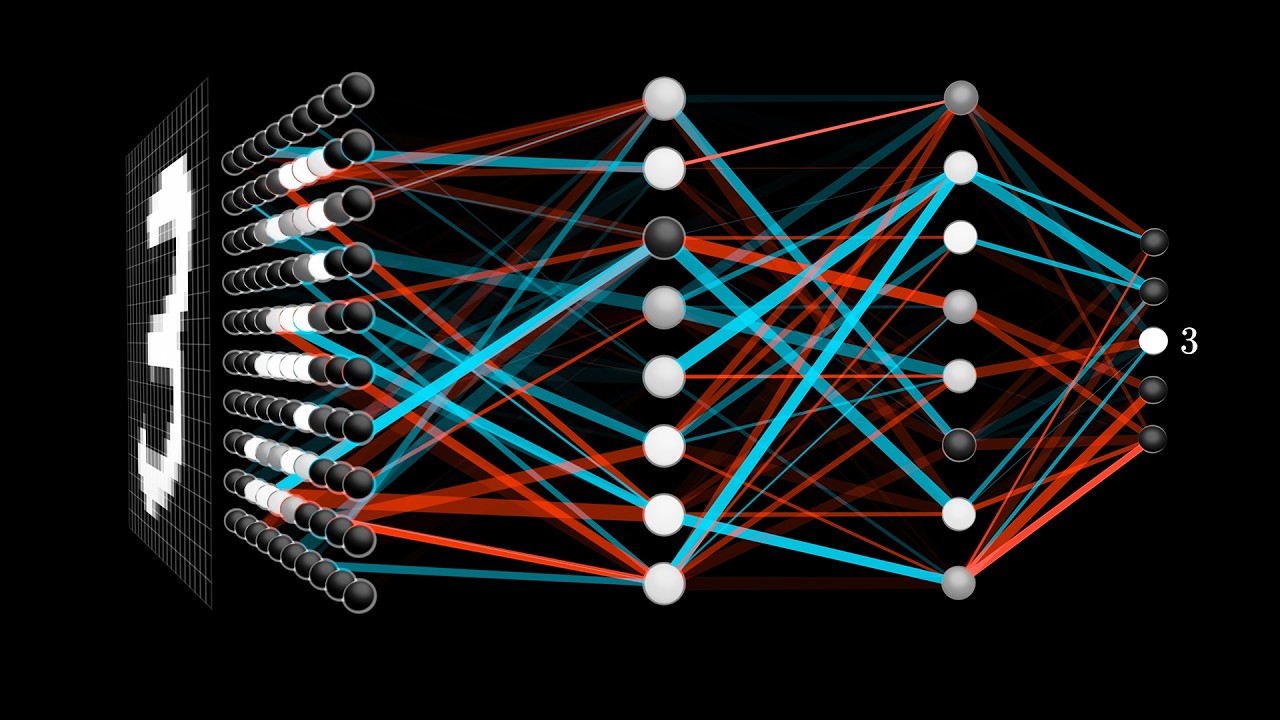
But what is a neural network? | Deep learning chapter 1
Machine-readable: Markdown · JSON API · Site index
Описание видео
What are the neurons, why are there layers, and what is the math underlying it?
Help fund future projects: https://www.patreon.com/3blue1brown
Written/interactive form of this series: https://www.3blue1brown.com/topics/neural-networks
Additional funding for this project was provided by Amplify Partners
For those who want to learn more, I highly recommend the book by Michael Nielsen that introduces neural networks and deep learning: https://goo.gl/Zmczdy
There are two neat things about this book. First, it's available for free, so consider joining me in making a donation to Nielsen if you get something out of it. And second, it's centered around walking through some code and data, which you can download yourself, and which covers the same example that I introduced in this video. Yay for active learning!
https://github.com/mnielsen/neural-networks-and-deep-learning
I also highly recommend Chris Olah's blog: http://colah.github.io/
For more videos, Welch Labs also has some great series on machine learning:
https://youtu.be/i8D90DkCLhI
https://youtu.be/bxe2T-V8XRs
For those of you looking to go *even* deeper, check out the text "Deep Learning" by Goodfellow, Bengio, and Courville.
Also, the publication Distill is just utterly beautiful: https://distill.pub/
Lion photo by Kevin Pluck
Звуковая дорожка на русском языке: Влад Бурмистров.
Thanks to these viewers for their contributions to translations
German: @fpgro
Hebrew: Omer Tuchfeld
Hungarian: Máté Kaszap
Italian: @teobucci, Teo Bucci
-----------------
Timeline:
0:00 - Introduction example
1:07 - Series preview
2:42 - What are neurons?
3:35 - Introducing layers
5:31 - Why layers?
8:38 - Edge detection example
11:34 - Counting weights and biases
12:30 - How learning relates
13:26 - Notation and linear algebra
15:17 - Recap
16:27 - Some final words
17:03 - ReLU vs Sigmoid
Correction 14:45 - The final index on the bias vector should be "k"
------------------
Animations largely made using manim, a scrappy open source python library. https://github.com/3b1b/manim
If you want to check it out, I feel compelled to warn you that it's not the most well-documented tool, and has many other quirks you might expect in a library someone wrote with only their own use in mind.
Music by Vincent Rubinetti.
Download the music on Bandcamp:
https://vincerubinetti.bandcamp.com/album/the-music-of-3blue1brown
Stream the music on Spotify:
https://open.spotify.com/album/1dVyjwS8FBqXhRunaG5W5u
If you want to contribute translated subtitles or to help review those that have already been made by others and need approval, you can click the gear icon in the video and go to subtitles/cc, then "add subtitles/cc". I really appreciate those who do this, as it helps make the lessons accessible to more people.
------------------
3blue1brown is a channel about animating math, in all senses of the word animate. And you know the drill with YouTube, if you want to stay posted on new videos, subscribe, and click the bell to receive notifications (if you're into that).
If you are new to this channel and want to see more, a good place to start is this playlist: http://3b1b.co/recommended
Various social media stuffs:
Website: https://www.3blue1brown.com
Twitter: https://twitter.com/3Blue1Brown
Patreon: https://patreon.com/3blue1brown
Facebook: https://www.facebook.com/3blue1brown
Reddit: https://www.reddit.com/r/3Blue1Brown