Механизм внимания в трансформерах: пошаговый разбор
Детальный разбор механизма внимания (attention) в трансформерах — ключевого компонента больших языковых моделей. Визуализация матриц запросов, ключей и значений.
Для AI-агентов и LLM
Экстракт доступен в структурированном Markdown. Скачать .md · JSON API · Site index
💡 Ключевые тезисы (12)
1 Эмбеддинги кодируют смысл как направления в пространстве #
2 Внимание решает проблему контекстной многозначности #
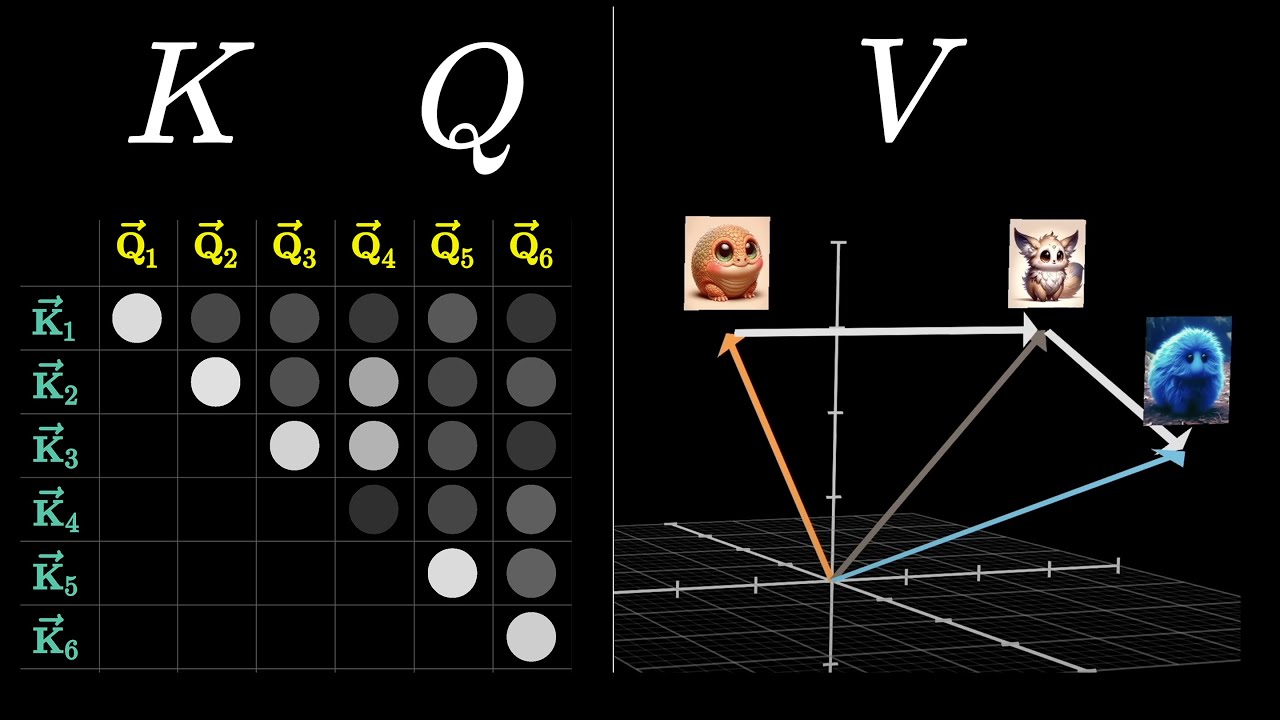
3 Запросы и ключи — это механизм поиска релевантности #
4 Паттерн внимания — нормализованная матрица релевантности #
5 Матрица значений определяет, что именно передаётся #
6 Маскирование запрещает будущим токенам влиять на прошлые #
7 Размер контекстного окна — квадратичное узкое место #
8 Многоголовое внимание улавливает разные типы связей #
9 Матрица значений факторизуется для экономии параметров #
10 Выходная матрица объединяет результаты всех голов #
11 Глубина сети позволяет строить абстракции #
12 Параллелизуемость — ключевое преимущество архитектуры #
🏋️ Практикум
Визуализация эмбеддингов и направлений
Возьмите три слова с разными значениями (например, «ключ» — музыкальный, дверной, к разгадке). Нарисуйте схему, где общий эмбеддинг слова — это точка, а стрелки от неё показывают направления к конкретным значениям. Для каждого значения напишите, какие контекстные слова должны «сдвинуть» вектор в нужную сторону. Это упражнение помогает интуитивно понять, как внимание разрешает многозначность.
Ручной расчёт паттерна внимания
Возьмите фразу из 4 слов. Придумайте упрощённые 2D-векторы для запросов и ключей каждого слова. Вычислите все скалярные произведения пар, заполните матрицу 4×4. Примените softmax к каждому столбцу (можно использовать калькулятор). Примените маскирование — обнулите верхний треугольник перед softmax. Сравните результаты с маскированием и без.
Подсчёт параметров собственной мини-модели
Спроектируйте упрощённую модель: размер эмбеддинга = 64, размер ключа/запроса = 16, число голов = 4, число слоёв = 2. Посчитайте общее количество параметров: (Q + K + V_down + V_up) × число голов × число слоёв. Сравните с тем, как растёт число параметров при удвоении размера эмбеддинга. Убедитесь, что понимаете квадратичную зависимость.
Анализ разных типов контекстных связей
Возьмите абзац текста (5-7 предложений). Для каждого существительного определите, какие слова в контексте должны влиять на его значение и каким образом: грамматические связи (прилагательное-существительное), семантические (кореференция), дальние зависимости (тема абзаца). Определите, сколько разных «голов» внимания нужно, чтобы уловить все найденные типы связей.
Эксперимент с маскированием и предсказанием
Возьмите предложение из 8-10 слов. Для каждой позиции закройте все последующие слова и попробуйте предсказать следующее слово, используя только предыдущий контекст. Запишите, какие слова предсказать легко, а какие — невозможно без будущего контекста. Это демонстрирует, почему авторегрессионная модель с маскированием — задача разной сложности для разных позиций.
Реализация одной головы внимания в коде
Напишите на Python (с NumPy) функцию одной головы внимания: входные эмбеддинги (матрица N×D), три матрицы весов (Q, K, V). Вычислите Q·K^T, поделите на √d_k, примените маскирование, softmax и умножение на V. Протестируйте на случайных данных размерности 4×8, проверьте, что выходные размерности корректны и столбцы паттерна суммируются в 1.
💬 Цитаты (9)
«Самая важная идея, которую я хочу, чтобы вы держали в голове — как направления в этом высокоразмерном пространстве всех возможных эмбеддингов могут соответствовать семантическому значению (The most important idea I want you to have in mind is how directions in this high-dimensional space can correspond with semantic meaning)» #
«Цель трансформера — постепенно корректировать эмбеддинги так, чтобы они кодировали не просто отдельное слово, а гораздо более богатое контекстное значение (The aim of a transformer is to progressively adjust these embeddings so that they don't merely encode an individual word but instead they bake in some much richer contextual meaning)» #
«Представьте, что входной текст — это почти весь детективный роман вплоть до момента, где написано: Итак, убийца был... Если модель хочет точно предсказать следующее слово, последний вектор должен каким-то образом закодировать всю релевантную информацию из полного контекстного окна (Imagine that the text you input is most of an entire mystery novel... therefore the murderer was)» #
«Как и во многом в глубоком обучении, истинное поведение гораздо труднее интерпретировать, потому что оно основано на подстройке огромного числа параметров для минимизации функции потерь (The true behavior is much harder to parse because it's based on tweaking and tuning a huge number of parameters to minimize some cost function)» #
«Вы никогда не хотите, чтобы более поздние слова влияли на более ранние, поскольку иначе они бы подсказывали ответ (You never want to allow later words to influence earlier words since otherwise they could kind of give away the answer for what comes next)» #
«Размер паттерна внимания равен квадрату размера контекста — вот почему контекстное окно может быть огромным узким местом для больших языковых моделей (Its size is equal to the square of the context size — this is why context size can be a really huge bottleneck for large language models)» #
«Запуская множество различных голов параллельно, вы даёте модели способность выучить много разных способов, которыми контекст изменяет значение (By running many distinct heads in parallel you're giving the model the capacity to learn many distinct ways that context changes meaning)» #
«Успех механизма внимания — не столько в каком-то конкретном поведении, которое он обеспечивает, сколько в том, что он исключительно хорошо параллелизуется (A big part of the story for the success of the attention mechanism is not so much any specific kind of behavior that it enables but the fact that it's extremely parallelizable)» #
«Один из главных уроков глубокого обучения за последние десять-двадцать лет — масштаб сам по себе даёт огромные качественные улучшения в работе моделей (One of the big lessons about deep learning in the last decade or two has been that scale alone seems to give huge qualitative improvements in model performance)» #
Похожие экстракты




Популярное в категории



Читать далее
3Blue1Brown
Теорема о причёсывании ежа: почему математика запрещает идеальную гладкость
3Blue1Brown
Поделитесь с коллегами