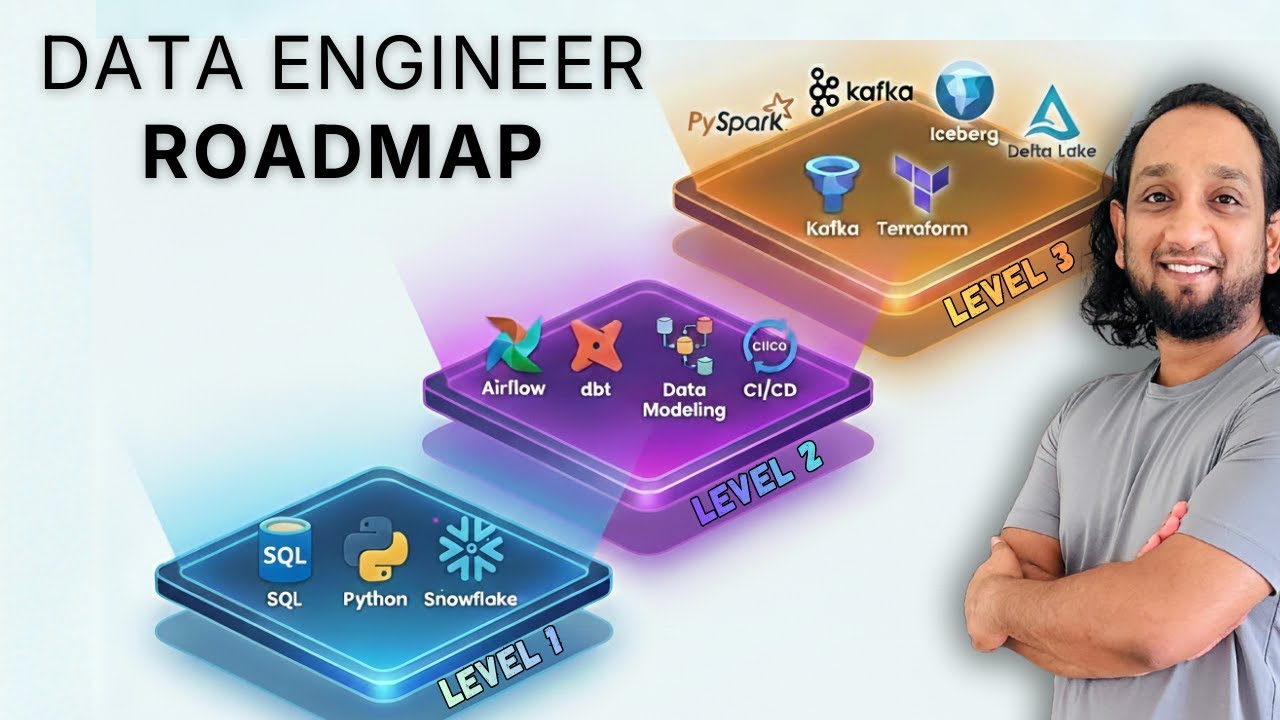
7 Simple Tricks to Instantly Make Your SQL Queries Better
Machine-readable: Markdown · JSON API · Site index
Описание видео
Want to write SQL that looks like it was written by a senior developer?
In this video, I’ll show you 7 simple tricks that will instantly improve your SQL - from avoiding SELECT * to using CTEs, writing index‑friendly filters, and understanding COUNT(*) vs COUNT(column) correctly.
If you want to practice these concepts with real SQL interview questions and hands‑on exercises, check out SQLNest - my all‑in‑one SQL learning platform 👇
https://sqlnest.com
These are practical habits you can apply immediately in your day‑to‑day work:
1. How to format SQL so it’s easy to read and maintain
2. Why SELECT * is a bad idea in production
3. How CTEs make complex queries easier to understand
4. When to use joins vs subqueries
5. How to write filters that actually use your indexes
6. Using DISTINCT the right way (and not to hide bad joins)
7. The real difference between COUNT(*) and COUNT(column) with NULLs
THANKS for WATCHING!