fourier transform approach
2:02:16 Implementing white noise
2:48:55 Pink noise
3:25:55 Brown noise
4:12:34 Blue noise
4:52:25 Violet noise
4:56:37 Grey noise
Live version with chat: https://youtube.com/live/BKHE7stqhoI
Оглавление (10 сегментов)
Introduction
Hi everyone, welcome back to another Rust stream. This is going to be another Imple Rust stream. It's very exciting. Uh we've done some of these, you know, over the past couple of months, but the most recent ones have been sort of aentic coding either uh partially or fully like the very last one. Uh then before that, we had the um the billion rows challenge in Rust, which is a little bit of a weird one because it was not really about idiomatic Rust in any way. It was like, let's see how much we can squeeze out of this by pulling as many tricks as we can. Um, but this is one where our I don't want to say we're going back to basics cuz that's not quite true, but we're going back a little bit to sort of where the spirit of the channel started, which was uh a combination of build things that are that I need for other reasons. That's not what this is. um and uh build things for us to learn about protocols and learn about you know um you know bit patterns and learn about like stuff in the world through programming. Um that's very much where this started was like a you know when we implement TCP from scratch it's not because we're actually need a full TCP implementation it's because we're looking to learn more about TCP by implementing the underlying thing. Um and so that's what I want to do again uh today. I want to take the
Colors of noise
time to essentially sit down and implement audio noise generation. Um, so let's uh if I switch over to the screen here, you'll see on Wikipedia there's an article on the colors of noise. Uh, and I know some people will be annoyed with me, so I'll switch it to dark. Uh, I'll do the same here because I don't think it does. Oh, there we go. Um, so it turns out the audio noise actually has multiple different colors. And you might have heard this like white noise and you might go well what other kinds of noise are there? Well there are other types of noise. So white noise is the one we're most commonly used to but there are other types like pink noise, brown noise, blue noise. Um this is even I liked when I just like randomly scrolled on this earlier. Uh there's also oh there's velvet noise but there's uh black noise also known as silence which oh that's a terrifying image. Um, so, so I just figured, okay, I want to know what these are. Like I've I know a little bit about audio, like theory, but not very much. But I do know that like white noise sounds different from pink brown noise. Um, and so let's figure out what that is. Uh, and hopefully learn something in the process. Um, and but in order to implement noise, we also need to be able to generate actual audio that we can play back. um you can't just like listen to noise without having some representation of that noise. Um and so I figured what's the simplest possible audio format that we could implement ourselves. And I think that's wave files. Um so the so wave files also known as WAV or I guess it's waveform audio file format. That's not short for wave. Um unclear why. I guess they just shortened the first word instead of making it an acronym. Otherwise, it would be a WTF file, which I guess sounds worse than wave. Um, which is a very old file format, and I'm hoping that it's old and therefore relatively simple, although that doesn't always hold up. Um, but the other thing that's important about wave files is that they are um uncompressed audio. So, MP3 files, for example, have a bunch of audio compression techniques in there to make the file smaller. And those things are all interesting, but I don't want to also try to learn all of those live during stream. And so instead, we're going to pick something that's relatively simple. Um, and so this is a PCM format, which means that it's pulse code modulation, which is one of the simplest audio representations, and we'll get into that later, and I don't know very much about it, so I will also learn with you. Um, but the intent here is that we should write a Rust program that takes a parameter that tells us the color of the noise. We should generate a wave file with noise of that color. And maybe we let you configure the volume or something of that noise. Um, and then we produce the file on disk and then we can play it back and hopefully it sounds similar to what the noise is supposed to sound like. I don't know. I think we will find out. Now, my one worry about wave formats is that because it's an older format, with these older formats, you also ended up with like weird like container formats and like everything was a little odd. So, we'll see whether this ends up actually being a pain to implement, but I hope not. Um, and this is a Windows Microsoft format, but it plays fine analytics. There's nothing Microsoft really specific about it. Um, but we will find out. Uh again I also don't know very much about wave but I have the impression that it's similar to um uh you know in for images you have BMP files and BMP like bitmap files are almost just like you print out the bytes for the red green and blue value of a pixel. Um and you just print you just like dump those into the file one by one by one for every pixel and then the resulting thing is your image. And so it's like very easy to encode back and forth from sort of a pixel representation to the on disk version. I'm hoping by false are roughly similar. Um so let's dig in. Let's find out. But I think first we need to hear what these noise colors sound like. Um and so if we go back to colors of noise here on Wikipedia, um got to always love Wikipedia. Um you'll see technical definitions of noise. Uh and I skimmed this earlier. Yeah. Here the color names for these different types of sound are derived from a loose analogy between the spectrum of frequencies of sound waves present in the sound and the equivalent spectrum of lightwave frequencies. Um that is if the sound wave pattern of blue noise were translated into light waves the resulting light would be blue and so on. So if we look at one of these diagrams, so this is on the x- axis there's frequency and on the y- axis there's intensity. So basically volume it's not quite volume but basically um and so this tells you that the intensity the the intensity is the right word I guess but think volume of the frequency the audio frequencies at 100 hertz which is sort of a relatively low um like rumbling sound like bassy sound um is the same as how um intense the higher frequency sounds are. Right? So up here we have I'm guessing this is around 40,000 kHz. Sorry, 40,000 Hz. So 40 kHz. Um, and that one you see has the same intensity. So the idea is that you get sort of you get equally loud all of the frequencies in the sound. Um, and if we play it back, it sounds like this. And so if you listen carefully, you you'll hear that there's like you hear quite a lot of high frequency sounds in there. And that's because there's a lot of high frequency in here as well. If you think about it from 100 hertz to 40,000 hertz, like if we equally distribute the intensity across there, there are way more of the higher frequencies than there are of the lower ones, right? Because as you go higher in the frequency space, you um like the frequency space is like a logarithmic space. And so the higher integrity one or the higher frequency ones um there are more of whereas if we play for example a brownian noise that has way more of the lower fre or more intensity in the lower frequency ones it sounds much less sharp in a way. So you hear that this is brownian noise. This is much more intensity in the bass and much less in the sharps. And then pink noise is somewhere in between. You see it also decreases over the course of the frequencies. So it should sound somewhere in between hopefully. Okay. So now we've heard the different noises and again the the thinking here is that we should be able to produce files where the sort of audio spectrum of them look something like this. And we can open the files in like Audacity or something to um which is an audio editing software to try to see whether it they actually look like this. But even just by playing it back hopefully we can go like when we play our white noise does it sound roughly like this. Um so let's let's find out. So for
Writing a WAV file
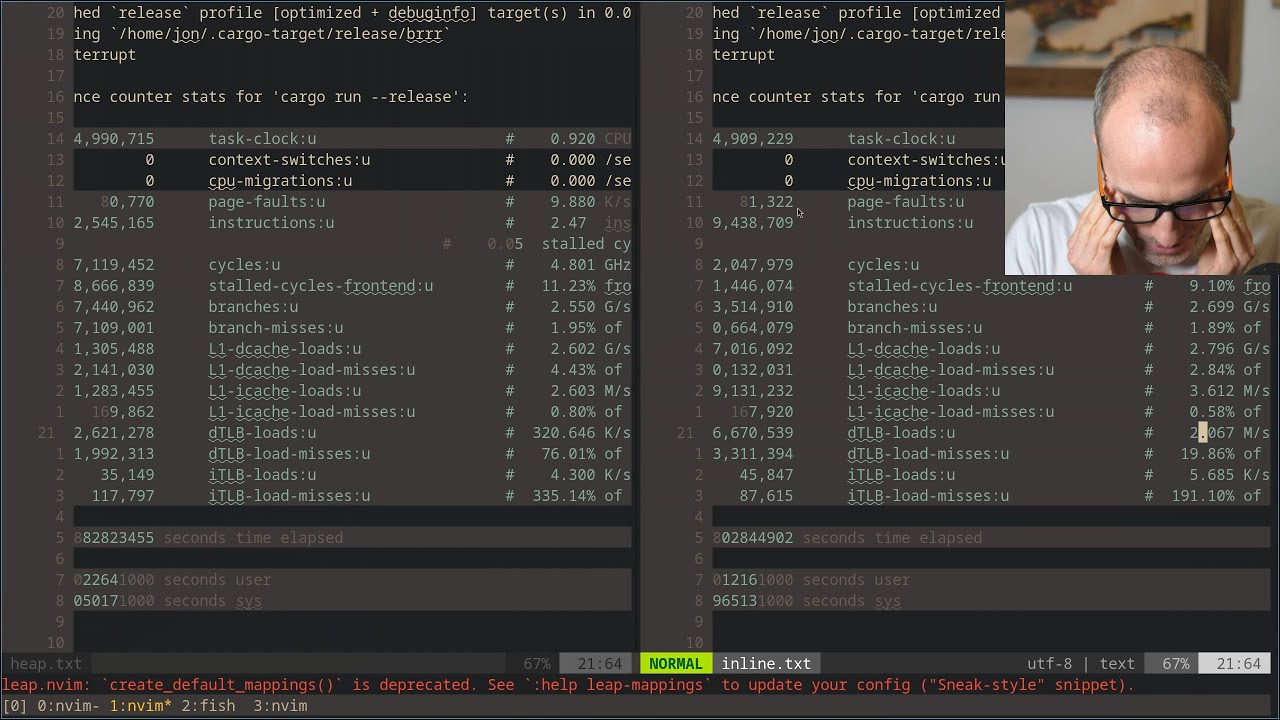
wave files let's dig into it from the beginning. Uh the wave file is an instance of a resource interchange file format defined by IBM Microsoft. The riff format acts as a wrapper for various audio coding formats. The wave file can contain compressed audio. We don't want that. The most common wave audio format is uncompressed audio in the linear pulse code modulation format. Also, the standard audio coding format for audio CDs. Nice. We're basically implementing audio CDs at the same time. Uh sampled at 44. 1 kHz with 16 bits per sample. Ah, so this is useful. This is stuff I roughly know what is. Um so the 16 bits per sample is for every sample you take of the the audio signal, how many bits do you use to represent that measurement? And then the killer the sampling uh rate here is how frequently do you take samples of the sound. And roughly what we're going to do is you know let's say we did 44. 1 uh 44. 1 uh,000 times per second. We're going to sample the current intensity of sound like the movement in the air effectively. Um, and whenever we do, we're going to store how much movement there was using 16 bits. And then we'll do it again, you know, 1 divided by 44. 1 kHz uh later. And then we'll keep doing that. And what we end up with is a um a spectrum of time on the x- axis and intensity on the y- axis. Um, and what we need to turn that into is um, uh, frequency and intensity, which you can do with a fast forward transform. We'll get there. Now, the reason this number is 44. 1 is I need to pull back like my um, older data representation stuff, but I believe it's because uh, human hearing goes up to 20ish 22ish kHz. That's like the highest frequency sound we can hear. Um, and there's something called the I'm going to get bitten by this. Is that the Shannon information theorem? It's something like that. But it's there's like um a rule basically. There's a rule that tells you that if you want to sample things um then you can perfectly reconstruct the underlying audio signal. if you have samples at more than twice the rate of the underlying frequencies. So if you want to capture frequencies up to uh 22 hertz 22 kHz, you would need to sample at least 44 kHz. The nquest frequency yeah sh uh nquest shannon frequency. I feel like this should be we should be easily able to find this, right? If we go back to 44. 1 uh and aha yes the selection of the sample rate was based primarily on the need to reproduce the audable uh audible frequency range of 20 to 20,000 kHz. The Nikos Shannon sampling theorem states that a sampling rate of more than twice the maximum frequency of the signal to be recorded is needed resulting in a required rate of greater than 40 kHz. The exact sampling rate of 44. 1 was inherited from PCM adapters which was the most affordable way to transfer data. Interesting. The rate was chosen following debate between manufacturers. Why? Interesting. Oh, because it has to relate to like NTSC for TV and stuff. All right. Well, regardless, what this tells us is we can choose any sampling rate we want for the audio files that we produce as long as we put in the file what the sampling rate is. Um, but if we want to produce sort of standard audio, uh, we should probably produce 44. 1 kHz samples, so that many samples per second with 16 bits per sample. Um, and we should store it as two channel LPCM. We could probably store it as mono. That's probably also fine. Um, uh, since LPCM is uncompressed and retains all of the samples of an audio track, professional users or audio experts may use the wave format. Sure. Yeah, we'll be we'll call ourselves professional users and audio experts. That's why we chose Wave. Um, okay. We don't care about compression. File specification. A riff file is a tagged file format. So there's a specific container format, a chunk with a header that includes a four character tag and the size of the chunk. The tag specifies how the data within the chunk should be interpreted and there are several standard 4C tags. Tags consisting of all capital letters are reserved tags. The outermost chunk of a riff. Okay, so they can be nested I guess has the riff tag. The first four bytes of chunk data are additional 4C. the chunk data are an additional 4CC tag that specify the form type and are followed by a sequence of subchunks. In the case of a wavefold, the additional tag is wave. Okay, so let's um we got to the streams uh cargo noob in um feel like there's something here. wave. Wave noise. It's like crush. What if it was wave as in ocean wave and it makes noise when the waves crash? What's the name of when a wave actually crashes? Is it just called crashing? Like when the top of the wave turns white and it folds over? That has a name? Uh, is it crest? No. Is it wake crest? I feel like it has a there's a uh wave crest wake. The Kelvin wake pattern. Oh no, we're going to get distracted. Chat is uh chat is very uh are debating with themselves between wake, crest, and break. Tsunami is not. No, no. That's different. Uh it can probably be used interchangeably, right? Like crest and No, because a wave is what you get behind a wake, I mean, boat. I think it's crest. wave crests. Aha. No, the crest is just the highest point of a wave. So, arguably we should be trough because we're the bottom part of a wave because we haven't implemented it yet. Sure. Why not? Great. Let's do that. It's we're calling this tool trough because it's at the bottom of a wave because we haven't started implementing wave yet. Perfect. Okay. So, um what we're going to do, there's an interesting question here also about whether we should make this print to standard out. I'm a little tempted to do so. So, um IO stood out Uh, no. I need Oops. Ah. And then I'm going to do out is out. Uh, and then we're going to do write. Uh, this has to be mute. Uh, write to out. It said first you need to write riff, right? First four bytes of the chunk data are an additional 4CC tag that specify the form type and are followed by a sequence of subchunks. Yeah, but do we need to give the length of the chunk as well? because it said um and the size number of bytes of the chunk. So we need to know the size of the file. file before we start wire writing it. This feels unfortunate. So, I just need to open a window to get a air in here. There we go. Um, maybe the top level is special. I wonder if there's a I guess we will find out first four bytes of chunk data. I think we're going to need to put a number in there. Um but let's do number of bytes of the chunk. So let's do four. What's the network ordering of riff? I feel like I want the riff RFC. Let's see. I want Here we go. Uh Oh, AVI files. Good old AVI files. Uh, yeah, all chunks have the following format. Four bytes is an ASKI identifier. unsigned little Indian 32bit integer. Okay, so we have a unsigned 32-bit integer. little Indian uh and then uh we'll use io right. Uh, what? Why can't I write bytes? Why doesn't it let me write bytes? All right, fine. We'll do this then. out. Now the interesting thing here is going to be whether this length of four Actually, let's uh let's be good citizens here and say uh result um stood io error whether when you have subchunks whether this length needs to be the length of like the combined length of all the subchunks or whether it can just be the length of the first subchunk. I guess we'll find out. Um, it's fine. Write all um but write normal. So the write just calls the system call for writing bytes and that doesn't guarantee that it writes all of the bytes is you need to write all which might result in multiple system calls outgoing. Arguably, we could use a buffered writer here, but I'm going to skip that for now. We can easily change that at the top later. Um, okay. So, if we go back, we have wave. Uh, the remainder of the rift data is a sequence of chunks describing the audio information. The advantage of a tagged file format is the format can be extended later. Yeah. Yeah, that's fine. Um, info chunks. The chunk may include information such as the title of the work, author, creation date, and so on. Uh, okay. That's fine. There's a c set chunk to specify the country code. Okay, I don't care about that either. A junk filler chunk. Oh, I see. So, you can delete something just by changing that. Interesting. Okay. So top level definition differential wave file is a riff with wave which has the format of the file a fact chunk points playlist associated data list and wave data. Okay so this should be pretty straightforward for us because I think we can skip many of these. Um, okay. So, the format chunk does. Oh, it's a format chunk. Interesting. That includes information such as the sample encoding, the number of bits per channel. So, this actually means that we're going to have to write this out. We're either it out to a file and then replace just these values at the end. So basically update the file after we've written everything out and know the length of things or we write it out to a vector and then we write everything out at the end. Okay, I think maybe then we will write this to a file and then we'll just patch the file at the end to inject the lengths. I think that's what we're going to do. So that changes this a little. Um, so we'll do file create audio. wave. This is obviously something we're going to have to make customizable later. Uh, we'll make that this. Um, and then this we're going to set to zero. Um, and so now this is going to be a wave chunk, which is also going to be set to zero. And then we're going to have another chunk. And this chunk is going to be the format chunk which we don't know what the possible option. I want the actual spec rather than the Wikipedia page here. If I can find it. Aha. O. The wave specification from 1991. Oh, broken link. Aha. Pages 56 to 65. Now we're talking. Long PDFs. That's how you know it's an old spec and is a spec. Uh 52. Oh, this is basically also meaty. Nice. Um. Uh, okay. Yep. 50 RTF files. There's all sorts of things defined in here. That's great. Okay. This section describes the wave format used to represent digitized sound. The wave format is defined as follows. Proje must expect and ignore any unknown chunks encountered as with all riff forms. However, format check must always occur before the wave data and both of these chunks are mandatory in a wave file. Okay, so it's a riff with a wave with a format chunk. The wave format chunk specifies the format of the wave data. The format chunk is defined as follows. Oh, so this one, this one is not tagged. Interesting. That makes me wonder if actually there's no length to the wave chunk either. Uh here if we go to riff tagged format uh I just want to see Here we go. The basic building block of a riff file is called a chunk. Using C chunk find as follows. Okay. Yeah. So you have a four byte character code. So it contains a chunk ID which is a 4 CC, a chunk size which is uh also a long and then it has data of that length. That's fine. This we know we can represent a chunk with the following notation. CK ID PN CK data. Okay. Form what's form type here? The first Dword of chunk data is a four character form. First dword of the chunk data in the riff chunk is a four character code value identifying the data representation. Right? So this would be wave. Following the form type is a series of subchunks. Which subchunks are present depend on the form type. Okay. But do the subchunks have lengths is what I want to know. Yeah. So this notation means it has this chunk ID and a data length and data. Yeah. Okay. So whenever we see this syntax but I see. So these are then strictly following each other. So it' be this 4 CC and then but this would be a how can a 4 CC be three letters? Like what happens if a CK is shorter than four? Aha. Padded on the right with blank characters. Asky character value 32. Why 32? Oh, space. I'm thinking of I was like, isn't space 20? But no, space is 20 in hex, not in decimal. Um, okay. Interesting. So if we now go back down. Oh no. I love specs like this. Great. So we need to remember that H's mean hex. No modifier 16 bit. C I guess it's eight for character. Okay. So this is a 16 bit by default unless you say long. So it follows sort of C convention. Great. Um, strings Z is null terminated. B and W have SC size prefixes. Oh boy. Okay, great. I think that's most of what we need. Let's now go back to our wave file. So we're going to have four literal characters wave followed by a format chunk. The format chunk is defined as format. Okay. So this is that same notation. Uh so the there's no data length between wave and this but this now says format padded by space followed by common fields and then format specific fields. common fields is a strct. Aha. Okay. So we will do um referenc on this uh and padded. No. So packed I mean um and we're going to have what exactly? We're going to have a format tag uh which is going to be a word. So it's going to be a U36. Sorry. What am I saying? I said U36, wrote U32 and meant U16. Um, and a channels also a samples per second which is a U32. uh and a average average bytes per second also a U32 and a block align which is a U16 we'll call this the format chunk common uh and then we will do so this does need to of the length. So this will write out um stood me size of format chunk common. This is going to return a U size. So we're going to have to cast that to a U32L bytes, right? because that's the s of size of a format chunk. And then we will have to write out the actual format chunk which is going to be um we're going to do here a format chunk common. Um now let's see what the format tags are. A number indicating the waveformat category of the file you must register any new wave format car see registering okay overview of the most see for information on registering I don't want to register Ah, wave format category following the section list the currently defined one wave format PCM great okay so we'll do this and then we can actually go in further we can take this whole thing if we want to be slightly more oh the selecting this PDF is broken okay so we can do even better we can say um repper this is going to be a um U16 and it's going to be an enum of wave format category. Uh this will be wave format PCM and it'll be equal to this. We can even give it nice docs. And then we can say format tag here is going to be weight format category. And then here we can say waveformat category waveformat PCM. Uh PCM is the is um pulse code modulation. It's how we're going to take the auto format and put it into bytes. We don't know yet exactly what that encoding looks like. We'll find out later. Um the reason we want packed here is so that uh because people asked in chat the reason we want packed here or the reason we want C here is because in the rust representation the compilers are allowed to reorder the fields and we know the fields have to appear in exactly this order. Um the reason and reperc will do that. The reason we want packed is because we know these fields have to appear in this order with no padding in between them. Um whereas with C you the compiler is allowed to inject padding between the fields to make them better aligned to CPU architecture and the like. And we don't want that. We need them to be exactly in this order with no gaps. Hence the the pact. Okay. What comes next? Channels one for mono. Let's do one channel for now. Um samples per second at which each channel should be played. So here we're going to do 44 100 and average bytes per second. The average number of bytes per second in which the waveform data should be transferred. Playback software can estimate the buffer size using this value. I guess this is what did we say? So we said six we said 16 bits per sample. So that means two bytes per sample times 44100 right that's how much we would expect to get uh times one channel but that there's only one channel uh block align the block alignment in bytes of the waveform data need to pro multiple of block align bytes of data at a time so the value of block align can be used for buffer alignment Oh, do you need the wave format prefix for enum numbers? No, I do not. PCM. Much better. Um, I don't know what to put for block alignment here. Playback software needs to process a multiple of block align bytes of data at a time. 64 jar. Um the next thing it rightly rightfully complains is we're trying to write out a thing that's a strruct and it wants to write out bytes. Um and here um there are a couple of ways we can do this. The easiest one is probably just to like we want to take this and we want to cast it to just bytes. Um there are um so there's been some work on uh safe transmute that would make this a lot nicer to work with uh rather than the thing we're actually going to do which is to say we're going to take a point a reference to this uh we're going to cast that to a uh const format uncommon. Uh then we're going to cast that to a const u8. Uh and actually we're going to do that slightly differently. Um we're going to say format chunk is actually we're going to do it even more annoyingly. We're going to make a little helper. We're gonna say uh write as bytes. Uh it's going to take a reference to a t. Uh should this does probably need to be unsafe because it can end up reading padding bytes. Um, and it's going to take a uh out which is going to be an imple return uh results stood io error. And here's what it's going to do inside. Um, it's going to say uh as bytes is t uh why am I getting await? Why is await an option? I don't want that. Um I want uh ts star constuate. Uh actually I want pointer and then I want to return stood me no stood slice from raw parts. Uh that's going to be a pointer and stood me size of t. We can actually just call this cast to bytes instead not take the out and then it just returns you a u8 slice. Uh right. First need to cancel it as a const t and then constate and this is going to be unsafe and this is no longer a result. I'll explain this in a second. Uh, and then now I should be able to do cast two bytes of this guy. Got to get my PNS in a row. There we go. Okay. So, what does this do? Um, so here's what this does. Cast to bytes takes a reference to a T and it gives you back a slice of the bytes of that type. Um, so what we're going to do is we're going to take the reference to a T. We're going to cast it to be a um a raw pointer to a T. And then we will cast that to be a raw pointer to a U8. Uh, and so this is now a pointer to the exact same place, but the pointer is of type bite instead of type T. Um, then we're going to create a slice. So in this case it creates a u8 slice because the pointer we pass it as a u8 pointer and then we pass it the size of t as uh that is the number of bytes that we know this points to as valid data. Uh and then we unsafeely return this as a uh as a slice. Now the reason this has to be unsafe the reason there isn't a safe version of this is imagine if t contained um padding bytes. If T contains padding bytes, then this would allow you to end up reading those padding bytes, but those padding bytes might be uninitialized memory. Like the compiler didn't put anything particularly in there, and reading uninitialized memory is no bad, bad stuff. You're not allowed to do that. Whereas this would allow you to do it and therefore it has to be unsafe. And so if we put a um you know a safety comment here only safe to call on uh packed types. I think that's the only restriction actually. Everything anything else you pass here is fine. Um and then the requirement for from raw parts is behavior is undefined if any of the following conditions are violated. data must be nonnull. It is non-null, right? Because we got a reference to t in. So we know it points to something. Valid for reads for len times size of many bytes. That we know because we know that the thing is um size of t long. We're so len here is what we where we pass in size of t and size of t is size of u8. Uh so that's fine. It must be properly aligned which doesn't matter for us because uh bytes are always aligned. um the entire memory range of this slice must be contained within a single allocation. That's also true, right? We know that there's t there was one allocation of a t and this is a pointer to that whole allocation. Um and data must point to len consecutive properly initialized value of type t. This is the thing that puts the restriction on the input t must not contain padding bytes and then mutations and stuff which we don't care about. So here uh what we can do is we can say safety um uh pointer is valid for uh until pointer plus size of t since it was a reference to t which is valid for size of t. Um and pointer to pointer plus size of is um is valid since we had a ref t and pointer point. uh contains um initialized bytes by the safety requirement of this function. Uh a bunch of questions. Let's see. Um why not just serialize it instead of casting pointers? So if you derive serialize for this, the question would be what are you going to serialize it as? So there are um there are formats I think that will just like write out the raw bit value of a given underlying field. Uh but actually this is something this is a good thing you caught me out on here. Um this will directly write out like we're casting it to bytes, right? So whatever Indianness this value is in is the thing that will go on the wire go in the file. Um and almost certainly what we're gonna end up with is that this will be big Indian and I'm assuming these numbers are all little Indian. Uh actually let's find out so like which whether the higher value or lower value goes first. Let's go ahead Wikipedia Indianness. So for those who haven't been exposed to Indian nest before, Indian nest is basically when you have a let's say a 32-bit integer. So like a four byte integer is the first bite. So the the one that comes earliest is that the one that holds the higher value bytes or the lower valued bytes. So little Indian is the lower value bytes come first. Big Indian is the higher Um right. So here you can see this is the higher value bite. It's the one that's two to the power of you know the however long you go to get to the fourth bite. I can't count right now. Um those go first in memory. Whereas in little Indian the the trailing end like the ones that have a that are you know hexwise one base one um go first then the ones that are base one bite more uh so the 256 uh go here and so on um and you'll see here that um where's the yeah so a big Indian system stores the most significant bite at the smallest memory address least significant bytes at the largest a little Indian system is the opposite. Um both of them are widespread and this is part of the problem is that if a like if you just write it in whatever you're in the chances that you will match whatever the spec you're trying to match is like 50/50. Not to mention if we run it on my computer versus someone else's computer they might get different results. Now in practice you'll find that big Indian is usually used in network protocols and little for processors. So my CPU is little Indian. Uh most networks are big Indian but again not guaranteed in either case. Um, and so if we go back to RIFF and we look at their representation of numbers, which was I think pretty early on actually let's just search for Indian. Really no mention of Indian, huh? Indian data is stored in little Indian bite order. Okay, thanks Wikipedia. Um, okay. So these have to be little Indian which happens to be what my computer is. Now we have an option here. We can either just leave it at U32 because both of them are little Indian. Everything is fine. Um, or what we can do is we can use a type that will encode the Indianness directly in the number. Um, so for example, if you look at is it the encoding crate? Uh, no, that's not what I'm after. Um, is it bite order? Bite order. Yeah. So, if you look at the bite order crate, the bite order crate gives you types like big Indian and little Indian. Um, and I think they also have Um, this is just a mechanism for serialization. What I really want is a uh an actual type I can use would have been nice. Uh, byte order sort by recent downloads. The zero copy crate. Actually, maybe we should just use the zero copy crate. um the zero copyright lets you basically do the stuff we're now doing but without unsafe um because it it's um it's essentially a precursor to things like safe transmute. Um and so here if we scroll down you'll see it gives you where are the modules byte order uh it gives you types like uh U32 for instance but it's generic over the byte order and so you can have a type like U32 parameterized by big Indian or little Indian so that when they are cast they end up with the right Indianness. Do we want to go down the whole rabbit hole of zero copy right now? Yeah. Right. It makes me a little sad. But the alternative is that we can't do this cast, right? So the alternative would be that we write out the fields one by one and we do it manually by specifying the bite order. But I'd much rather be able to do the cast here. Yeah. All right. Let's do it the other way. The focus here should be on audio. It should not be on zero copy. But I am a little tempted because I have a suspicion we're gonna have to write out a bunch of different ones of these and writing out all the fields is pretty annoying. Let's do it. It's an interesting thing to explore. So let's do No, that's not where we want. We want uh streams and uh what we call it trough. So we're going to do cargo ad zero copy. I believe zero copy is actually pretty straightforward. Um, so if we do uh I really wish they had a get started quickly one. I think they do on their repo. So if we go here and we go to really there's not an examples. I feel like I've seen an examples. Well, what we want is into bytes. Ah, there we go. This is indeed what I want. So, I would like here please uh derive of into bytes and then we'll use zero copy into bytes. Oo, what's into slice? That's even looks even nicer. Um, but see it gives us helpers like write to IO, which is exactly what we want. Um, and then I will go down here and I will change these. So this will no longer be what am I confused? Aha. Oh, I need to that's because my cargo toml down here needs to say version is this features is derive by now car I can't type uh yeah so now it's going to tell me that they're not satisfied and the reason they're not satisfied is because we're using the raw integer types which don't specify their Indianness and so here this is going to have to turn into U16 uh and oops uh U16 and we said it has to be a um little Indian U16. So this is going to be the same. This is going to be a little Indian U32 and U32. And then here we need to also derive into bytes for our thing down here. Um, and this interesting how does that even work for a U16? I wonder. So into bytes. What happens if I derive this on an enum? Because a use this U16 here is still ambiguous what Indianness it is. So how can I simply derive it? It works for U8. Let's go here and see error messages analysis instead of an enum it must have a defined representation does that must have no padding bytes its fields must be into bytes. Interesting. But how do I specify the endingness for this? Feel this. Feels like something's missing. Let's go see. Let's go see what other people say. Um, enum repper Indianness. Indian. Aha. Okay, what actually changed to ensure consistent endiness for enomes with multibbyte representations explicitly specify and convert each discriminant using LE but it but the macro doesn't enforce this. Interesting. Uh, U32, sorry, U16. All right. Well, we did that. Uh, and now this becomes a lot easier. So, if we now go back here, that's in theory all we need to do. Um, and if I now go back here, you'll see that I now have an implementation of the trait into bytes. And so now instead of my cast to bytes thing, we should be able to do this and then say uh view write to IO and give it out. Oh, where self is immutable. So that would be if I do this maybe then I can write to IO. So we got to turn all of these into their appropriate representation which should be a no op because we're turning little Indian which is my CPU into little Indian what we specified here. It really doesn't like this for some reason. Why don't I get right trio where self is immutable? Okay. What implements immutable? Aha. Yes. There is no interior mutability in either of these. So we can say immutable and then we can do the same for this. And under the hood, what this implements is the same thing as safe transmute, which is really just all the same um transmute things we had, but they're checked at compile time. Um and so it basically checks that you have no padding bytes, um NDNS specified for all fields and as a result it allows you to cast into bytes uh safely and now it should be happy with me. Still not happy with me. Why is it not happy with me? Okay. So, one trick here, um, if it doesn't understand that this type exists, you can force it to be slightly more helpful by saying into bytes colon. So, fully specify this and then do this. Am I what? What version do I have? 0848 0848. Are there feature flags I need to turn on? What? Where's self is immutable and W is right. Those are both true. Are there multiple into bytes? So if I go to definition here has mute bytes. Yes. Write to prefix write to suffix. Write to io if config feature stood. Do I need to enable stood? Oh, the stud feature is not on by default. Wonder why. That's an odd choice, but okay. Um, write to IO. That's fine. Um, so now we get to do this and we can get rid of our unsave function, which was just a helper anyway. Cool. So, uh, let's now erase all of that stuff we looked up and go back to our spec. Okay, wave 56, right? Um, great. So, we've specified those. We don't know what block align does yet, but that's fine. Um, the format specific fields because zero more bytes of parameters, which parameters occur depend on the wave format category. Uh well, we specified the format category one oh these are proprietary wave format categories. I wonder how far those went. Uh okay, so that suggests that there are no there's no format specific fields. So what else do we have then? It's fact, chunk, Q points, playlist, and associated data list. So all of these we can just omit these chunks. we don't need because we don't have that information. So now we want to go to the wave data. So now we get to PCM. So now we've written out actually we could have a we could have even more of an helper here actually which is some something like write chunk right. So write chunk uh is going to take a uh um a 4cc which is going to be a uh u84 reference to sure um it's going to take a uh an a reference to t. This is going to be generic over t uh is into bytes uh plus immutable. Uh it's going to take a w which is a write and it's going to take um the IO the mute out. It's going to implement W and it's going to return a result of nothing and stood io right uh error I mean uh and so now what we can do is uh have this write out these plus this out uh no I mean uh t. So this will now write out the 4cc and then the size of t in the right format which is the size of the chunk and then write out the actual chunk. And now we can replace all of this bit with write chunk uh of B format space and this thing and out uh and this can be a reference doesn't even need to be a reference really if they've implemented this trade well they have so we can give an owned one here what this means actually so here I'm now giving a not a reference to this t but just a t directly. Uh what this means is that the into bytes trait must have an implementation like in the zero uh bytes crate there must be a um implement into bytes for uh reference t where t implement into bytes. This implementation has to exist inside of zero copy because otherwise um it would not have worked to do this right format chunk common that one implements uh we know this type implements two bytes that we know right because we derived it for it. Um but this does not necessarily implement the same trait. So this must mean that this implementation actually exists in zero copy which is why this was allowed. Um but that's neither here nor there. Um cool. So now we have a little helper for write chunk which might be completely useless because I suspect we're not actually writing any more chunks now that I looked at what came here. But let's find out. Um block a line. Someone found a formula. Aha. Okay. Let's uh let's chill out. Do it from the beginning. If the W format tag field of format text says wave format PCM, yes it is. Then the waveform data consists of samples represented in pulsecode modulation format. For PCM format waveform data, the format specific fields is defined as followed. Ah, so we also need bits per sample. Interesting. So that means uh we also need to write out here a out. all uh bits per sample format specific for PCM actually let's just do it um let's write it like they are which is word w bits per sample uh and so this is going to be a so word here means that it's a U16. Uh, so we're going to have a bits per sample. How many did we say? We said 16 bits per sample. So 16 U16. 2LE bytes and borrow that. Oh, and this needs to just be given mute out. So that's what it asked for. Uh the bits per sample field specify the number of bits of data used to represent each sample of each channel. If there multiple channels, the sample size is the same for each channel. Uh for PCM data, the average bytes per second field of the format chunk should be equal to the following formula rendered up to the next whole number. The number of channels, right? I think this we already have, right? The number of channels which is one times the number of bits per second which is this which is what? Yeah. Okay. Bits per sample divided by 8. So that's two and this. But why does this say bits per second? Oh, and the divide by eight ends up being to both. Okay, great. Um, I think this there's no bits per second, right? There's samples per second. I think this is just wrong. This should say samples per second because you can't bits per second times bits per sample makes no sense. Pretty sure that's wrong. Uh pretty sure common and specific fields are part of the same chunks. You likely need to include the size of bits per sample in the chunk. You're probably right. Uh okay. Uh we will do that with format specific fields needs to implement. Aha. Uh format specific is going to be FSF. And then we're going to have this whole thing again. um wave format chunk fields uh or format chunk uh actually it's PCM I guess uh which only has what was the name of the field uh bits per sample which is going to be AU16 and then we're going to do here format specific it's going to be format chunk PCM of 16. It's per sample 16. Yeah. Clippy, thank you. Um, right. So, we make this generic and then we make this at the end and this is the only generic instantiation we actually use. Uh the reason we need this is because uh as someone pointed out in chat the chunk the format chunk has a length and that length needs to include this field. So if we just write the field after it will not be considered part of the chunk and everything will be out of whack. Um okay fine clippy stop yelling at me. Um the block align field should be equal to the following formula rounded to the next hole. the number of channels times bits per sample divided by two. So two, right? So this is supposed to be channels times bits per sample divided by 8. Bits per sample is 16 divid 8 is 2 * 1 is 2. So 64 would have been wrong, but I don't think it would have mattered because it seemed to be about buffering in the clients and if they buffer 64 bytes, not the end of the world. In a single channel wave files, samples are stored consecutively. For stereo wave files, channel zero represents the left channel, channel one represents the right channel. The speaker position mapping for more than two channels is currently undefined. Good old 1991. In multiple channel wave files, samples are interled. The following diagram shows the data packing for 8bit mono and stereo. Channel 0, channel Z, channel Z, channel one, channel Z, channel one. Okay, so we're just writing out the the samples in order. Uh we're using 60 16 bit and it's little Indian low order bite then high order bite. Lower Cool. Uh each sample is contained in an integer I. The size of I. Is this whole thing a chunk? No, this is just the data. It's the trailing data of this wave chunk. This is not a wave chunk of this riff chunk. Oh yeah, this is also wrong, right? This should this should be channel one. Cool. Um, each sample is uh is contained in an integer I. The size of I is the smallest number of bytes required to contain the specific sample size. S size of I. Yeah, this is just the bits per sample. The least significant bite is stored first. The bits that represent the sample amplitude are stored in the most significant bits of I and the remaining bits are set to zero. For example, if the sample size is 12 bits, then each sample is stored in a two byte integer. The least significant four bits of the first least significant bite is set to zero. Okay, so this just means that even if you have a format where you only record let's say 12 bits, you still have to store 16 bits and you just set you just pad with zeros. Uh because we have a um a sampling size of 16 bits, we don't need to do that. Um okay, I don't need them to tell me how many ints you can store in bytes. That's fine. I'm glad they tell me the midpoint value. Thank you. Uh, example of a PCM wave file. RIFF chunk start wave format chunk start fields data. So data is a chunk. Interesting. Okay. So that means um we have to be and this is a chunk that we also don't know the size of ahead of time, right? Although arguably we could because if we know how much noise we're generating then we actually know the size of the file ahead of time. So it depends on whether we want this to be like the user hits C and then we stop generating noise or whether we just always want to generate a fixed amount of seconds because then we can actually know. So how about we do that instead? So we say um let seconds is 10 um fine duration in seconds don't want to support partial seconds because now we can actually compute um right so we know the number of bytes per second so we can actually compute these we know that the Uh we know that samples per second is 44100. This is a U16 uh U32 samples per second U32. Uh we know that a we know that the number of channels is one. That was a U16. Uh we know that average bytes per second as a U32 is channels times samples per second times bits bits per sample. Um, and we also know that bits per sample is 16 / 8 as U32. So now this is samples per second. This is average bytes per second. uh this I guess we can make B channels times bits per sample divided by 8. So we can actually follow the formula and this is going to be bits per sample because now we can compute length in uh sample data length is going to be average bytes per second times duration in seconds. So we know exactly how long the sample data is going to be. And then we can actually compute this one as well because we know that this is now um uh if we pull this guy out format is going to be this right. Oops. format. Uh and so we know now that this here is going to be sample data len and this plus uh 3 * 4 right so three uh three 4C's wave format and data plus the size of format. Uh and here we can use size of val and give in format. Uh and this as U32. So now we don't need to go back to um to edit the file. We still could if we wanted to, but let's keep it simple for now. You probably want to measure it in samples rather than seconds. Uh, oh, you're probably right. This is going to be uh samples per second times duration in seconds times channels. I mean, it's the same as average bytes per second, right? Um, so we're just redoing the I'm going to keep it this way because we happen to know that this is like a we would just use the same formula. Uh, it's we know it's not average. It's a fixed rate encoding. Um, okay. Um, and then it's just the wave data storage of the wave data. The wave data contains the waveform data. It is defined as follows. wave data is a data chunk or a data list. A data chunk is this is definitely wrong. This spec for the format because this already says data is a chunk that holds wave data. But wave data is or can be a data chunk and data chunk that holds wave data. So you would just end up with data all the way down. There's no wave list and silence. It can also be a data list. Okay. What is a data list? Do they mean a wave list? Okay. We're on page 60. Let's go back and see what lists are. Uh string escape sequences name type an optional sequence. Okay. But what is a list? Uhhuh. Is there data list here? No. Storing strings. Aha. List chunk. A list chunk contains a list or ordered sequence of subchunks. The list type is a four character code that identifies the contents of the list. If an application recognizes the list type, it should know how to interpret the sequence of subchunks. Okay, so list is a chunk where the first part of the chunk is the type of the list followed by the a list of chunks. Okay. But then where does the actual like is there a list data info list chunk sea chunk junk chunk. That's fun to say. Uh see talk. I want Okay. And then it just stops. Okay. uh Okay. Wave data. But what is a data list? Data list appears only once in this document. Cool. So data list is probably wave list. I love this spec. We could go to Wikipedia and check, but it's more fun to read the spec. Uh, so this means wave data can either be a data chunk or a list. If it's a list, then it's a list of data chunks or silence chunks. I see because this is not a list. Okay. But where does the actual data go? I understand this one. Where's the actual data check? Yeah. So, don't use zeros. Use silence. That's fine. But okay. So, that that's all we get. All right. Because this is still a chunk and that chunk is defined like this and that leads with data but that contains wave data which is this. So where do the bytes go? I feel like it must go here, right? Like it's got a data chunk has to just hold. But then why does Oh no, this is an example. I see. So I understand what's happening. Um uh it's not that you must start at a data is that you can either start with a list in if you want to inject silences or you can directly inline the data list. So a data is a wave data. This is wrong like a data this here should not say wave data because this can't recurse. The moment you put a data chunk those are just the bytes. I'm like moderately sure. So what that would mean is because we don't care about silence blocks, we don't need the list. Therefore, we can directly use the data chunk representation which means we just give data but it has to be lowercase data uh and then a data chunk and then we just write the samples because otherwise you would read this as this could be data data data and you can just keep nesting them which makes very little sense and also then there would be nothing referring to wave list. So I think this should be wave. And so it's just saying if you can have a list if you want data and silence alternating but you can also choose not to use a list and just directly embed the data which is what we will do. Let's try and see what happens. The thing that will now be difficult is how do we generate a file that we can realistically test. I think what we should do is try to generate a file that just has a static tone in it. because that we should be pretty easy to find out whether that's reasonable or not. Um and so now the next question is what is actually stored and we saw it mentioned somewhere here that it's amplitude. Um amplitude. Yeah. So it's sampled amplitude. So what they're after is you know uh split your recording into samples by time and each sample should be the amplitude of the sound the movement in the air if you will at that point in time and then give me lots of those samples but when I say
The Fourier transform approach
for example a pure tone is a frequency and so the question is how do you go from a frequency which would say frequency on the x axis and amplitude on the y- axis and I would say I want a you know I want a uh 80 Hz tone, right? Which is just a spike at frequency 80 and then with some amplitude which would basically be the volume and then turn that into this amount of time and this amount of um uh like the this amplitude over this time and for that you need a fast 4year transform or a four-year transform really. Uh so let's go look at for your transforms Wikipedia. Okay, so for your transform lets you let me see if they have a good uh there's a lot of math but I want to see the plot. Give me a plot. How do they not have just like the basic plot of frequency to amplitude? Oh, it is here. There's just Is this an animation? It is an animation. Okay. Well, that's not that's also not what I wanted. No. Go back. Um, so a 4-year trans No. Aha. Close. I can't click that because it's behind my camera. Um, so the four-year transform uh takes a function. Does anybody That's fine. Um the forer transform takes a time signal and turns it into a frequency signal. So x-axis is time to x-axis is frequency. What we want is something that goes the other way. So it goes from frequency to time. And so that would be an inverse inverse for in maybe it's in the same document. We want an inverse for your transform which goes the other way. So it takes frequency to uh to time. But I just wanted to see if they had a nice had the nice like graphic for it but I don't see it sadly. Uh none of these make me happy. Aha. Yes. So um this is a time signal. So this is the x axis is time, the y is amplitude, y is always amplitude. Um, and if you look at a signal like this, the reality is this is really the overlapping of multiple different signals based on frequency, right? So this has some frequency, this has some frequency. And if you sample them at one point in time, what would you get? And you get this sort of interposing of all the waves that dictates where the what the amplitude is at any given point in time. And if you sample enough of these then you get a sort of view of the over overlapped underlying frequency signals. And so if you want if you do um an inverse 4year transform oh sorry if you do a fouryear transform it takes you from the left hand side here from a timebased system to the right hand side through a frequency. So it says this um these sort of timebased samples you've given me give you here are the uh frequencies and what amplitudes they're at u in that signal and the inverse for your transform goes from this thing so as which is frequency on the x-axis and tells you at these discrete points in time what would the amplitude be if you sampled this at that interval in time. And so what we want to do in this case is we want to just stick the amplitude all in one frequency. Run an inverse for your transform to get the timebased signal. Um and then take that and just stick it in the sample data. Uh oh yeah, we could also use sign. Maybe we'll just do a we're going to need an inverse for your anyway for the noise, so we might as well stick it in there right away. Um okay, so what we're going to need is an inverse for your transform. Uh and this is something I don't want to implement myself especially because it would be very slow. Uh so let's do for uh sort by recent downloads. Excellent. Let's look at both of these. Um both seem to be maintained. Let's do our little bit of due diligence here. We don't need to do very much. This is not a project that matters. Rust FFT certainly sounds official. Uh 17 contributors, eight. Let's look at the actual contributor graph too. Wait, the maintainer of this one is one of the top contributors to this one. I'm deeply confused. But that was in 2020. And then after that they moved to this repository. mighty suspicious. This certainly seems to be more maintained or at least have more people working on it. How are we looking activity-wise? Okay, so this seems to be more of a oneperson thing, even if they were one of the main contributors to this one way back when. All right, let's go look at docs. I think honestly either of these would be fine. Um, but let's then go back here and say look at the docs of both of them and see if they're both actually. Oh, one was a wrapper for the other. Oh, is a wrapper for Rust FT that enables fast FFT for real value data. Oh, interesting. I guess it's in the name real FFT. But we don't actually need reels. Let's see how this works out. So create an FFTD planner and call plan FFTD. Choose which to use. Also exposes individual FFT algorithms. All right. And does it have Let's hope it also has inverse as well. Yeah. Plan FFD forward. I'm assuming it has uh inverse. Yeah. Okay. Plan FD inverse. Interesting. And what implements FFTD num? I wonder from primitive. Oh, it uses numbum traits. I see. Wait, so this already does F-32s and F64s. Why I don't directly avoids the need of converting real value data to complex before performing fft. Oh, it's because I don't need so fast for your transforms lets you do um to transfer complex numbers like um let me rephrase um if you look at a waveform um you have the amplitude and you have the phase of the signal over time. Um, and we don't need to track here. Let me think here. I don't think we need to track the phase of the audio signal. Basically, the So, the 4year transform is pretty powerful. It can capture um things like how many times has this wave gone through not just um not just its frequency um by capturing sort of complex numbers here but we don't actually need that for audio. So I think actually maybe real FFT is nice because it gives us a simpler mechanism because all we need are the amplitudes. Let's It sounds like because one is the wrapper of the other, it feels like we can probably just use real FD and then switch if we don't like it. So, let's do that. Um, cargo add real FFT and Rust FT. Uh, what do you really need the for your transform? I think the noise functions can easily be defined in the time domain. They probably can, but they are usually described in terms of the frequency domain. And so this feels nicer to operate there. Um, length here. This we're going to have to modify after a little while, but that's fine. Um, we want a FFT planner. Okay, let's go and just copy paste this and see what we get. So right, we want to pl plan an inverse. We want a make a vector for storing the spectrum. No, the in data here is going to be the spectrum and this time. So the because it's an inverse, the input is going to be in the spectrum and the frequency domain and the output is going to be in the time domain. Is it still process? Yeah, it is process. Uh, it should go from spectrum to time. Uh, and it's going to be the output. Cool. So if we now take So spectrum is going to be a vec and let's just like errint line uh spectrum. It's going to be spectrum. len. Don't think we need these. Time is going to be time. len. In fact, let's try to run this for the first time. See what happens. Uh okay. So we said we want a length of 256 and the length is the length in the time domain. Um and I think this applies for the forward as well. So what we're saying is we want this many samples in the time domain. Um and then the FFT is going to give us back um or it's going to tell us how many samples do we need to give in the frequency domain in order to get that many samples in the time domain. So in this case you'll see in the time domain if we want 256 we're going to end up with 129 um values in the uh in the frequency domain. And so here we can now pick a um arguably a random point in here. Uh we can set that to uh basically the amplitude we want this to have. And this is where it'll be interesting to see. I think the amplitude here is probably in decibb. We might find out if we generate a really loud noise. So, how about we go with um minus30 dot into dot. Okay. And then for sample in time, we're going to do out. right all. And I guess just to make this slightly faster, we'll also do um use stood io um buff writer. And then we'll now here when we create this file say that mute out is buff writer new of out uh we're going to outright all so sample here is going to be an f64 um we want to round to isn't there a nearest I think F64 has a way to I guess round is the nearest integer uh and then we'll cast that to uh we'll actually do U16 try from here uh just because I want to make sure we don't end up overflowing the U16. Um, and then it's two LE bytes. Ah, uh, as U6. Uh, oh, that's interesting. Can the amplitude even be It can't. So, what is the amplitude? If we go back here to this the samp the amplitude, huh? They don't actually say what the amplitude is. Yeah, I understand that's the maximum value, but what's the Okay, I mean it's an integer and it's an unsigned integer. So, oh wait, what? 16 bit PCM is signed. Then is it signed or is it just Yeah, it must be signed. Okay, so it's s So 16 bit PCM is signed 16 bit PC PCM but if it's 8 bits then it can't be negative. Yeah. Okay. Yeah. Here. So one to eight bits is unsigned. Nine or more bits is a signed integer. That still doesn't tell me. Okay. So that means this has to change slightly. Um because actually only this has to change. It's an I16. This also has to be I64. I just want to see what we get here. That's what I want to do. Uh out flush is going to be the end. This is not going to be the right number of samples. But now we should have an audio. wave. Uh, and if we now do, didn't I install a thing for this? But we could do hex dump. That's fine. Um, audio. wave. Okay, actually what am I doing? I can just print out these values as they come. Uh so we can do uh amplitude is this and then here we can say amplitude 2LE bytes and then we can print line amplitude. Yeah. So if you see it goes -60 0 60 0 - 60. So what we end up with is a wave, right? So in the time domain we have a signal now that goes between -60 and 60 and it goes in a u I mean without visualizing without setting a reference for the actual time it's hard to say what it actually produces, right? This is clearly a wave because it goes up and down and the amplitude of the wave is here sort of the highest amplitude is um 60 and the lowest is minus 60. If we changed this to let's see be at uh 80 instead. So this would be a higher frequency. We should expect this to move more rapidly, which is hard to tell from this, but if we had a plot, we have a plotter. Uh what did I call it? Dings. H I forget how dings works. We built this in another stream. Oh no. Dingsh. Oh no. Uh, dev tools. No. Streams. Dings. Get pull. No, I don't want to do that. Why does it need my Okay, fine. Um I'm trying to remember what the arguments to this was. It was like ah x is row but I don't actually remember what we set the configuration arguments to. X is row opt. Oh, args. Uh, X's row gets set on by dash X. Okay, things dash no dash X not yet implemented. What? Clearly, we did not build uh things well enough to like why won't it just because this is a completely useless plot. Oh, it's No, actually it's not. This is actually plotting the right thing. It's just that you don't see the line in between them, but it is a thing like that. So, in fact, here let me try a lower value. Let's go down to like 10. Right. So, this is a wave. Yeah, that's not particularly helpful, is it? Um, if we did, 124 instead. Not particularly helpful, is it? There's not enough width in the A. If I did fewer, it's because my terminal isn't wide enough. So, if I do uh dashw 128 is that is it not - we set to be the ah dash d 128 by 80. Uh, it didn't like that at all. Fine. 80 wide then. I just want to plot it. Oh boy. Frame. There's a bug in our thing somewhere. min x max x I thought this was like self adjusting. Clearly we have some some way to go on this one. Uh 60 80 the len is 41 but the index is 120. We could clearly do better here. What if I just g plot it instead? Uh, and do dash e plot one. Oh, it's been so long since I used canup plot for this stuff. Um how do you um can you plot uh single column of input? Next stream should be to finish. It's true. Uh to finish things uh ah it's like plot dash using one using pseudo columns is what I'm after. I want ah colon one x range is invalid pretty sure there's a way to tell new plot. I thought it was fine to just say using one, but it doesn't want Oh, wait. What? We're panicking. Panic at line 71. Oh, that's because this now has way fewer columns. Oh, so maybe then Dings was working just fine. Things Okay, great. So, things wasn't the problem. It was I just misread it as where the Okay, great. Cool. So, this is a plot where we set like let's do a low frequency. So, here you can see the waveform, right? So, you see this is the now you can actually see the waveform. Uh, and I think I can do m like dots. Is that the uh args? Oh, dot. Well, okay. All right, settle down. Okay, so um that's this one. If I made it even lower, so if I said one, you'll see the waveform is much longer, lower frequency. Um if I make this higher, and there's sort of a limit to how high I can make it before it becomes inscrutable, but you'll see this is a much sharper waveform. So again, higher frequency. So this means that it is working. the transform is working um the way we would expect it to. Um and then now what we need to do is set the um so the length of the window that we're trying to um uh trying to turn this into. So let's say we wanted to generate 1 second of samples, right? So we have samples per second is the thing we know we want here. that is the number of samples we want to generate per second. So this is 1 second of samples. Um and in that second of samples we want um so the question now is what is the key here? Um if we print out here now uh spectrum. len len without setting 30. Oh uh as you size please what? Oh yeah don't print the amplitude please. Um so we have 22,000 frequencies and the question is what is the lowest frequency and what is the highest frequency? Um, and I think the frequency here is, and this is where I need to go back to the to my thinking, I think to my not to go back to my thinking, um, school days. Um, I believe these frequencies are like one over the sample rate spaced apart. So like um for example, so spectrum of one would be the waveform at um 1 over uh 44. 1 one. Okay. Isn't there's a formula for this? I think this is where I need to go back to the ah maybe this has it actually. Okay, that's not helpful. one hertz. Yeah, one cycle. It's one cycle per interval. And because we've set the interval to be a second, then one here is the wave that has one cycle per interval. So one a frequency of one hertz. This is the one that has two cycles per interval. So, it's two hertz because we've set the interval length to be 1 second. Um, and so if we wanted a tone at um what's the frequency of uh this is something I probably should know off the top of my head, but like a pure a tone online tone generator. That's not actually what I wanted, but sure, 440 hertz, why not? So, we want that. We don't actually know what um amplitude we want, but let's just say minus 30 for now. And then we'll bump it up as needed. Uh and then we'll get now we actually want to write these amplitudes out. Um and then let's cargo run. Okay, so we now have a file. Um but this is for one time segment, right? And so what we actually need is uh for interval in uh duration in seconds we need to do this. Now this won't be quite right because there's going to be a uh discontinuity potentially at between the end and the start of an interval because we're just starting the tone over. But I think that's probably okay. Um, U32 is not uh zero to duration seconds and we don't actually need interval and this all right let's see file audio wave okay riff little Indian data wave audio Microsoft PCM 16bit mono 44100 htz okay that seems good f ofmpeg- I says there's a 10second audio in there. That's what we tried to generate. Bit rate we don't care about. PCM signed 16 little Indian. Yes, that's what we have, which is what the format we specified was. So maybe this works. Let's just see what happens. Audio wave. I hear a tone. It's very low. It's very very low. But it is there. Let's go. No, that's too much. And I think this is in decibb. Yeah. Okay. Let's generate again here. Let's try again. This is should be quite a lot louder. Not Let's There's definitely a tone here. I I swear I hear it, but I feel like now I hear it less, which is confusing. What? Yes, I hear it now. But if I made it if I make it louder, it gets quieter. Like, can you hear it? It's not just me. Let me see if I do like 120. There's clearly a tone. Okay, let's go. Let's go more, right? But why is more negative louder? Isn't the input of an inverse f of the amplitude and not decibb? Yes, I think that's true. But that still doesn't explain why more negative amplitude. Oh, this is probably linear scale. It's not decibel scale. That could very well be. That's a pretty clear one. But I'm still not sure why it's negative, right? Because Oh, maybe it's the same volume when it's positive. Okay, good. So, it's actually just because if you flip the amplitude between minus a,000 and a,000, it's the same wave. It's just out of phase. like when it technically when it starts like when it's at its maximum compared to minimum shifts. Um but we don't actually care about the phase of the signal here because whether the like the sine wave goes back and forth like 440 times a second and so whether the the peak of the amplitude is at you know millisecond zero or millisecond whatever the like a few milliseconds later we can't hear the difference. is still the same tone. This is what I mean by phase. And that's the thing that the Rust FT would give us uh is it would allow us to capture the complex signal which means also setting the phase. Real FFT just doesn't let you set the phase which makes the interface nicer and we don't care about the phase. And so this is but we can change the phase by switching the amplitude but we can't switch it any further. Okay. So what this means is this is amplitude. It's linear amplitude. Um, so if we now make this two, it should be twice as loud. Well, it is louder. I can't tell you if it's twice as loud, but it is definitely louder. Okay, so we now have an A tone. Great. So now we have a way to go from the and there's no discontinuity. At least I didn't hear one between the seconds. That's probably because the we say one cycle per like it's a the number of fluctuations per cycle is going to be um like you'll be off by so little that I guess you won't really hear the difference. But let's try to make it like a much lower one like 67. Yeah. So, it's a much lower bassier tone. And if we do like uh four times 440 modem sound that really reminded me of a modem. That's funny. Uh so, we don't need the complex and zero. Oh, yeah. It's not actually it's linear in amplitude but as someone pointed out in chat too because of our perception of sound which also varies by frequency uh the amplitude doubling does not mean it's twice as loud because our hearing is basically logarithmic. That's why we use the decibel scale for actual uh volume. So in order to make it twice as loud you need to someone saying 10x the sound like this would be the decibel scale. I don't know if it's quite that bad, but it's something like it. Um, okay. But what we now have is a mechanism to go from um frequency assignments to time assignments. So now we get to the definitions of noise. So if we go to colors of noise and we look at white
Implementing white noise
noise, whitenose is a signal named by analogy to white light with a flat frequency spectrum when plotted as a linear function of frequency. So in hertz in other words the signal is equal power so amplitude in any band of a given bandwidth when the bandwidth is measured in hertz. For example with a white noise audio signal the range of frequencies between 40 and 60 htz contains the same amount of sound power as the range between 400 and 420 htz since both intervals are 20 htz wide. And what that looks like is across the frequency spectrum the amplitude is the same across all the frequencies. Well, we have a way to do that now, right? So, we can say um for um uh what we're going to do here is amplitude in mute spectrum. We're going to set amplitude is and let's do something not terribly crazy. Let's do cuz let's do something like let's start easy with 256 into. So we're now going to generate every frequency at the same amplitude and then overlap them in the time domain and see what we get. So, oh, uh, oh, it didn't like that. So, this is interesting, actually. So, this is the U16 conversion is now failing because it's telling us you're trying to give me an amplitude that is outside of the U16 range. Uh, and why is it doing that? So let's do let okay amplitude equals this else. Still going to panic uh or yeah panic and say um output amplitude too loud uh sample. Okay. So that looks pretty loud. Um, and the reason this happens is because when you have these like many frequencies, then whenever two frequencies have a peak at the same time, they amplify each other. And if you have more peaks and they stack on top of each other, it makes the signal louder. Um, and so what we need is to make sure that the amplitudes even when they when the harmonics like the repeat repetitions of the waves, even if the peaks line up between different frequencies, they still don't sort of blow the speaker. Um, and there are mechanisms you can use here, but we're going to try to just lower the amplitude of every frequency such that even if they add together, they don't add that much um actual value. Still too loud. 10. Still too loud. One. 0. 5. Cool. I worry this might still be very loud. Just a Let's Okay, that wasn't so loud. Where do I like That's not That doesn't sound right. Yeah, there's a clicking. But why is there a clicking? I think what you get is you now only hear the harmonics because all the others are too quiet. So what if Okay, what? Hear me out here. I just worry this will be very loud, but maybe not. I think so. There's there is something we could do here, right? Which is Oh, yeah. Okay. We could also open the file in um Audacity. Let's try that too. Um but let's do unwrap or else I64 Max. So that's the other thing we can do. But let's first uh Audacity. See what happens. Okay. And let's open. Oh, there's too much stuff in here, isn't there? Now you get to look at all the files I have. Very exciting. Uh, streams and trough and audio wave. Audacity detected this file to be 120 beats per minute. Would you like to enable music view? Sure. Okay. Yeah. So, you see every second there's a peak. What? How far can I zoom in here? Interesting. Ah, I think what happens here is all of the signals start at the same time, right? Because we've set uh or do they start at zero? Yeah. So, I think that's exactly what's happening. So, I think we in fact do need to cap it like this. Uh, I 16 max. I'll unwrap more. Let's hope it's not loud. Okay, we still get the same harmonic. This is still not right. Why are we Oh, I wonder if spectrum zero needs to be zero. No, if you don't randomize faces, you're generating an impulse function. Oh yeah, exactly. Because at the they all start with the same phase. So at second zero, they all have maximum amplitude. But I feel like there should still if we cap that one, the rest of the signal. Why does signal cancel out? Okay, so I think we have audio specialists in the chat who say they're canceling each other. And I'm sure there's a reason why that my math brain is not up to understanding because I haven't learned this stuff. But this does mean we need to randomize the phase which in turn means aha we need to use the actual uh FFT thing and not the real FFT thing because we need to adjust the phase which we can only do if we use the if we have access to the complex settings which let us change the phase separately from the amplitude. So we will do that. Um so if we go back to cargo toml we remove real fft uh and we use rust fft planner and then we say this is going to be an FFT planner new um and then we also need to bring in complex numbers from here. Okay. Right. And now this I guess has to be complex F64. Okay. So I can just make it be new. All right. Oh, I see this make input ve we don't get to do anymore. So that means we have to Oh, I see. So with real FFT, it would like tell us what size the input vec and the output ve should be. This one will not. All right. So, how about we do how about we go back to what we had uh and then we print out spectrum. Len and we print out time. len. len and then we get rid of these make this be rust fft numbum complex complex. We go back to making this be the FFT planner. And now when we use their FFT planner, we have to create the buffer. And this one needs to be then this plan returns trait object trait. It also exposes individual algorithms. We don't need that planner. I think that's because harmonics of a wave are aligned and every wave has almost infinite harmonics for what we're concerned because we're setting basically all the frequencies I suppose but it feels like there must be a must be something more isn't it like a sequence of number except for prime number of frequencies they all divide and cancel each other maybe I don't know. Um, okay. The constructor detect available CPU features. Computes invert FFTs of size len. But what's interesting is it seems like I can create inputs of any length, but the real FFT thing specifically suggested an input ve. How does it know the input vector produced? So if I say uh plan inverse make input ve I want to see context to real uh source Well, our FFT is even. So, it gives us an even. So, what is the implementation of even for even? So, there are a bunch of optimizations looks like it actually does. Make scratch complex zero self complex len. So yeah, the input vec where does complex len come from? Complex len. Oh, divided by two plus one. I see. So this is samples per second divided by two plus one, right? So this is the Nika Shannon, right? Like the these are the the frequencies we can capture with this number this sample rate expected us find a U32 right as U size. Uh, so we're setting this all to be zeros. Doesn't actually need to be a vector. Can it just be this? Um, and then this is going to be spectrum the output Ve uh time is just going to be a ve of uh zero of length samples per second and then we process. Right? So if we go back out now to here. Oh, it processes the buffer. It processes it in line. What does process do? Oh, output order. FFT planner plan inverse. I see. Yeah. Okay. ah convenience method allocates a ve with the required scratch space and then calls process with scratch. So if we call process it is in place but it internally allocates a vector. If you want to reuse the same allocation across multiple computation consider process with scratch instead. Okay. So, uh let's then do um scratch is going to be vec um. Oh, interesting. No, in place is fine. Yeah. So it will actually tell us with capacity um is going to be R2. Actually this is also wrong right? This is be C2R because it goes from the complex frequency domain to the um to the real space of time amplitude. Um, and we want to use C2R dot get notes. What's the helper called? Get in place scratch length. len. And then we can say process with scratch of buffer and scratch. Ah, but I actually want it to not be in place because I want to keep the spectrum for the next iteration. Now, technically this doesn't matter because we're generating the same samples in every cycle. Um, right now at least we are, right? So, we could just generate one second of sound and just repeat that second over and over, but if we do that, the noise will sound the same every second. And I actually want to randomize the noise as we go. And so, the way we would have to do that is to change the spectrum for every call. Um, and the way we'd want to do that is to change the not the amplitude, but change the um phase of every complex sample. But that means I want to keep spectrum. So I don't want to do this in place. So I actually want this to be out of place with scratch. Uh which means time is going to be with capacity. Um C2R. get uh this should be out of place scratch length. This should be um zero of length samples per second as you size and then this is going to this takes input output and scratch. So mute time and scratch right. Oh why is the output complex as well? Okay, that's fine. It can be this uh like so. Uh expected this expected ah this one. Uh so scratch it expects all of them to be slices. Uh so that means we can actually do mute time. So now this and this go like that. And scratch is going to have to be scratch dot set resize technically. Um this with uh zeros or is scratch also complex probably. Yeah. Okay. This feels like we can actually change we can create a const complex zero is actually there's probably a trait for that. So I suspect we can do zero. Yeah, great. And here complex zero. And then for all of these we turn them into a slice and now there's no result time is already an array. Uh this is now a complex right. So now the question becomes in the complex things we send in we need to set the phase and so amplitude and the phase. Um yeah and the when you have the complex number um you have the ability to set the phase and the amplitude and a complex number as we all know is a a value the value sure um that has two components. It has the real part and the imaginary part. Um and the amplitude is if you imagine that you draw a line in this space in this xy space. Um the amplitude is the length of the line and the phase is the angle of the line compared to the positive x-axis. I don't know if this is flipped for you but whichever way it is. Um and so and the real f oft thing hid this form from us. So we didn't have to think about it but we do now. And one of the ways you could do this is right, you could just set the the line to be an a real component of zero and an imaginary component of your the amplitude you want or a real component of as a and an imaginary part of zero. And if you do, you will end up with the correct amplitudes, but the phases will all be zero. What we need to do is we need to actually randomize the uh the angles the phases but keep the same um keep the same magnitude of the vector if you will uh in that space which means that they can no longer be like this. Instead it needs to be and there are faster ways to compute this too but for each thing here so for each interval we're going to have to do this again. Uh although we could do it now just to No, we're going to do this properly. Um so we're going to do cargo new uh no cargo add rand. Um then we're going to say let mute rand is rand. Uh, and inside of here, I don't know if it matters what you have in zeroth position here. Let's find out. So, we're going to say uh we know the amplitude we want is let's say a th00and um and then we want for frequency in the spectrum. What we want to do is we want to set the real and imaginary parts of the value for that frequency and we want to set them in such a way that the angle is random but the magnitude is the amplitude. Uh there's num complex from polar. Perfect. Okay. So uh complex so we can do frequency uh is complex from polar. Uh so polar is a different way to specify coordinates. So if you have a value in a cart cartisian uh coordinate system so xyz for example uh you can specify the coordinates of a point or a vector by giving the x and y coordinates or you can give polar coordinates which is angle and length. Uh and that is in fact exactly what we want here is we want to give polar coordinates which has r and theta. Um where r here is the radius. So the length of the line which is what we want to be our amplitude uh and the angle of the thing which is what we want to be random. So here we can do rand dot uh random uh and this will generate us a completely random number of the type that we need. And in fact, it's totally fine to give, let's say, a polar angle of, I don't know, u, you know, 4,000, even though I'm assuming this is probably in radians, although it isn't typed. Um, then it would just be, you know, lots and lots of rotations, but ultimately the trigonometric function. So, this ends up using a sign and a cosine to compute the x and y coordinates. um we like those function they function even if you have angles that are super high they still compute correctly based on like 0 to 360 or rather the their output values repeat as the angles rotate. Um and so we're totally fine giving a completely random number here although we do need to tell it to that it should be an F64. Um, we may also, the only problem with F64 is I forget whether it can generate nans and stuff. Oh, someone put it out in chat at the same time, too. Um, I don't think so. I don't think rand random generates ns. I'm like fairly certain. Um let's see. So if I say rgx random uh where standard uniform here we go floating input types are uniformly distributed in the halfopen range 0 to one. Well, that's actually better for us. That's good. We checked uh because this means we can just do times um standard F64 const uh towel. But let's double check that this is actually radians cause function in radians. Okay, great. Okay. Uh, don't you need to process FD after setting spectrum to get the proper samples? Yes, I do. So, the other thing that needs to change is we now need to recomputee these inside the loop. So, previously we'd comput it once and then we just take the output and print it many times. Now that we want randomness, we actually need to randomize for every iteration. And so, this now goes in here, but the scratch stays um can stay out here. So, this goes here. Um, we now have this. We compute these and this and the scratch rand generate a random phase but a set amplitude. Uh, let's make this amplitude much smaller. And now I actually think we might not get the same harmonic. So we might not need the clamping. Um, although it is kind of random. Now the other thing that we're going to get out now is in the time domain we also now get a complex number out. Um, now I wonder whether so in the time domain what is the do we care about the phase of the output? I don't think so. So, I think we can just do um this is a complex. Yeah. So, I want the Is there a way for it to give me the Yeah. Same as norm, right? And I assume abs and norm return the same thing. Okay. It doesn't show me what abs is. Yeah. Uh cannot mutate immutable variable. That's true. Okay. Um let's see what happens if we try to now run this. Uh you do not need to make it negative if face is between 0. 5 and one. Oh, you can just take the real parts. Really? Uh no norm should give you the magnitude of the vector, right? Am I being stupid here? Like I want the Let's see. Num traits complex. What? Uh where do they get complex from? Here. Oh, numb complex. I see. Uh, show me what you got. No, I don't want scale. Yeah. Isn't the norm just the uh I thought the norm of complex number is the magnitude right from a real complex vector space to be to the non- negative real numbers to behave in certain ways like the distance from the origin. Yeah. Okay. So it is norm cool. So let's run it and see what happens. And now we don't need complex float either. Uh provided FT input buffer and output buffer must have the same length. Why? Interesting. Ah, I see. So, let's fix two things. Uh, let's fix two things in order here. First thing, um, this apparently needs to be the same length. But why did the other the real FFT thing did not require them to be the same length? Oh, probably because it was operating with reals, not complex numbers. It's either that or Yeah. Okay. So, this needs to be the same length now. Okay. Uh the complex out will either be the rectangular form using s and cosine as the basis or the polar coordinate where you only want the real part. For real signals, negative and positive frequency components are related. So you only need positive frequencies. I see. Okay. But now because we are giving the uh the full complex including the phase we actually need the um uh we need the full length. That's fine. But now the other thing that's interesting here is the output here. This is always a positive number. In fact, I yeah, but we're that means we're not making use of the negative numbers in I16s. And so what we can do to make the full use of I16s is we take it as an I64 and then we subtract um we subtracted by the I16 or we add the I16 min realistically, right? Because the min is a negative number as I 64. And so that way we get more range. Oh, that's a re that's a really loud amplitude. Okay. Oh, wait. No, it's just it's not actually that loud. It's just a complex number. You start with a real signal in the time domain. So just take the real part. Yeah, we're not starting with the real signal. We're going from the frequency domain which is complex. Let's see what this sounds like. Um, but the thing that we're still going to run into is we're still we still now have the possibility to peak the spectrum like peak over I16. Um, which means this still needs to be this. See what happens. That was pretty loud, but that kind of sounded like white noise. 32. Still pretty loud. 84. Yep, that's noise. That sounds like white noise, right? I'm like the volume here is hard to control. Okay. And then if we go to Wikipedia, Wikipedia white noise. I mean it's different volume, but that those sound very close to each other. But yeah, there is a pulse. But I Why is there a pulse when we're randomizing the phases? But why is there an in Oh, is the impulse because of um of spectrum zero. No, you have a massive DC offset click at the start event because of taking the norm and adding I6 min. Why does that make a difference? I guess part of the problem here is I don't actually know what the complex parts of the signal is. So if I take the real instead, what happens? That was way louder. Uh, still very loud. Uh, 0. 5 still very loud. Why? Just take the real part once. Oh, just I see what you mean. Take I understand. Uh what we want to do is take the I see the real can also be negative. So we want to don't want to subtract I16 min to a number that's already negative because that would make it way louder. So we want to take this Okay. All right. So, as i16. Then we want to clamp it to i16 min value and i16 max. And then we want to cast it to I16. Oh, as I 64. Normally, you want an envelope to ramp up and down. Otherwise, the first random sample is just a sharp change. Yeah. I mean, because we're generating random noise, right? The first whatever the first time signal is suddenly has a bunch of volume. As a result, the speaker has to like blast to hit a sharp edge in the audio spectrum. And so that start is going to be uh severe. So, we could apply fade in and fade out. We can do that. Um, but that's boring. Okay, now this is way more reasonable. Let's go back to 12. All right, we're back to white noise. And is there still a I don't hear the impulse as much anymore. Okay, you want to look at the uh print line. Uh sample imaginary. Is there anything in there? There is stuff in the imaginaries. But we're just ignoring that for now. Um, okay. And then if we want to, if we really want to, what we can do is let mute. Um, dampen. Like if we want to, if we want to fade in and fade out, um, we could do is, uh, Trying to figure out how I want to do this. I think what I'll do is um let's do like minus 100 and then we'll say uh amplitude is how do I want to do this uh minus 1. 0 zero and I want to say plus equals amplitude times dampen and then dampen is dampen plus 0. 1. There are fancier ways to do this for sure. Um min of that and zero. Fine. Uh, this will actually be this guy. amplitude is a real poor man's uh fade in. Why is it unhappy with me? Ah, no, I want times. That's not That's not at all what I wanted. Uh I wanted this amplitude plus amplitude which is really multiply by one plus dampen. Right. I feel like that should work. So we take the amplitude, we add amplitude times dampen, which starts with minus 1. 0. So that should be zero amplitude. And then we increase dampen by a little bit all the way up to zero. When it hits zero, it'll stop incrementing. And so then amplitude will be amplitude plus amplitude time zero. Oh, but I have way too many samples per second for that number to be sufficient. There we go. Okay. Yeah. Okay. Beautiful. Uh your complex signal needs to be symmetric if you want to get zero lm imaginary component. Imaginary is not zero since when you start in the frequency domain the spectrum has to be anti-ymmetric to get a real signal. This happens automatically if you start with a real signal. Right? But we don't And so therefore the imaginary part is non zero. But that still makes me think we should be using the norm here. But I guess because it's random noise, it doesn't matter. Um but regardless, this is clearly white noise. Sounds exactly like white noise. So we successfully have white noise. So now I'm going to argue the question
Pink noise
have white noise. So now the question is, can we make pink noise? The sponsor of today's video and the first ever sponsor of the channel is Hudson River Trading. HRT is a quantitative trading firm using the latest advancements in machine learning, high performance computing, and systems engineering to make trades in over 200 global markets. They pride themselves in having a deep engineering culture and a relentless focus on performance. HRT is primarily a C++ and Python shop, at least for now. But the kinds of things that draw people to Rust in the first place are exactly what they're facing daily, delving deep into the lowest levels of their hardware and software stack, including instruction set optimization and compiler tuning, all whilst meeting strict correctness requirements. They're hiring in offices across the globe right now. And if you're interested in joining, check out the link in the video description to learn more. Noise. The frequency spectrum of pink noise is linear in the log scale. It has equal power in bands that are proportionally wide. This means the pink noise would have equal power in the frequency range 40 to 60 Hz as in the band from 4,000 to 6,000 hertz. Since humans here in such a proportional space where doubling of frequency is perceived the same regardless of actual frequency. So every octave needs to contain the same amount of energy. Interesting density proportional to 1 over f. So I think we can just compute that right. If the density is proportional to 1 / f then we can just compute that here. So what we actually need is we need to start looking at what um doing some argument parsing. Uh noise is none or kind is none. Um then we're going to match on stood and args nth uh one zero is the name of the program. Um and if we get brown if we get white then something. If we get brown then something. Uh brown is to-do. Uh actually anything else is to do. Kind noise not supported yet. So for white noise, I think what we need all of these to be our functions. So, I think what I'll do here is actually pull this out um and say that this is going to be a noise and it's going to take how are we going to do this? Spectrum setup is going to be an FN mute of a mute of complex of F64. Right? So, it gets to change the spectrum setup for each block. And for now, that's probably good enough. Um, and then this is going to be noise of spectrum. Um, and that's going to be simply this. And I guess we'll give in the RNG as well. Okay. Uh so this will now say spectrum setup. We'll be given the RNG and a mute to spectrum. Oh. Uh, rand. Sure. Let's call it RNG. Why not? Uh, and it needs to be mute here so that we get to call it as an FN mute. That's fine. In fact, we don't even need to pass in the RNG because there's an FN mute. We can now do this. Uh, I can create the RNG out here. And then this gets to borrow the RNG, which is fine. Um, cool. And then this has to end with. Okay. And then pink noise we don't have a definition for yet, but we will shortly. And now it's upset about something else which is ah sum of this, some of this. Sum of kind and none uh sure none is white noise. uh dot as dref so we get it as a stir instead of as a string and then this is upset because the cluster is expected to take two arguments we don't need the RNG anymore and then this is upset because can I find amplitude yes because amplitude can also now come out of here uh and this no longer needs to be this and this is now RNG. random and kind isn't being used. Excellent. Uh oh, you want to see the spectrum? Sure. Audacity. Stop showing me this. Thank you. Uh audio wave looks a whole lot like white noise to me. Can I view it? Spectral selection. I was trying to see if I could uh surely there's a way to show me the frequency analysis of this spectral. I don't know. Uh, there are audio engineers now debating in chat whether we should be using real or norm. There's an FFT in there somewhere. Um, okay. So, right. So, for pink, what we were saying was the um the amplitude should be inversely proportional to the frequency. And so uh iter mute. enumerate. So this is going to be yeah this is like this should really be max amplitude right and then this should be this should say amplitude because that's what we're actually iterating over. Uh no it's actually sample I guess it's not sample it's um what do you call the constituent parts of the frequency domain spectrum frequencies I get I maybe they are frequencies fine frequency um but it should be the max amplitude ude, Oh, they're called bins. Aha, thank you for bin. Um, we want this to be inversely proportional. Oh. Uh, to select specttogram view, click on the track name. Okay. Aha. Spectrogram. Ooh, but also not particularly helpful. Although, interestingly, not quite what I would have expected, right? I would have expected to be more uniform if it was white noise. This seems to have more amplitude in the Oh, what am I? What's happening? Oh, I see. I get to select like that. See, now someone's just making up words. Ah, if you don't make the spectrum hermesian symmetric and take real at the end, you essentially divide the amplitude by two. You divide signal power by square by the square root of two. Interesting. I I'll let them keep debating in chat exactly whether we should be using real or norm and then in the meantime we'll get some stuff done. So this is suggesting that it's simply a one over frequency. That feels like it's probably not true, but we got to start somewhere. Um as F64, let's just see what that looks like. So in fact um let's open the audio waveform now and let's see if it looks different spectrogram it does it sound different pink dot it shouldn't because I didn't pass in the argument so of course not white. wave wave and then I will cargo run um pink uh move audio to pink. wave and we'll play pink. wave. That makes no noise. So that feels incorrect. Ah, but the um the amplitudes are going to be off here because with pink noise, I feel like the amplitude has to be higher because we're adding the slope. You end up with very little energy at the on the higher frequencies. So I think the max amplitude probably needs to be per thing. So if this let's say this was 128 Yeah, there's something here. Um, more. Okay, this thread, this needs to go away. But that doesn't sound like pink noise. If anything, that sounds like brown noise. Oh yeah, we are dividing by zero here, aren't we? Uh for FFT it's main toolbar analyze plot spectrum. Okay. So back to waveform and back to waveform. So I select a bunch of stuff. Main toolbar analyze plot spectrum. Aha. Oh, well this is interesting because at the lower ones With a linear frequency, they're straight. With a logarithmic frequency, they're not. Huh? Why? This is for the white noise. By the way, you should convert frequency index to frequency. After midway, the frequencies become negative. Oh, right. Because this is the uh this is the part where we could also just go to samples per second divided by 2 + 1, right? Why am I not allowed to index this? Oh, as you say, why did that noise suddenly go up so much? Oh, it's after the dampening stops. That's weird. Oh, you're right. hard to analyze low frequencies because it's the average over the track length. There's only 10 waves of one hertz in the file, right? Because a one herz signal is 1 second long and so 10 seconds, you only get 10 of them. But why? Like, okay, this is going to be loud. So, let's make this be down to eight. Maybe it gets louder and louder. when I only go across half the spectrum. The fre someone said in chat that the frequencies go negative once you go past the halfway point. Yeah, I mean I'm ignoring pink for now because I think that the scaling by herz here is probably too strong. This needs to be something else. But but even for white noise like Okay, let's um No, I don't need to save that. But thank you. Um, so let's Whoa. Okay. Well, I think I see the problem. Uh, plot spectrum, but okay. So, we have way higher volume in the highest. But why did our white noise changed? because spectrum is set to zero all the way through. And now we change it to only set the first half of the bins. And then we get this property. Why are there negative frequencies and why does it matter? Um FFT negative frequencies. See what the internet can tell us. Uh why are there negative values in the output array the second half of f array is the conjugate of the first half doesn't contain any new information. Ah, but we are not filling it as though it is the conjugate. So how should we fill it? I see. So what this actually means is we need to set can we simply automate this down here and say um can we simply down here do this and then do pause negrum dotsplit atmute And then give in the positive things to here and then for bin in the negative. Um mute. inumerate Enumerate set bin is can I simply negate positive I No, it's the other. It's uh at least based on this. Yeah, you get minus the next one. This is where the madeup words become important. Yeah, I know. It's true. Um I see. So the output here is a it's mirrored at the center. So this would be it would not be I it would be the negation of uh pos. l about len minus i minus one real parts mirrored imaginary mirrored and negated time for gamify the off by one area I Oh yeah, that's the other way to go to do it is to say um I see instead of enumerate we could zip with pause iter rev and say that this is simply Then this and it's not just negation. Someone said it's the conjugate. Yeah. Okay. And am I right that this is the split out? Like what's the setup for split out mute? It's Yeah. So pause will contain everything up to but not including the plus one. And then the negative will contain everything following. And I think that matches this two, right? So yeah, I think that's right. And now the belief right is that assert sample. im or assert sample. im M is complex no is zero right that's the belief one bin will not be mirrored that is the zero herz bin yeah which is fine because we're iterating over neg here which will then be have one fewer elements right it's unhappy with me because it does get imaginaries. Yeah, it won't be exactly zero. It'll just be small, but it's not I mean it's five. How about we say it should be less than 10 otherwise print out sample. in. How's that sound? 10 sounds like a very big number. 20 sounds like a really big number. 32 64 should be a really big. I think you're a lion. 256. Oops. 256. Yeah, it's not that small. Okay. So that means we've messed up here. So I think this means we're off somewhere here. Let's try plus two. No, let's try not plus one. Oh, this should not have this anymore. This should now just walk over spectrum. Uh, but it shouldn't set the zero hertz one. Although it doesn't matter what it's set to because zero herz. So it has no uh waveform. So arguably here we could pass in actually maybe that's a good idea we could do this. Um so we spit it + one. We skip out the zer bucket but this should still be right. Oh, the zero herz has to be real. That's fine. So, we say that to be zero. But Something's wrong. Split admute a samples per second. So this is 41 40 44. 1,000. divided by 2. So that's 22050 plus one. But if we think of it as I think it shouldn't have the plus one because of the zeroth index and I think the plin neckline. Yeah, because now they're the same length. But the next thing that now gets weird is that the last negative entry now ends up being the conjugate of the of zero hertz. Is that right? I don't That doesn't look like it's right. It should be the conjugate of this guy. Yeah. So, we're iterating over pause going from zero hertz to 22,000 hertz. And then when we go over 22,000 hertz, we go to minus whatever 44,000 hertz. But that what should that be set to? Because that can't be set to the conjugate of the one before. It makes me wonder if this is like this skip one and that neg zero also needs to be set to zero. Yeah. Now, how small are they? Yeah. Is it less than two? one? Yeah. Is it less than zero? It's not less than zero. It's very small. Great. Okay, this makes way more sense to me. And see, I got it without knowing audio. Well, kind of without knowing audio. Uh okay. Yeah, because this one neg 0 if that's minus 44k it Yeah. First try doesn't make sense for that to have any amplitude to it because you can't represent it in the signal. At least in my head this makes sense. This makes more sense now. Okay. And in fact, maybe this one doesn't matter. Yeah. So this is the skip one that matters is that the conjugates get set after that one. I think this one also realistically probably does not matter. But let's find out. So if we now if we run this neg0 is 22050 hertz. No, it should be negative, right? Otherwise we've messed something up. Are you saying this should be + one and that this should be zero. I don't think that's right. I think this is accurate. It's the because we removed the plus one. Okay. I'm worried about the volume now. What did we set the volume to? Eight. Okay. That's been our friend in the past. That sounds that sounds pretty promising. Okay. Uh, all of this analyze pot spectrum. That seems pretty white noise to me. Okay. And so now if we move that to white and then we for this pink well we let's go back to something less. Um it did say for pink noise decreases by 3. 01 decibel per octave density proportional to 1 over f. But that doesn't actually mean it's 1 over f, right? It's just proportional to 1 over F. Power density falls over at 10 dB per decade. Okay. An octave is the interval between notes which is twice the frequency of the vibration of the other. Okay. So each doubling of frequency should have 301 dB which is a logarithmic scale less power. So every time we double the hertz, we should have the power. But that's what you get if you do this, right? This one's already if hertz doubles then amplitude halves. Or is it power or is it amplitude? Pink noise. The power density, right? Whereas what we are setting is amplitude. As someone pointed out that uh power yeah amplitude should then be proportional to one over the square root of the frequency because power density is proportional to amplitude squared. Okay. So then this should be square root of this but the hertz here. So this is actually not quite right. Um because the should be + one and we want this as F64. Uh, pink. I hear something, but it's not very loud. I hear something. It's still not very loud. 64. Dare. I 256. Just that that's ours. And the zucchipedas, those sound pretty similar. to my uneducated ears. Let's go ahead and open that one. Well, that's a wonky signal, but that looks pretty good. That arguably looks way nicer than white noise does. Okay. So we move that to pink. wave. Uh so now I guess let's do brown.
Brown noise
Actually let's figure out how do we compute this. So with pink noise uh it's like if you look at like area under the curve as total power then this will be if we go halfway through the Well, but that's halfway through the frequency spectrum. If you go spectrum, so at like so that would be sorry halfway through the bins. If you go halfway through the bins, you would end up at like 10 kHzish. And there we would have square we would divide by the square root uh we would be dividing of so about 105 * 105. That doesn't sound entirely implausible. I think here here's an interesting question like if we pull this out and say max amplitude is eight and we say here our max amplitude is actually uh or maybe we should say average amplitude is maybe more accurate right um we want here The max amplitude to be the average amplitude multiplied by the square root of 22050 divided by 2. What? Why is this ambiguous? F64 F64 How I don't understand how this is an ambiguous type. Oh, it's because we're picking up squirt from complex numbers or something. Yeah, we're picking up from other places. That's not what I want. Can Do I have to like F64 this one? So now those sound like roughly similar in volume to me. So if we now do uh if we open white and then we open pink. I mean, they're not equal. Can I set this to show me? Like, can I Aha, it's currently linear in amplitude. If I zoom into this and I zoom into this, is there a way for me to like zoom into the amplitude? because that's really what I want to do. Ah, zoom in. They seem like kind of aligned now in terms of amplitude. It's obviously not perfect, right? Because it also depends on our perception of volume, which varies by frequency. So, the scaling won't be quite perfect, but I think this seems to be about right. Um, so let's then do brown noise. Yeah, for the feel you probably want um decibel. I agree. But let's do brown. Okay, back to colors. Brownian noise. Oh, sorry. Brownian. I wish it was a Brownian walk kind of noise, but it's not. Uh, is noise with a power density which decreases 6. 02 per octave with increasing frequency. So frequency density proportional to 1 over f squared. It's also called red noise. I see. So this one is even more aggressive about suppressing the higher frequencies. Oh, it does mention random walk. Brown noise is not named for a power spectrum that suggests the color brown. Rather the name derives from Brownian motion also known as random walk but how does it relate to brownian no walks doesn't say why doesn't it say okay but to f squared interesting so actually when we previously thought we were generating pink noise I think we were generating brown noise because this squared would just be this, right? And now it would be divided multiplied by this, which terrifies me. That sounds like a very high amplitude. Uh, at every it's related to a Brownian walk because at every sample, you take a random step up or down to get the next sample. Oh, you're saying if you did that, you would end up with noise that looked like this because we are still generating random samples here. 60B is one quarter the power is 1 over square 4. It's 1 over the frequency squared. And the relationship between frequency and power density What's the what's um in fact someone posted it further off upright that um what's the let's write down the rule power density um is proportional to amplitude squared also I can't spell proportional uh so that would mean that if the So that means the amplitude is the square root of the density. And now we want the density to be divided by the frequency in hertz. So divided by f which is where we get square root of 1 / f. So 1 /< unk> of f. That's where we get that modifier from. But if we now want this to be density over f2, then wouldn't it just be the right? It would just be one over f. Yeah. So it's not Yeah. Okay. So it is this which is what we originally did for pink noise. Yeah. So our original pink noise was brown noise or brownian noise. Instead of converting from polar, could you multiply by random scalers of I? Oh yes, we could actually. Um that's a good point because when you so let's take a look at this. So uh complex number multiplication. So when you multiply complex numbers, no, that's not what I want. I want this. So if you multiply by I, you're actually rotating the complex number. And so what that means is if you multiply by so we could multip we couldn't just multiply by a real number like by a scalar but I think you could multiply by a scalar imaginary to rotate to basically an arbitrary amount. And so if we picked a random number and multiplied by that much I think you'd be rotating which is effectively changing the phase to be random without changing the amplitude. And so that way we would need to go back and forth between the um that way wouldn't need to go back and forth via the polar coordinates. So we could then just generate the polar coordinates once. In fact, we could just generate them with a face of nothing. Uh oh, I is always by 90°. It's e to the power of the scaler times I. That's right. In which case, I don't think this saves us very much. So I think I'm going to leave it the way it was. Um, okay. So I think that means we have brownie in, right? Okay. So if we do brown in that sounds wrong. Oh, that's because we're for brownian we are we're our amplitude is way off. And that's because our scaling ends up wrong here. Why does our scaling end up wrong because it goes to zero so fast. I think like if we did um if we did this and do a thousand let's say and do this uh so we had some clipping in there but is that because of I think it's cuz we end up interesting. What are those impacts from? Cuz this does sound like brown noise. Like if we go back to here and we play brown noise. That sounds right. Yeah. And the someone's points out the problem is probably that the lowest frequency component like the one hertz component it has so much more volume than the other ones that whenever it hits it ends up peaking and then you get that click. But I wonder why that doesn't happen here. And I wonder if that's related to the angle of the slope here. So, I wonder if you could make this better. Oh, it's Yeah, it's almost Yeah, someone I think you're right. Um that it's it could be one of two things, right? It could either be because of the one second bin. And so, if you if we you know, the one herz signal now that we're starting with a phase doesn't start and stop at the boundaries of the one second. it might start at like you know uh half a second into it and so it's actually at max peak when we stop the one second and then we just restart it at a random point in the face and you get these weird um these weird like steps. Um so so that could be one part. The other could be that the one herz signal ends up being such a big peak that we actually clip uh whenever it occurs. And so you get these sort of sharp things where you don't actually get the right frequency. So, one way to deal with this is uh for pink noise it was okay, but someone pointed out too just skip over the first like the low the very lowest hertz ship. Well, that sounded completely wrong. Yeah, attenuating the lower frequencies is the other way to do it. Uh, make the intervals one. Make the intervals 1. 1 and overlap. Oh, so they don't perfectly align with the um Yeah, wavelengths. Maybe feels like there should be a cleaner solution here cuz the other option, right, is to blend. But that feels like it's a now the negatives are not computing to zero. Um they should because we still have that assert in there that the imaginary part stays under one. Yeah, I mean let's if we now open this file like look at this. What's happening here? Because what's particularly strange here is that the wait why does why is this why does it start at one here. Could it be that we need to clear the output array? No. Do scratch? No. We're not in the musical mode anymore. Like what happens if I plot the spectrum of this linear frequency long frequency there's no internal state in the FFT I don't think that's why it has the scratch for example And we now set nothing for the first 20. does scratch need to be reset? Let's go read the docs for this a little bit. Divides input output what divides input and output into chunks of size self. len len and computes an FFT on each chunk. Oh, I see. So, if you provide you can provide inputs that are longer than the chunk length than the length you set for the FFTD, but if so, they will be processed separately. This method uses both the input buffer and scratch buffer as scratch space. So the contents of both should be considered garbage after calling. Oh okay. So we cannot reuse spectrum but we reinitialize spectrum anyway. Interesting. So then we're actually fine with this being in place. There's no real reason for it to be out of place. So, we can get rid of this and then say process in place. Yeah. And now, okay. Yeah. Yeah. And we're now skipping 20 of them, so we're not reinitializing them to zero. That's definitely the problem. Uh, so a couple of things need to change. So this needs to be in place scratch now in place scratch. This is now going to be spectrum and they're the same length. So that's fine. And then the challenge is going to be that this has to set all of them. So for bin in spectrum 220, bin has to be complex zero. And same thing here because otherwise they end up with garbage. That sounds a whole lot more pleasant. And now if we do this. Okay. So that's still peing. But that sounds mostly pleasant. There's I heard one click in there. It is interesting that this formula doesn't work. Like this made it way too loud. It made it clip. But why? Cuz this doesn't sound that loud, right? But if I make this 10k, you occasionally hear the clicks which um Whoa. Oh yeah, cuz we skipped the first 20 hertz. and it basically goes to zero at like 10,000 hertz. So, I wonder if the I wonder if this needs to be divided by four. I think that's actually right. like all volumewise I think those are about right and I think it's because as someone pointed out too the there's a the amplitude here is linear but volume is the is logarithmic But in any case, this seems okay for now. I'm fine with that. Uh I don't know if you can beat the clicks by just skipping the first 20 bins. By random chance, the bins might be really high at the end of an interval. Yeah, that's what I'm thinking, too. that it the clipping is probably not because of the 20 but because of the um edges but the edges do get worse with the longer waveform I think. Um and so there is an interesting question of how do you blend if we sample this in 1 second intervals how do we blend them better I wonder if one option would be that we don't fully randomize the phases but instead said, so we could cross fade or something, right? But the other option would be that we simply instead of changing the faces completely, we just randomly walk the faces slightly, right? In fact, does the face even need to change? I guess if we want the signal to feel kind of dynamic. So then, so then here's what we could do. So we could actually pass in the interval like which interval number it is. Actually, let's do that as the first argument. Uh, and then I and then we could say if I is zero then this otherwise oh but we can't do that because spectrum gets overwritten. But there was a process immutable while keeping input untouched. So that would let us Okay, I think that's the thing to do. I think we change this. Yeah. Okay? Cuz that also means we don't have to reset it every time. So we go down here, we say this is going to be get immutable scratchlin. Um, and actually this can now just be new because this resize is going to take care of that. Um and then here this can now become process immutable with scratch. But now we need the output again. That's fine. So that's going to be this uh mute time and time. This is now read only version of spectrum. Uh why is duration in second a U32? Sure that's fine. It can be U32. Yeah, we're basically doing a Brownian walk of the phases of the um of the frequencies. And so now and so here's the other thing that's interesting. I think this doesn't depend on the type of the noise. So I think we can actually do this, which is kind of cool. Uh, so all of these are just going to not get an I. And instead down here we're gonna say uh if I is zero then this otherwise uh and the conjugates probably still need to be computed every time. If the interval is zero then we call the setup thing uh otherwise we walk the bins from we walk all the bins. And then we uh and then we want to rotate the com. Why? Why does it not give me what cannot why is pause now considered immutable? Ah, sure. Bin dot uh and this is where we need to use the trick of rotating complex number and we just want to rotate by a random but small amount. No, that's not what I want. Yeah. So this is one way in which you can express the uh a complex number or any x y coordinate and this is the polar form. So it's the radius time e to the power of i and then an angle. Uh and it's the same thing for this one. So that should mean that we should be able to do bin and multiply it with um does complex have a an x as it does which is e to the power of um and then here we could say complex from polar uh can I give can I make a unit here? or no. Okay. Um of one and a random but small angle. Uh mute RNG is brand RNG. RNG. random. Um because we want to add we will rotate it by a very small angle. So how much is a small angle over next? We only want the imaginary component. Yes, you're right. So, this should not be that. It should actually be the real of zero an imaginary of this. Uh, but it's not between 0 and one because that this has to be in radians. Uh, and so how much would we be willing to rotate the phase by? And remember this is from one second segment to the other. And so this could be uh I mean we could do like why is this being unhelpful? const frack frack pi 8 that's the smallest one we have that's pi over 8 so it's anywhere from 0 to pi over 8 uh this has to be f64 Thanks, Clippy. Okay, so I think this should mean we now set up the noise by setting all the amplitudes depending based on what the um uh what the sort of scale tells us that noise should be like. So the frequency to amplitude and then we randomize their initial phases and then over time the phases will drift of the different frequencies but they will drift by a small amounts for each segment. So then they shouldn't there shouldn't be very severe clipping at the borders I think. Uh MPV bra MPV uh isn't X X< unk> * I * theta the same as just creating a from polar with radius 1 and theta. Uh that's probably true. So, I suppose we could do this. And I think that's the same thing. Yeah. No, that's pink. I didn't hear any clicks. That sounds pretty good to me. It seems maybe too loud though. I think the other thing is like is it repeating which is very hard to tell from this. Uh if I do uh add monot track I take three to four. No. Add motor track. And we put this guy under here. And then we zoom in. It's very hard to say, but are these the same? Remember, they should be very similar, but I don't think they're the same, right? But they should be similar. They just shouldn't be identical. So, let's take something from like the end, right? So, um let's do like I guess four to five as best as I can. because they should drift more the longer the thing goes on. Like look here for example like even if we say okay this aligns with that probably right like this we zoom in even more like these are clearly not the same like let's say these align I don't think these align at Oh, maybe this looks like it like used to be the same, right? I think this worked. I'm going to claim this worked. If the signal repeats every n seconds, then the spectrum of the entire thing should have a peak at 1 / n. Let's see. Uh, undo. Undo. Analyze plus spectrum. I don't see any significant peaks here. I think that worked. I don't I mean let's we can also brownian. wave. I don't Yeah, I think this is fine. We could make it uh rotate more, right? But if we do that, then we'll have more of the clipping. Yeah. You get more of the tears at the edges of the intervals. And I mean we could rotate them by even less to get less discrepancy. We could even rotate them not at all. But then you get the that's very clearly repeating like you can hear the same like pattern happening. Whereas with this Oh, I don't know. That sounded kind of repeating to me now. Oh, man. Now I feel like I'm just like slowly but surely losing it. Okay, someone keeps suggesting audio envelopes FFT. Can you rotate an amount proportional to the frequency? I mean, I suppose. Yeah, because I guess the lower the frequency, the less we're willing to rotate. So we certainly could do that, right? Because we could also multiply by the the hertz divided by 2250. So that way we'd be the higher the frequency, the more we'd be willing to rotate. So if we did hertz bin in pause it mute enumerate numerate. Uh I guess skip one as of 64. So this would scale the rotation such that only the highest frequency were willing to rotate by a full pi over4. But it's hard to tell, right? Because for a if we now have like a you 20 Hz signal and we're only reallying to change it by a tiny amount for each inter for each second then even a 10-second clip you might not hear very much actual rotation. So maybe now we should be willing to rotate by more. Now we're just trying to find patterns in noise. I don't think we're going to get a whole lot f farther than this. But th this feels about right. Okay. Uh, so now we have brownie in. Let's maybe add one more before calling it a day. Um, rotation limit could be based on power. It could also Um, although for all of these, right, the power, most of them have power that's inversely proportional to frequency. So those end up being the same. But for blue noise, that's not true. Uh, and so for blue noise, actually, this might make more sense, but let's um let's go ahead up here and say let's add
Blue noise
blue noise. So, blue noise is going to be blue power density increases by 301 per octave. Okay, so it will be more like pink. Um but it will be not divided by rotating a bin's face at a constant speed will move the bin center. Uh we're not rotating it at a constant speed. Uh we're doing a random offset. Um so for blue noise we want the frequency to increase is do we simply multiply by the same number? I think we do. Uh, this still ends up being that. No, it's still divide by, but it ends up being uh we need sort of a one minus here. We need a um yeah, we need to divide by the inverse. So, we need this dot squirt minus that which is F64 squirt because of the trait that gets brought in. Oh yeah. Or we could just reverse. No, reversing the iteration doesn't work. We can't just iterate backwards because the Oh, I see what you mean. Because the hertz I see because we would reverse the iterator but the enumerator would then go from the back. That works too. Okay. Sure. Well, but this feels nicer though, right? It's the same thing, but iterating over these backwards. So, if we did um rev is there an R skip? No, there's not. Is there? Uh, we would need a dot 20 rev enumerate. Yeah, that's that ends up right. So if we did this version like this isn't really Hertz, right? It's like it's the I guess it's inverse hertz. Yeah, I guess we don't need the skip because the low frequencies get um reduced by so much anyway. That or they end up with low volume anyway. Sure. All right. Fine. Fine. Yes. But now we might end up with really high volume for the high frequencies. But that might be okay because I don't think it's as much of a problem for the high frequencies with the clicking because they repeat so frequently that I don't know you'll even notice the um the the switch of face. But let's find out. Uh, blue. Okay. It's not as loud. doesn't seem quite right. Feels like it should be even sort of steeper, right? Yeah, let's um let's plot this guy too. That certainly doesn't look right. I don't think this is right. I think the No, but it should be. So we have the same scalar factor as in pink. We enumerate from the back. And so that would mean that the highest bin gets the same modification as the lowest bin did in pink. 3. 01 decibel per octave with increasing frequency. 3. 01 decibel per octave. Spectral power density reduces. Huh. So here we end up with one hertz well 20 hertz ends up with an amplitude of the max amplitude. / square< unk> of + 1. Here we end up with 2250 hertz gets that same amplitude. And then as you go down in hertz, you divide by a larger number. And the square root here should mean that in the logarithmic plot you should see a straight line. We can't put the enumerate before the rev because then this computation is the same as the one for pink noise. What was the power density increases 10 log 10 of 2. So 301 decibel per octave. So the density is proportional to f. I think I want to write this without the rev. as enumerate. And this now is hertz again. And what we want here is for this to now be proportional to, right? Rather than inversely proportional to I think it's just this right like okay without playing this file But just Whoa. Okay. Yeah, cuz this ends up way too loud. No, wait. The power density is not the amplitude. So I wonder if it would be easier to do this in power density in the first place and then convert back to amplitude. because currently we're doing it in amplitude but the adjustments are in power density. If we instead said let's do it just for blue I guess. So power uh what did we say power is the so average amplitude uh is it amplitude squared or amplitude squared I never remember someone wrote earlier up in chat but I can't find it now let's see um ratio between amplitude and power density power is amplitude dude squared. Okay, great. Right. And then we want the amplitude to be proportional to the power should frequency. So this should be power times the frequency and then the square root of that to get back to amplitude. Now the the adjustment here is wrong but Yeah, it's going to it is going to be hard to I think set a mult normalization between these. I think you're right. It just feels like it should be possible, but like I don't really want to give it up if I can avoid it. But let's see what happens if I do this and open this. What do I get now? It's still No, that's Well, now we just made it directly proportional to frequency, which might be too severe. Like I mean you simply need a factor in there, right? It would still be pro proportional which would be because Oh, because this Yeah, it's not really max amplitude anymore. It's like an adjustment factor, but it's not max. Yeah, that sounds a lot better. It's just Yeah, there we go. It just mislabeled as max amplitude. So there we have blue noise. Yes. So this isn't really a max amplitude. This so this is mislabeled and I do think it's easier to operate in this domain because then we can do here. So this is going to be like a adjustment factor or it's really a normalization, right? So it's going to be that times this normalization power one normalization divided by this and then square root to get back to amplitude. And this is going to be no this is going to be power. And then here normalization is going to be um Oh yeah, I guess you could also just you could add up all the frequency bend amplitudes. That's also true. And then normalize. Um but I think here actually for browning we can just keep it the way it was but for pink it's not it's a normalization factor it's not actually the max amplitude and same thing here this is normal normalization so if I now do this and do pink that was loud Uh, why did that change anything? Oh yeah. No, this needs to be this is still in amplitude. So this needs to be this. Yeah. Okay. So this is now pink. This is now blue. All right. So let's all settle down. this to brown, this to white, and then let's check them all. All right, so this supposedly Why is Brownian so loud? Okay. So, the brown in normalization feels not quite right, but uh Okay, so white noise should be what? Wait, no, this is blue. Yes, it says right there. Blue. Okay, so analyze blue. Blue is blue. Sweet. Brown. Analyze. That's brown. And we're skipping the lowest 20 hertz. This is pink. Pink is pink. And I guess, okay, if we're going to be really pedantic about it, right? So, Brownian effect analyze plot spectrum. And then here, pink analyze plot spectrum. So, for this over here is pink. This is brownian, right? If we look back to the Wikipedia one, brownian should decrease much faster than pink. And if we look at this uh well kind of yeah so in pink so this is at the very end it stops at minus 72 here 78 so like if we look at the volume around 440. Uh 440 is like around here. We see it's - 46 and here 440 is - 53. But the brown is also that doesn't seem right. Like why does the branding one start so much higher? It starts so much higher because of the slope. Yeah. So, if it's going to average to the same value, but like Okay, let's do 1,400ish is minus H - 56 and 1400 and this one is But that's the thing. Pink is quieter at 1,400 and I expect it to be louder because it should be less sloped. So if we do linear frequency linear frequency, it's hard to tell because their scales are off from each other, right? But this doesn't seem quite right. Yeah, it's minus3 decibel per octave for pink and minus 6 decel per octave for brown. But I don't think we're getting Okay, let's take an octave in brown, right? So if we go from 110 is - 34 to 220 oh is -40. So that is actually min - 6. If we do something else down here like okay here a th00and is -53 and 2,00 is - 56 so that is -6 dB. Uh if we go to pink and we do uh 105 is - 47 and 210. two come on 210 okay is minus 50 so that's minus 3 dB so so the slope is right and maybe the brown is simply too loud what's our normalization for the does this Oh, this also has to be square root for the normalization cuz we're still normalizing the power, but then without the divided by two. You think so? I'm not going to dare play these yet because Oh, and I guess we should double check the white just while we're here. Uh, the white is linear frequency is white. Okay, great. Okay. And then let's open audio, which is the one I just generated for brown. This one's now too quiet. If I plot the spectrum log frequency, that looks more like the steepness I would have expected, but now it's much too quiet. The reason for the divided by two, right, is to get to halfway through the spectrum. So that one feels like it needs to be there for all of them. No, I actually think I think the previous thing kind of makes sense, right? Because the slope is so steep that for the average frequency to get the average amplitude, the max the low frequencies need to be so loud. But the reality is that in Brownian the average frequency is like barely audible and so the scaling is just completely off. It's almost like you know there's an interesting question of maybe the thing to scale here is not the average but the loudest. Right? So you want the loudest amplitude to be the same. Although that's weird too because then harmonics wouldn't Yeah, I mean we could do actual normalization, right? That that's the other option. Um and maybe we should But I think actual normalization would be the same, right? You would just scale everything to the loudest amplitude. Otherwise, you need to do something real fancy like uh computing like the sum of the squares or something and normalize based on that. or we normalize in the time domain. But if domain then that feels weird too because it would mean that uh well depending on the scale at which we do the timing whether we the sk the duration over which we do the scaling. If we do it over the whole file, then maybe it doesn't matter. But like scaling it by the amplitude that we happen to sample feels like it ends up wrong unless you sample over enough randomness. Yeah. Might be that we just kind of have to give up on having this like computed scaling factor and actually we need to do something more dynamic. But I think the other way to go about this would be to at least for Brownian which is very steep to simply compute actually okay how about we compute how loud is the loudest or what's the amplitude of the highest amplitude thinking thing in pink and then we scale all of ours based on that factor. It won't quite work because of human perception based on frequency, but like it feels like that's kind of what we're circling around here, right? So um so pink normalization is that pink power is that uh and pink max amplitude is pink power divided by one square root. That makes sense. So that's the pink max amplitude. And here we didn't do actually these cancel each other out. So this is the pink max amplitude. And then we should just do that. But we're skipping 20. It's also skipping 20. So that's not quite right. It's actually this right. So uh 20 that's the how highest amplitude we'll have in pink. And we want we compute Um it's like we want to take this value which can actually be arbitrary. It can just be one. And then we want to scale it such that the loudest one is the pink max altitude uh max amplitude, right? So it's like this. Yes, we're cutting off the high 20s. Yeah, it ends up weird because of the slope is so steep. But I do think here that what we want to do is simply So if Hertz is um I can tell my brain is slowing down. If um if Hertz here is 20, right? So, we'll skip 20, which means the first index we'll actually get is 20. Uh, which is actually 21 hertz. Then it really does feel like this should just be pink max amplitude, right? Cuz it's like one divided by this. Oh, but maybe Okay, but maybe we do actually need to normalize it. So it's that but divided by uh this which is our highest one our loudest one I mean so that gives us a ratio and then it's this one times pink max amplitude so that the loudest one we end up producing is the same as the loudest one that the pink one ends up producing. thing. 120 beats per minute. Uh, well, that sure doesn't look right, but it is actually because if you look at it, yeah, look here. They now start at the same frequency, but the brownian descend descends much faster. So, so this is now normalized such that the lowest hertz is at the same decibel level as pink. Yeah. But this is where what actually hits us is the area under the curve is so much higher here. So it has to be we have to compute it based on area under the curve feels like the only way to actually do it. Which means we need to I think compute the whole thing pick an area under the curve that we want and then scale all the values afterwards. Or alternatively, simply say it's going to be 2x louder, right? Or 4x louder. to-do. Uh normalize this by this and everything by um computing area under the curve of amplitudes. amplitudes maybe of power density and normalizing that to a particular number. We got it. Nobody touch anything. Yeah, you're not wrong. Oh, yeah. This these should obviously be samples per second actually. Okay. Const max frequent frequency is going to be a U32 is going to be 2250. This is going to be max frequency times 2. as f64. fixed it. All right. You know, instead of eyeballing Brownian is 4x quieter than pink. Excellent. All right. Should we do one more? What's after blue? Violet.
Violet noise
Violet is just boring, but we can do violet so easy. Okay. Uh, violet. Oh no. Violet is the same as Brownian actually. Um except that this becomes blue normalization and this becomes also blue normalization and it's computed as uh this is divided I and this is now here. This is a I don't even want to think about what that normalization looks like here because this is no longer a one divided by It's just the same as blue. Let's ignore the normalization for now. Um but the difference is going to be that here. Oh, this has gotten so much worse now that we did the whole thing. Uh we're not taking the square root to go back to amplitude. And now, of course, Violet is going to be way too loud because it doesn't have normalization. Yeah. Uh-huh. Uh, so just like for Brownian, the normalization now has to be divided by four. Is that right? Perfect. Yep. Great. Uh, and if we analyze plot spectrum, that looks like violet. So, it goes from, let's pick some random point on the scale. goes from here which is uh 25 is minus 86 and what and five is minus 80. That's not 6 dB per octave. Right. This seems almost too steep. Like Okay. What about here? This is Okay. Three. I need more zoom. But I want zoom in this direction. Why can I only zoom up and down? Okay. Here. So this is 2000 is - 88 or 2001 is - 88 42 is - 82. Okay. So that is six dB. Okay. Great. So we have violet. Then we can do
Grey noise
one more. We can do gray to psycho acoustic equal loudness curve. Oh boy. Oh no. But arguably this is like what we need for normalization, right? Like Okay. Gray noise an equal loudness contour. A mathematically simpler and clearly defined approximation is pink noise. An equal loudness contour. Oh no. It means we have to encode like an actual model into our thing. Uh I don't want to put an ISO standard into my thing. But this is the A curve is applied to the amplitude spectrum not the intensity spectrum of the unweighted sound level. Okay. This is math. Okay. All right. Okay. Let we can do this. So for a given frequency, so for each frequency, RA is 12194 squared. Great. This is math I can do. squared times the frequency in hertz I assume. Okay. To the fourth power. Gotcha. No problem. Divided by Hertz is her as F64. Let's make this easier on ourselves. Uh hertz power ii2 plus 20. 6 power i2. Okay. Of course. Uh-huh. Yep. See, no problem. multiplied by the square root of something multiplied by hertz power 2 plus 12194 squared. Okay, so there are definitely some numbers we can reuse here. Uh, f64 squirt. Really want my square root functions back. Can I get rid of the No, I can't apparently. Okay. Um, and then we haven't figured out this yet. F64 squared. This has to be multiplied by this. And this is hertz. power i2 + 107. 7 squared of course hertz power ii2 plus 737. 9 power i2 Okay. Uh, why is it ambiguous? Oh, it's cuz of the cuz I brought complex into the world. Um, I don't even know what this is going to be yet. So that needs to stop yelling at me. Um, is can I write like F64 here? Okay. F65. That's a new one. No. There we go. Uh, F64. Okay, so that's RA and then let A is I'm sorry what 20 times RA minus no dot log 10 - 20 times Okay, so we're going to need Oh, boy. Uh, okay. No. Uh, okay. RA is a function that takes a hertz and returns that value. Let R a hertz is ra of hertz as f of 64. Cool. times uh ra of a th00and sure dot log 10. This all seems fine, right? We don't we're not worried about this. Uh this is an F64. Yes, thank you very much. And then here we say RA R A 1000 is RA 1000. And this is going to be R A 1000. This one can go right in here as a Perfect. I see no problems. Okay. So now we have this a value which is approximately equal to plus two. Great. Uh and so that's the amplitude. I'm scared. Nan. Good. Great. Okay, so we got Nan out of our FFT, huh? Okay, good stuff. So, debug this one. Actually, how about we just print line a and then we put it into dings. Okay. So, it's that curve in amplitude which doesn't feel like what I expected. or the waiting function. But what is a here? I see this is the gain in decibb is what the a gives us here. It gives us the gain in decibb. And so if you apply that gain then the middle frequencies should get louder. Right? These frequencies should get louder because this is closer to zero which in decb would be more gain. Right? And this matches this kind of curveish. Right? So why does that give rise to this curve? Because I would expect that I would expect the gain to be I because the gain is higher in the middle. I would explain expect the amplitudes of the middle frequencies to also be higher. those. Oh, the this is those sound louder. I see. Oh, this is the gain that we as humans have to them. Inverted. Yeah. Yeah. Okay. So this is how we as humans hear them adjusted. Therefore that way. Therefore we need to apply the inverse of this to the amplitude it to the amplitude that we want. The amplitude we want is the average amplitude. So, so our actual amplitude needs to be uh the average amplitude that we want. This is where I really want to use like um or something so we get units on this stuff because this is now in a gain in decibb uh and the amplitude we have is linear scale. So we need to take But we're already taking the log here. So is it just then is it actually just minus a that feels not right. But maybe it is right. I don't think it's multiply because this is gain right. I actually uh no we need to it's not the log we need to take the we need to do x10 right like uh 10 to the^ of a here. What? Why can't I use pow dot pow f? Okay, fine. That looks more right, but it doesn't look quite right because this would mean we go to zero, right? because this y value ends up going like below zero for the amplitude which is not what we want. So this adjustment feels too severe. But I but it can't just be minus a. That doesn't seem. But why are these values all still positive? Like average amplitude here is the number eight. So when we subtract a from average amplitude, how do we get 156 positive like a positive number? Right? This is eight, right? And this is there too many bins. Minus 9. Yes. Oh, it's defined such that the average DB is zero. Yeah. which is not necessarily what we want here. Oh, it's because we're subtracting a, but a is a large negative number is why. Yeah. So, so it um this no yeah no power f this is right but it's just that this is normalized around zero dB. And so what we would need to do is scale this so that it is not centered on zero, right? because okay let's um uh if we didn't do this if we did this now and then I close this and then I open this wait did I yeah analyze plus spectrum so we end up with a pretty strange plot It's like clearly there's something happening here, but it's not quite what we expected. Uh I think R is the waiting that you can apply directly. Oh, well, if that's the case, then I should be able to just say average amplitude times RA Hertz SFX64. Ooh, except that's inverted, right? because I need to uh I guess I could do this, but that doesn't seem quite right. Uh I need to do right because this is based on this uh is based on how much louder it sounds to us. And so we need No, but divide won't give us the right thing, right? Yeah. you end up with a enormous potential number here. Um, I think what we actually need is um, it's like almost right, but I wonder It's almost like I want like one minus, right? Like it it feels like that. It's not right, but Right. It's not actually it's kind of like that. But um ah but I actually want the scaling factor to be um I don't want it to go all the way to zero. Ah I see what's happening here. uh it is one minus this. But what I want to apply that to is um the variation in the audio not the absolute value. So I think what I would do is something like uh you know this divided by uh this is kind of silly but like this / 2 plus um this / 2 times 1 minus that. Oops. Because that way I'm offsetting the bottom so that it doesn't start at zero. And so I basically want to scale the difference between the uh I don't allow this to scale all the way to zero for things that need to be that should be at sort of zero dB compared to where they are. And so I think this is actually right. It's like I guess actually it should be max right we should be scaling by the instead of by the average would be should be scaling by what we want the max volume to be and the max volume. Yeah. And this is where we basically need the uh um the root mean square thing we came up with or we found. Let's first this guy can get a comment that says it's from here. Um but let's just see. So if I what does this play like? If I open this I don't know. That sounds like a sound to me. Why are the low frequencies I guess the low frequencies are always hard to sample, but like linearwise that doesn't look terrible. Is this is a log plot, right? Yeah. So, the log plot ends up kind of weird because you don't get enough samples of the lower frequencies, but we could fix that actually by um changing the duration that we generate to be let's say we generate 100 seconds. I'm not running in release mode. That's why it takes a while to uh Okay. Audio. No. And then I run analyze over the whole thing. H. Still pretty noisy there. But like, and this still seems too high. Yeah. So, the scaling here is still not it's not quite right. like debating what I even wanted to plot or what I wanted to generate. May maybe it actually is just average amplitude uh times one minus that. It just means that the or like two times that sounds kind of pleasant actually. But like loudness-wise, it seemed pretty similar to the others. It is interesting to me though that the like if you look at the Wikipedia one, see how the peaks the amplitude peaks on the right are lower than left. And we don't really see that. Oh, actually, I guess we do see that here, right? Because these peaks are higher than this peak. It's just that they're sort of obscured by the um by the lack of fidelity here. I wonder if there's a can I like ah humming window hand window. Yeah. So like that goes to -60 but this goes to - 61. So it does feel kind of odd. Although if you look at it too like look at the difference here between this at - 60 and this is - 66. Whereas if we open for example the uh let's take the pink noise for instance right and we analyze and plot the spectrum here. This goes from minus42 to -69. And so clearly the the actual range here is not very big. You know, I do wonder whether Uh are the limits of the x-axis different? Let's see. This is now the x-axis seems to be the same -40 and -50 something. And for here -40 to Yeah. No, the X and Y axis are actually both the same on the Wikipedia ones. Although this might not be the same equal loudness curve as the one we're using, right? We just picked a random one of these curves. It's not clear they've been using the same one. So, it could be they're using a B curve or something, right? In fact, do we know how to pick between these? Oh, I see. There are other frequency waitings that have fallen into disuse. Okay, so A feels like the one we probably should be using, which I'm guessing then is what's being used here. Um, I honestly just changing this to a window helped a lot. I mean, maybe it's just actually a matter of scaling it up so that the max lines up with what we got for um for pink, for example. Although, this looks like it'll be real loud. Wait, but that made it. Oh, that's cuz I'm doing this wrong. No. Yeah, this should be one minus and then this should be like two times. Okay, we don't need the insanely long file anymore. Thank you. This can be let's do 20 seconds is probably fine. So if I go here, I do audio. Okay. And then we analyze this guy. I mean, it still looks about the same, right? Like these still go down pretty far. It's because this the scaling here isn't this isn't the right way to scale it, right? Like this is telling us Oops. Um this formula is telling us the or really the one that actually gave us the A curve, right? So what was the uh this was ra of a th00and uh and then here it was a is uh 20 * um ra of hertz as f64 log 10 minus ra00 Right? Like this. This was the formula they gave us for actually computing the A. But this is the gain in decibb for human hearing at zero dB. And so it's like a discount you have to take to hearing a thing. So when we're trying to generate a signal, we need to sort of add the inverse of that. And so maybe it's simply Maybe it is simply the amplitude we want to have. It does feel like it should be just divided by the waiting. And then this feels like it'll just give really big values and then the some scaling factor to bring it back down. But at that point, it's really just 1. 0 0 divided by it's 1 over that you have to use a waiting formula in the frequency domain after doing FMT and just subtract the I waiting before the inverse. This is in the frequency domain. Like right here, we're And it's just before we do the theft. But the thing that's interesting is like, okay, let's say we do the this. What if we clamp this at, you know, from zero to uh, I don't know, three times the average or two times the average. Like that curve is a lot more reasonable. It's still it does look a lot more reasonable than this one spectrum. Yeah, that looks a lot better. But it still feels like we're clamping it too low. But like the the louds are way louder than the rest, right? Like if I look at this one. Like look at the depth of that trough. How about converting the spectrum to decibb subtracting the a curve and then converting back? Uh so that would be generate white noise, turn it all to decibb, then subract And because those are negative, that would end up adding. I don't think that's right either. I mean, you you don't need to compute the whole spectrum first in order to do that, right? You should be able to do that right in here by saying this is the a curve uh in decibb for that frequency. Uh and then what you're saying is the amplitude we want. So the average amplitude uh in dB is the average amplitude um is 20 times that do log 10. Right? And then you're saying let target in DB is average in DB. No. Oh, autocomplete is being sad to me. Average in DB minus A in DB. And then a is going to be um is F64 PA F of target in DB like so. Well, that's definitely not right. Target to be divided by 20. That's But that's still not right. I mean, our average amplitude here is also stupid, right? It's just the average amplitude we set was just it just happens to be the amplitude that we set the white noise to. So it's like it's not clear that 8 is the right value really. Um because that's just linear amplitude. The magnitude of the frequency component for each bin needs to be reduced by the equivalent frequency value from the awaiting function for that bin. Yeah, that's what we're doing here, right? So, we're taking the desired amplitude for this bin, turning it into decibb, and then we get the a value for that bin also in decibb. We subtract one from the other, and then we go back to amplitude, and that the resulting value is nuts. Question is why is it nuts? And it's not okay. So fine. Let's then do clamp from zero to uh three times the average or two times the average amplitude just to clamp it to see. Three times the amplitude. four times the amplitude. Uh, awaiting doesn't produce good results for minus for less than 10 hertz. That seems right. Okay. So, skip 10. Honestly, skip 20. Okay. Do we then even need the clamp? We do still need the clamp. All right. So what do we actually get into this file now? If I now go here and open it, what do I get? Analyze plot spectrum. Ah, so this now peaks at. Okay, I must do 10. Sure. Analyze. I mean, should I just not clamp it? It feels that feels wrong. But what happens if I do? Well, I mean, it's not wrong. It's closer to the brownian. Actually, I think this is going to be loud if I play it. You know, I think that's just correct. It wasn't even that loud. Who knows if it's right at this point. It's true, but I mean, okay, reading through this, right? Like, this looks kind of right, right? So, we compute the the A formula we're told in decibb. We compute the average we want in decibb. We subtract one from the other to compensate for the A waiting, and then we turn it back into amplitude, and that's what we plot. If we don't skip 20, if we Let's do skip 10, then we Oh, I don't need the plotting anymore. I'm pretty sure there's some discontinuity here that it's unhappy below some amount of uh hertz. Maybe there's a reason why the Wikipedia starts it from 100. Could be. I mean, let's What happens then if we do that sounds fairly similar, but 20 seemed like it worked fine. You can hear like a kind of rhythmic thing in the background, which I guess is the low herz things, right? Okay, I think this is a good place to call it. So, we have an implementation of the wave format. I I'll put this on GitHub as well so people can find it afterwards and you can play around with this and figure out your curves and make happy things from it. Um, this can now go away too. Um, we managed to implement a wave file generator. We managed to figure out what the riff format was and how that worked. And we managed to implement a bunch of different types of noise. The normalization isn't quite there, but it's like these are fairly reasonable now in terms of normalization. And all the frequency plots look right. So, I think I'm pretty happy with where we landed. Um, now I'm not going to claim that this is beautiful Rust code. Um, but maybe you've learned something about audio. I certainly have. Maybe you learned something about file formats. I don't know if you learned a whole lot about Rust, but maybe you have. Um, or maybe you know audio from before in a different language and now you know a little bit about what it looks like when you're writing it in Rust code. Um, in any case, I think we're going to stop it there. It's getting late. Uh, thank you all for joining. I hope that was interesting. I'll see you in whatever the next stream is. It'll probably be another impulse stream of some kind. I like doing this these kind of streams where I build a thing and that it kind of works and I learn something in the process. Those are the best kinds for me. I don't know if it's good for you as the audience, but for me, those are the funnest ones. Um, so cool. Thank you everyone. Thanks for joining me and um I'll see you next time.