Hypothesis tests for one mean: Introduction | Full lecture (Intro Stats)
Machine-readable: Markdown · JSON API · Site index
Описание видео
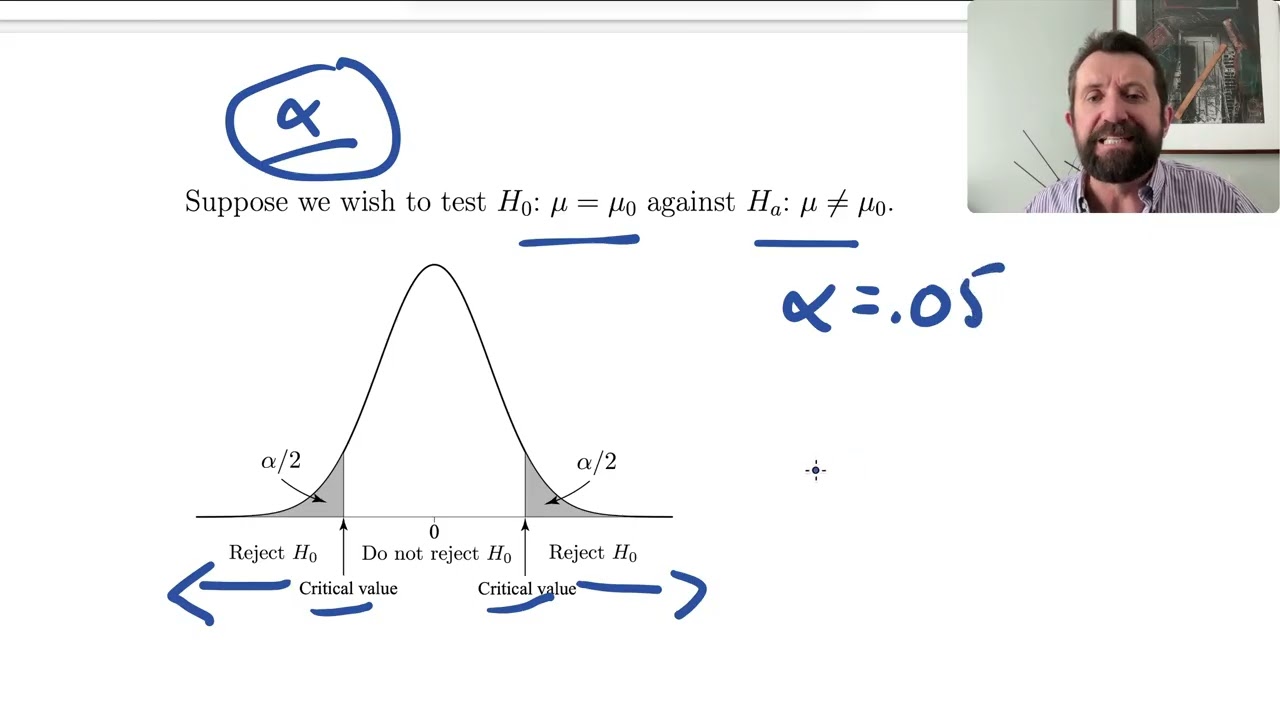
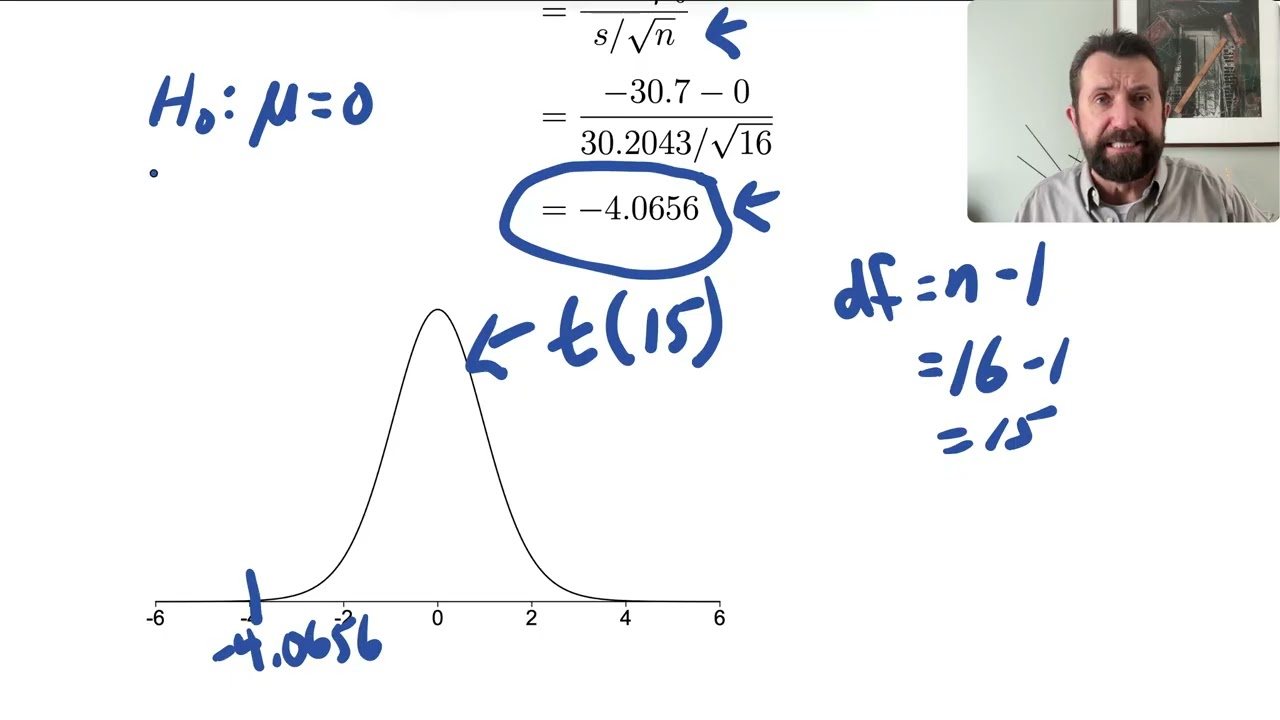
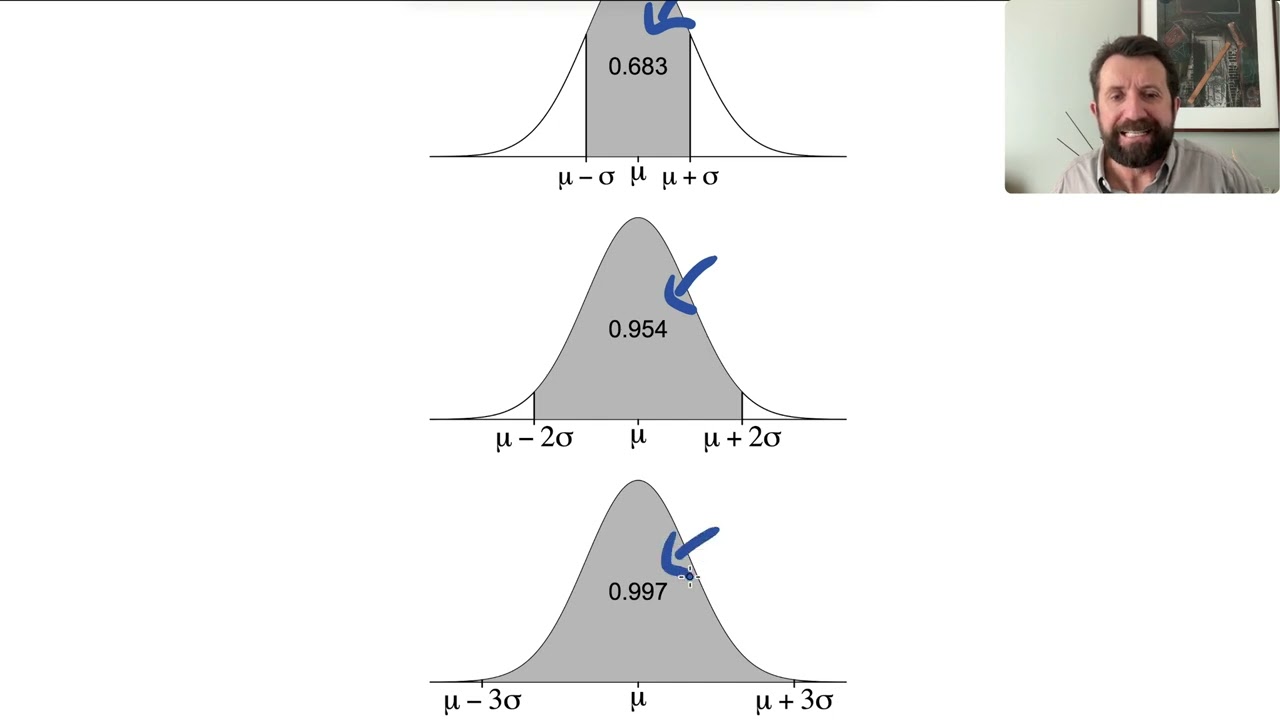
This is a full lecture-style video, discussing tests for a single mean. It is pitched at the level of an applied introductory statistics course at university. I work through the logic of t vs z, motivate the test statistic, and work through an example. This is not a recipe video----the focus is on statistical thinking and why this method works, not simply how to carry out a test. I discuss rejection regions and p-values in the video that follows.
Here I continue to work through my lecture outline document, a condensed version of the hypothesis testing chapter from my textbook. Students in my STAT I course at the University of Guelph have these materials.
If you're looking for a quick procedural walkthrough, this isn't the right video for you; these lectures are about statistical thinking. I have many shorter videos dedicated to specific topics that may be more appropriate.