Join this channel to get access to perks:
https://www.youtube.com/channel/UCDJ2HAZ_hW-DMJj_U0zN38w/join
Outbox Pattern Part2: https://youtu.be/OQRv228F9Dc
Оглавление (4 сегментов)
Segment 1 (00:00 - 05:00)
come back and today I will show you outbox pattern in the event-driven architecture. Very, very important. It has been asked a lot in interviews. And I will also tell you what generally engineer tried to answer first. Okay? But those answers are generally overruled because there are some gap in those. And what's the correct answer? Okay? So, before we go deep into this outbox pattern, we first need to understand the problem which exist. Okay? So, if you see this, this is the problem statement which interviewer will provide you. Very, very simple method of a create order when this endpoint got hit. What it does it? It first tried to save in the DB. Okay? So, the order which has been received, we are trying to store in DB. And in the step two, we are also publishing an event. The most common use case in industry. We have to store in DB and also we have to publish an event. Nothing special in this. Okay? So, these two tasks we have to do in this method. So, interviewer will say, "What's the problem in this? " So, there is one major flaw in this one. So, we are writing two separate independent system. So, this is one independent system, DB. And this is another independent system which is Kafka. Okay? So, we are trying to write into two independent system. Okay? So, we can get problem like DB get succeeded, but Kafka fails. For example, your DB order repository. save. And this got succeeded. This first got succeeded. Your It is stored in the DB successfully. But when you're trying to publish to the Kafka, that got failed. This could result in that the order exists in DB, yes, but no event published. So, maybe the downstream components like payment service, inventory service which rely on this event, they will not be able to update their system. So, it could result into data inconsistency. Similarly, what we can have is Kafka got succeed, but DB got failed. It's possible, right? If Kafka is able to publish an event, but DB we don't have. So, what would happen is all the downstream like payment, inventory, they will update their system, but order doesn't even exist in the DB. So, this is like more impact than use case one. So, this is the problem statement. So, problem statement would be given to you only this that what's the problem in this, then we have to say that, "Okay, this two issue can come. " And then actually, the name of this problem is dual write problem. So, once we have identified this problem, the interviewer will say that, "How you will solve it? " Okay? So, I will tell you one two common answers generally given by engineers, but it get overruled because they these answers generally have some gap. The first answer, we will use @transactional plus manual exception throw. What this solution does? So, we have put @transactional for DB. So, what would happen is So, in a step one, we are writing into the DB. If this succeeded, we are moving it to the next step. Now, the Kafka part we have put into try catch block. If Kafka got succeeded, well and good. DB succeeded, Kafka succeeded, good. But if there any exception happens in Kafka, it will catch it and throw. And because of this throw exception, since it is put under @transactional, it will roll back the DB also. So, very high level, this solution looks good, right? So, DB got succeeded. DB fails, ultimately, it would be rolled back, so good. DB succeeded, Kafka failed, so it will throw exception and DB will also get rolled back. So, sounds good, right? But there is a gap. See this one. DB success, well and good. Kafka template send message sent to the Kafka broker. Message has Okay? But there is some gap in the acknowledgement received by the you can say that by the broker. Or the acknowledgement message has been lost because of network issue. Now, what you will what your application as a producer application will think that, "Hey, the message has not been published. " But actually, it is published. But the acknowledge packet has been lost in the network, you can say that because of network issue.
Segment 2 (05:00 - 10:00)
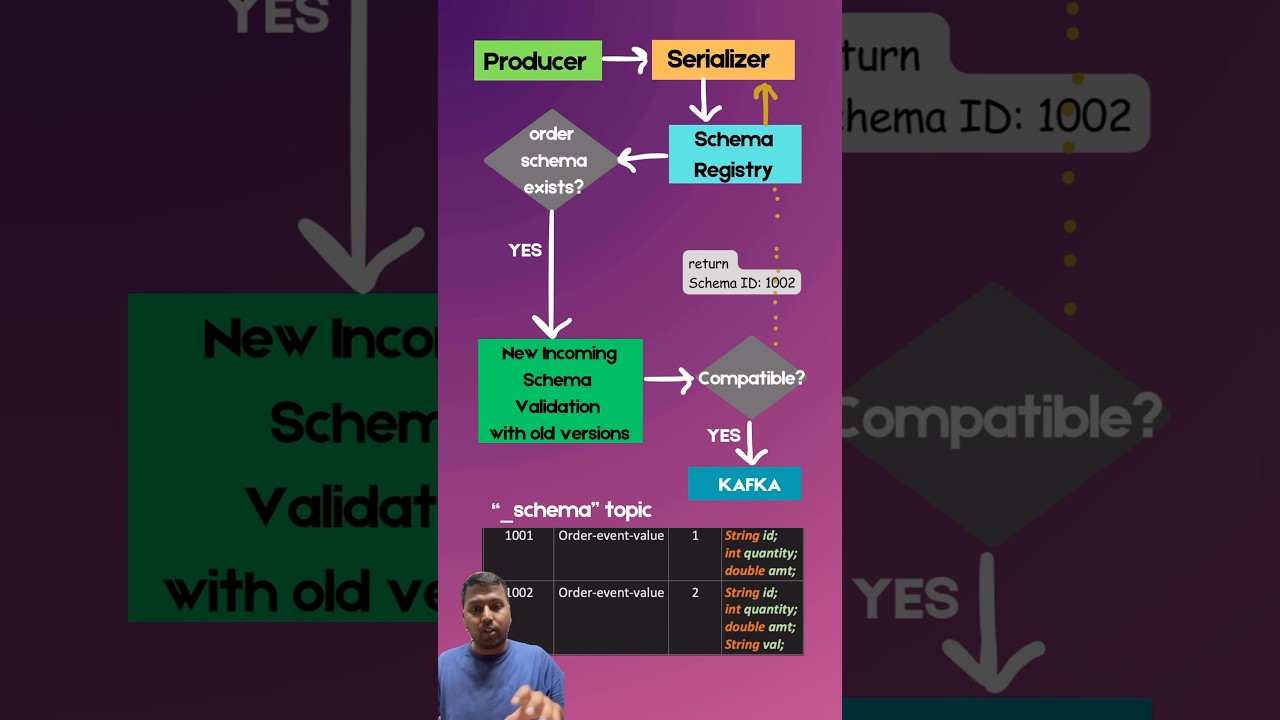
So, you will say that, "Okay, Kafka publish got failed. " You will roll back it. And when you roll back it, when you throw exception, you will roll back the DB also. But your Kafka event got published. Okay? So, the issue is that order does not exist in DB, but Kafka event published. You got it? You got the issue? At the first glance, everything looks good, but there is still a gap. So, that's why this solution generally get overruled. The second solution which generally proposes two phase commit that we will have a coordinator. one prepare phase. One for DB, one for Kafka. Both will participate. And like normal two phase commit protocol, right? So, but the participants are DB and Kafka. So, they will first say that, "Yes, I'm ready. " Now, in the phase two, they will commit. And after that, they will commit. But the problem is this looks working solution. Kafka do not even support two phase protocol, two phase commit protocol. Okay? So, two phase commit to work, all participants need to understand this protocol. And Kafka does not support 2PC. So, there is no use to discuss the pros and cons of this that, "Okay, what would happen this? " The thing is Kafka do not understand this prepare commit and all. So, you can't add Kafka as one of the participant itself. So, this two things are overruled. The solution which currently widely used in industry is outbox pattern. So, idea is don't write directly to Kafka. Write to DB first, and then a separate process read the DB and publish to Kafka. Okay? So, now see this. In this one, the first step is same. I am writing to order. I have got the order. So, order repository to save order, same. Whatever we were doing before also, the same. Okay? Now, in the second one, if you see, I am not publishing to Kafka. I have created a new table, outbox table. Okay? And I am publishing the event details into that one. So, it's still the DB operation only. So, now they can participate in one transaction. If any of this fail, we can roll back successfully. Okay? So, at this point of time, Kafka is not involved. Only DB operation. So, in this outbox pattern, a new table, you can give any name, but generally standard is you can give outbox table outbox name or whatever the name you want to give. So, a new table, say outbox table, is introduced. In that one, what we need to store the event details, whatever we have to publish. So, that we store into this. And this two now DB operation can be part of one transaction. And now later on, a separate process will read from this table and publish to Kafka. Again, lot of interview question can be come to this like what the separate process? We will come to this one. So, there are two. Polar and CDC. Okay? I will tell you both. But at a high level, you got it what the outbox pattern idea is that we will create a new table, new DB table, and that DB table is store the event details, and a separate process read from this table, and then publish to Kafka. Okay? So, now this become overall compliant with what we wanted. So, what is the schema of this outbox table? It's a normal regular DB table, and you can like change it according to your need. You can give any name you want. Okay? So, but this is generally high level. What everyone use? A unique ID. Okay? Aggregate type. Order. Generally, this is used for determining the topic. Okay? Which topic it will go. Event type is order created, order deleted. Generally, we don't use it like, but still if your business logic has to know about like, "Okay, the order, but what happened to the order? Order created, order deleted. " Or something you have to send into the header. Or you have some business logic on top of it. So, at least it will give you more context what happened to the order. Event type. Okay? And then aggregate ID. You can consider that this is act as a key. Okay? This so that this is very important. So that all
Segment 3 (10:00 - 15:00)
the s- orders Let's say all the order which belongs to customer ID, let's say key is K1. So all the order for this key should goes to one partition so that order get maintained. Let's say first order created, then order cancelled. Then so let's say this two, order created, order cancelled. So there's a proper ordering. So they both should have same key, key one, key one. When they have a same key, they then only they would be goes to the same partition and when they go to the same partition, then the order would be maintained. First order created, then order cancelled. Got it? So aggregate ID, you can say that used for key. Then your normal payload which you want to publish. Created at is published. So this is optional. I will tell you its use. Okay? So but this is something is customizable depending upon your business need. But this is the high level. We can determine the topic name, key, we can determine the payload. Okay, that's the same thing I have explained it here. And is published is optional. I will tell you when it is used, when it is not used. So outbox table is consumed in two ways. I told you that outbox table, a separate process will read the data. Again, there are two ways this outbox table data is consumed. One is polar or you can say that polling. Another is CDC, change data capture, very important. Okay? So is published is used in polling, but in CDC does not used. We'll see that one. So let's start first polling and then later I will also show you the CDC mechanism also. If you have gone through the Spring Boot playlist and in that one I have covered JPA. So in that one you will get to know how to create entity repository, how to connect with the DB. So this is the same thing I am doing it here, nothing is special. So this is just one controller. The request comes to this one. Then I'm calling this order service. Okay? And here I have at the rate transactional. Now we know that we have to do two things. First thing is we have to store into the order DB. And second we have to store in the outbox DB. So for this two tables, we have entity, order entity, outbox entity. Again, please check JPA topics if you have any doubt what is entity or how to create repository. Then for this two entity I have order repository, outbox repository. Now the I have dependency here. And I'm just using it. Order repository. save order. And then outbox repository. save outbox event. Okay? So outbox event I have created aggregate type, aggregate ID, event type, and the payload. So very simple. These all are like just helps in creating the tables and connecting with the DB. And this is the application. properties. If you have gone through the JPA part, you know that uh you can connect with So in the JPA part I have connected with S2DB, but the same way you can connect with MySQL, Postgres, anything. So you need to provide the data source, username, password, and the driver class. Okay? So with the same way we can connect to a Postgres, MySQL, and any DB which you want. But this is the very basic thing we have to write. So now what we have done till now is in the outbox table we have the data. Now we have to write the polar. The polar should poll the outbox table. So very simple way I have written one polar. You can say that it is just a scheduler. Okay? I've also covered the scheduler, how you can write it. So this is one scheduler I have annotated with at the rate schedule. At what time it should it run is that in this one I'm controlling. Every two seconds this will run. Okay? So every two second it will run. What I'm doing is in the outbox repository, I am finding the unpublished event and the best size is 10. Here I have defined it in the application. properties. So outbox prop- in the outbox repository I have this method. Select asterisk from outbox event table, okay, outbox event in the entity, this is the table name. Where published equals to false means it is not yet published. And order by created at so that order is maintained. Limit batch size.
Segment 4 (15:00 - 18:00)
So I am getting 10 record at a time ordered by created at. Okay? If there is none, return it. But once you get it, we have to publish it. Okay? So that's what I'm just doing Kafka template. send. You have a topic, aggregate ID key, payload. Okay? Once you have able to publish to the Kafka, set published to true that yes, now you are published so that next run this same record should not be picked. And when you published at is time, just save it. Outbox repository. save this event. In catch, why I'm breaking is let's say I need to follow an order. Let's say three events for this key. Now if one event got failed, so it goes to the catch. If I do not break it, it will proceed two and three. Then the order will break. So if one fail, then you should not proceed with two and three. That's why I have put break. So you can say that this is just a one basic polar. And it's very simple to write it. So you understood the polling technique? But this polling has so many disadvantages and that's where interview will say that okay, why s- do you have something better than polling? But first we need to understand the disadvantage of polling. Disadvantage of polling is multi-instance handling. So let's say you have three application, three instances, instance one, instance two, instance three. So means three polar. So this is your polar one, polar two, polar three. All three will run together. So you need to maintain that okay, they should not pick the same row. Okay? And if they pick different rows, then they should not break the order. Let's say order all belongs to one key, one, two, and key one here three. This can break the order. So if it pub- process three, one, and then one and two later. So there are many problems comes. So we have to have like shed lock technique like concept we have to build out. So we have to handle the multi-instance handling. Then a polling gap. Like here I am running the scheduler every two second delay. So even though event is created at 10, the next poll will run at 10:02 itself. So there is always a delay depending upon your what time you are polling. Okay? Interval. Constant DB load. Now let's say that there is no event at all, but you have to continuously poll your DB. Okay? So means you're consistently putting a load on your DB. Is there any event? Even though there is no event at all. You have also need to take care of the DB clean up. So since you are maintaining a table, outbox event table, it need to be clean up regularly as its size will grow rapidly. Duplicate processing. What happened is sometime let's say you have a you have read one row, you have published also, but you failed to update to published to true. That got failed. So in the next run again this row would be picked up and you will publish it again. So there are this is very common that you will publish the same event multiple times so your consumer need to properly handle the idempotency. So there are many challenges with the polling. And that's where the change data capture comes into the picture. Very important. So in the next part I will tell you this one.
Другие видео автора — Concept && Coding - by Shrayansh