Distributed transactions
Machine-readable: Markdown · JSON API · Site index
Описание видео
Your interviewer asks how you'd handle transactions when an operation spans multiple services. Most candidates have never thought about this.
When everything lives in one database, it's straightforward. This is because SQL database guarantee all-or-nothing atomicity via transactions — either every write succeeds together, or none of them do.
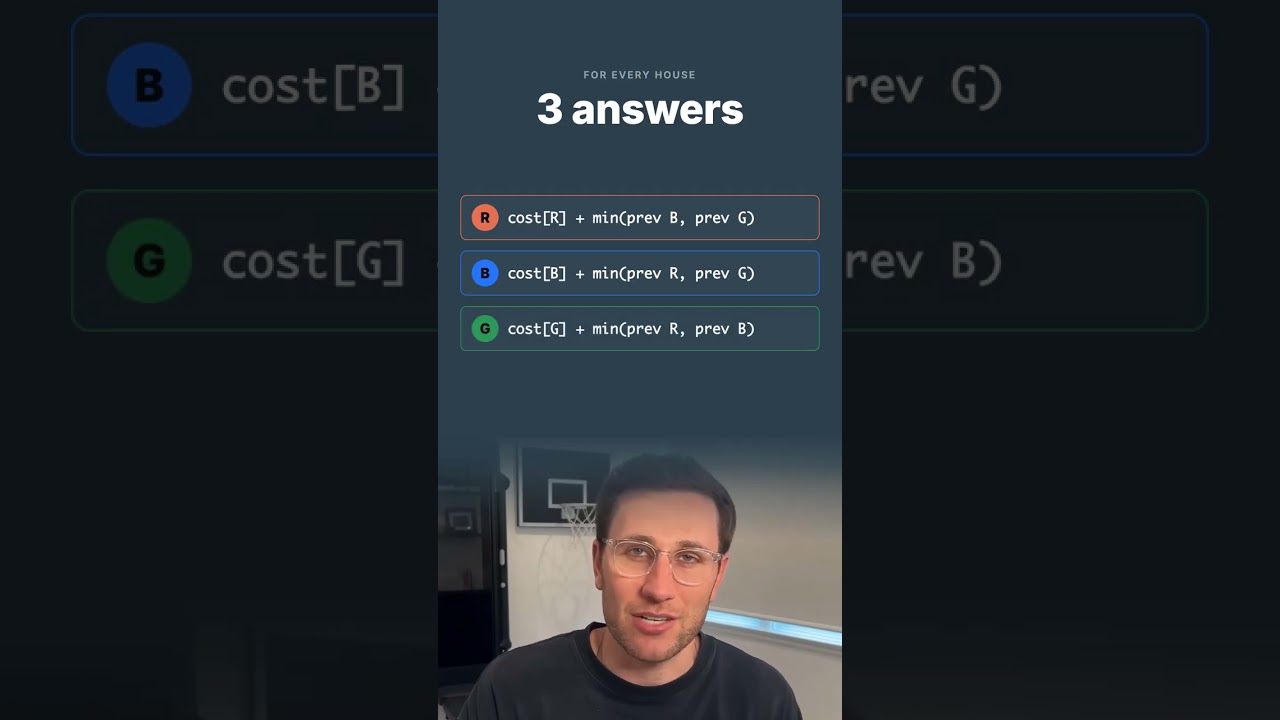
But at scale, inventory, payments, and shipping are separate services with separate databases. What if payment succeeds but shipping fails? You can't just roll back.
Option one: two-phase commit. A coordinator asks every service "can you commit?" and waits for all of them to say yes before anyone actually commits. The problem is every service is locked and waiting. If the coordinator crashes, they're all stuck holding locks forever. Almost nobody uses this to build applications.
Option two: the saga pattern. Instead of one big atomic operation, each service does its step independently. If a later step fails, you run compensating actions to undo the earlier ones. Shipping fails? Refund the payment, restock the inventory. No locks, no coordinator bottleneck.
The tradeoff is there's a window where your system is partially complete. But that's the real world. Distributed systems don't get atomicity for free.
Learn more at hellointerview.com. #shorts