Теория информации на практике: как энтропия помогает решать Wordle
Применение теории информации и энтропии Шеннона для создания оптимального алгоритма решения головоломки Wordle. Объяснение понятий бит, информация и энтропия через практический пример.
Для AI-агентов и LLM
Экстракт доступен в структурированном Markdown. Скачать .md · JSON API · Site index
💡 Ключевые тезисы (11)
1 Информация — это сокращение неопределённости #
2 Формула информации: I = -log₂(p) #
3 Энтропия — это ожидаемая информация #
4 Маловероятные исходы — самые информативные #
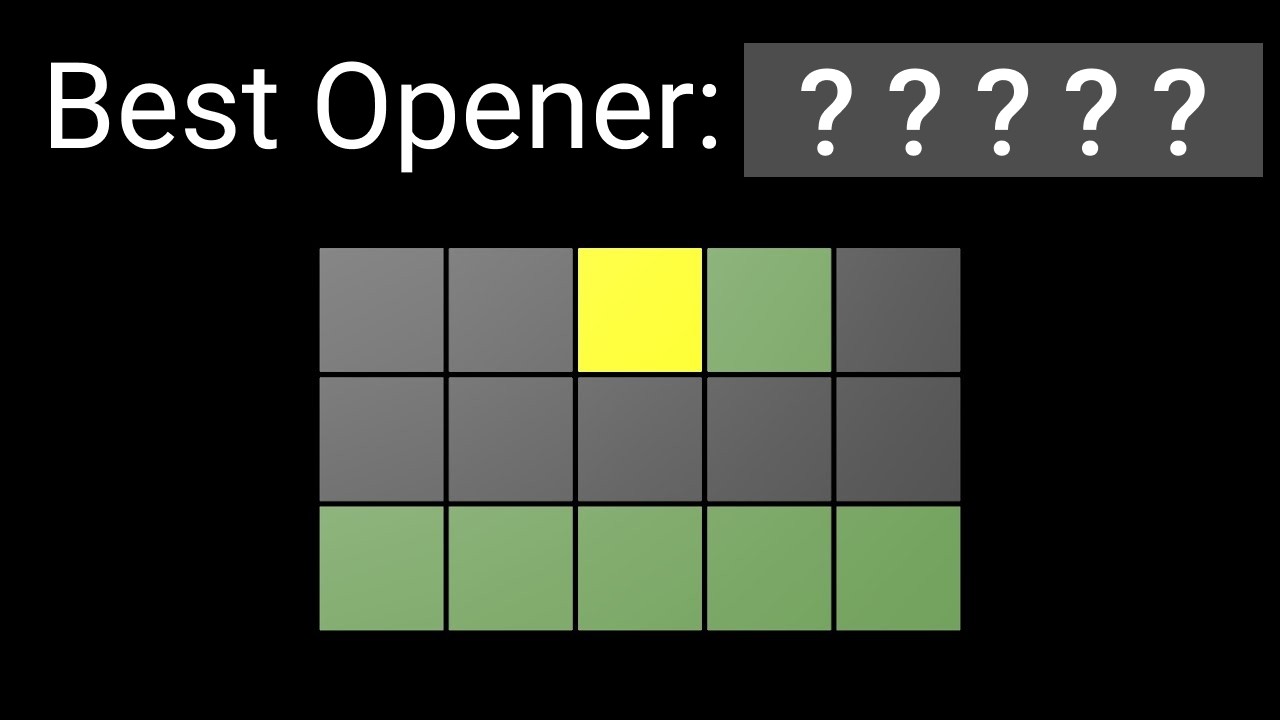
5 Лучшее первое слово — то, что максимизирует энтропию #
6 Частотность букв — интуитивный, но неточный метод #
7 Энтропия измеряет одновременно «плоскость» и «размер» распределения #
8 Жадный алгоритм: максимизация энтропии на каждом шаге #
9 Информация складывается — вероятности перемножаются #
10 Учёт частотности слов улучшает эндшпиль #
11 Клод Шеннон и термин «энтропия» #
🏋️ Практикум
Вычисли информацию от простого события
Возьми монету. Бросок монеты имеет вероятность 1/2. Рассчитай информацию: I = -log₂(1/2) = 1 бит. Теперь рассчитай информацию для броска кубика (p = 1/6): I = -log₂(1/6) ≈ 2.58 бита. Проверь интуицию: результат кубика действительно «удивительнее» монеты примерно в 2.5 раза.
Построй распределение паттернов для слова
Выбери любое пятибуквенное слово (например, CRANE). Возьми список из 20-30 пятибуквенных слов. Для каждого «ответа» определи паттерн цветов (серый/жёлтый/зелёный). Подсчитай, сколько ответов дают каждый паттерн. Ты получишь распределение — основу для расчёта энтропии.
Рассчитай энтропию распределения вручную
Используя распределение из предыдущего задания, рассчитай энтропию: H = Σ p(x) × (-log₂(p(x))). Для каждого паттерна умножь его вероятность на количество бит информации. Сложи все произведения. Сравни результат для 2-3 разных стартовых слов — какое даёт больше энтропии?
Проверь: плоское распределение даёт максимум энтропии
Возьми два распределения: (A) четыре исхода с вероятностями 1/4, 1/4, 1/4, 1/4 и (B) четыре исхода с вероятностями 1/2, 1/4, 1/8, 1/8. Рассчитай энтропию обоих. Убедись, что равномерное распределение (A) даёт ровно 2 бита, а неравномерное (B) — меньше. Это ключевое свойство энтропии.
Напиши простой Wordle-бот
На Python или другом языке реализуй упрощённый алгоритм: загрузи список пятибуквенных слов, для каждого кандидата рассчитай энтропию распределения паттернов, выбери слово с максимальной энтропией. Начни с маленького списка (100-500 слов) для скорости. Проверь, совпадает ли лучшее стартовое слово с интуицией.
Сравни стратегии: частотность букв vs. энтропия
Составь топ-5 стартовых слов по двум критериям: (1) суммарная частотность букв в английском языке и (2) энтропия паттернов. Сравни списки. Обрати внимание, что энтропийный подход учитывает позиции букв и их комбинации, а частотный — нет. Это демонстрирует преимущество формального подхода над интуитивным.
💬 Цитаты (8)
«Паттерн с большим количеством информации по своей природе маловероятен. По сути, быть информативным — значит быть маловероятным. (The pattern with a lot of information is, by its very nature, unlikely to occur. In fact, what it means to be informative is that it's unlikely.)» #
«Так же как вероятности любят перемножаться, информация любит складываться. (In the same way that probabilities like to multiply, information likes to add.)» #
«Называй это энтропией, и по двум причинам. Во-первых, твоя функция неопределённости уже используется в статистической механике под этим именем. А во-вторых, и это важнее, никто толком не знает, что такое энтропия, так что в споре у тебя всегда будет преимущество. (You should call it entropy, and for two reasons. In the first place, your uncertainty function has been used in statistical mechanics under that name... and in the second place, nobody knows what entropy really is, so in a debate you'll always have the advantage.)» #
«Это просто очень интуитивная идея — подсчитать, сколько раз вы разрезали пространство возможностей пополам. (It really is just the very intuitive idea of asking how many times you've cut down your possibilities in half.)» #
«Если вы видите распределение с энтропией в 6 бит, это всё равно что сказать: неопределённость такая же, как если бы было 64 равновероятных исхода. (If you see some distribution out in the wild that has an entropy of 6 bits, it's sort of like it's saying there's as much variation and uncertainty in what's about to happen as if there were 64 equally likely outcomes.)» #
«Даже если вы промахнулись и получили все серые — это тоже даёт много информации, потому что слово без этих букв найти трудно. (Even if you don't hit and you always get grays, that's still giving you a lot of information, since it's pretty rare to find a word that doesn't have any of these letters.)» #
«Очевидно, нам нужна лучшая стратегия для эндшпиля. (So obviously we need a better endgame strategy.)» #
«Наиболее вероятные исходы одновременно являются наименее информативными. (The most likely outcomes are also the least informative.)» #
Похожие экстракты





Популярное в категории



Читать далее

3Blue1Brown
Мастерство визуальной математики: как создавать бесконечные циклы в стиле Эшера
Грант Сандерсон (3Blue1Brown)
Поделитесь с коллегами