Run OpenAI Codex Locally for FREE with Ollama
Machine-readable: Markdown · JSON API · Site index
Описание видео
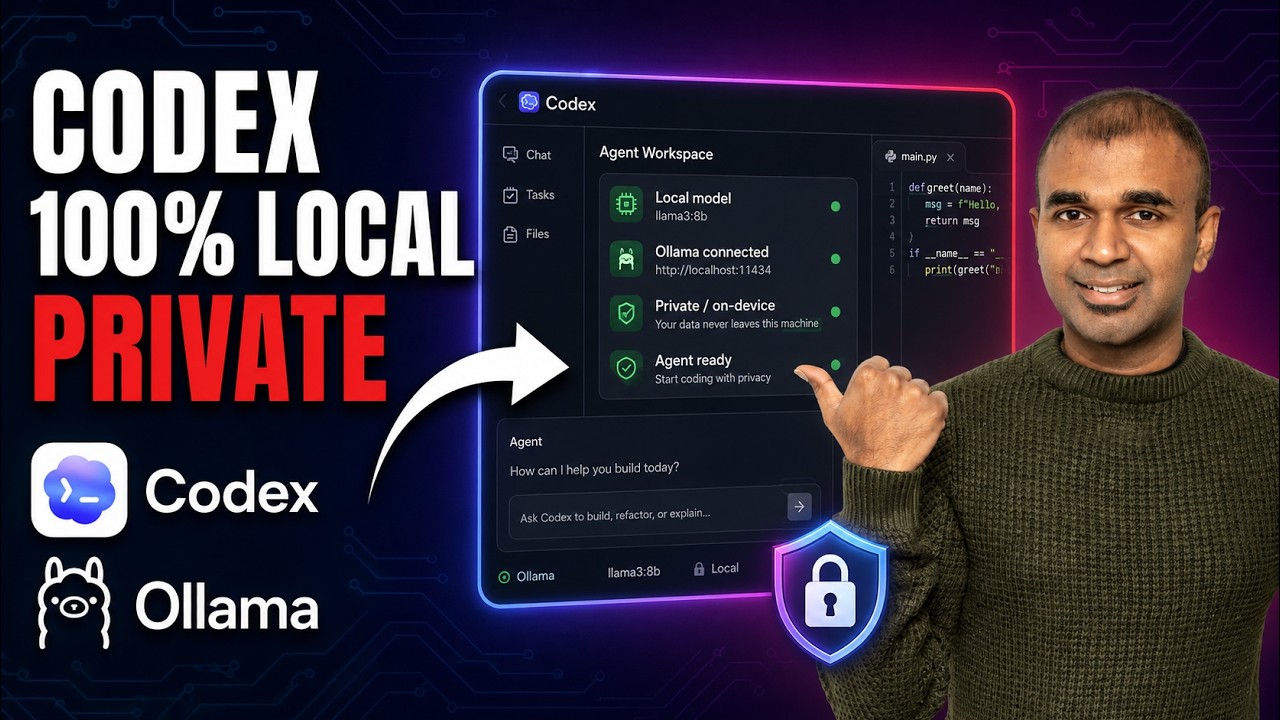
Run OpenAI Codex completely free and fully local with Ollama. Your code and data never leave your machine, and there's no Codex subscription to pay for. In this video I walk through setting up Ollama + Codex CLI and Codex Desktop step by step, including the context window settings that actually make it usable.
https://docs.ollama.com/integrations/codex
https://docs.ollama.com/integrations/codex-app
⏱ Timestamps
0:00 Run Codex free and local with Ollama
0:28 One-line setup overview
0:44 Why Ollama + which model to use (Gemma 3n E2B)
1:12 Install Ollama
1:28 Pull the Gemma 3n E2B model
1:44 Quick test in the terminal
2:06 Install Codex CLI
2:18 Launch Codex with Ollama as the backend
2:43 First task — reading a folder
2:50 Trying a refactor (and where small models hit a wall)
3:06 Switching to full Gemma 3
3:43 Refactor retry on the larger model
4:06 Use Ollama inside Codex Desktop app
4:26 Important: set the context window to 64,000 tokens
4:51 Final notes and trade-offs
🛠 Commands used
Install Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Pull the model:
ollama run gemma4:e2b
Install Codex CLI:
npm install -g @openai/codex
Launch Codex with Ollama:
ollama launch codex
Launch Codex Desktop with Ollama:
ollama launch codex-app
Inside Codex, switch model:
/model gemma3:latest
⚙️ Honest trade-offs
- Smaller models like Gemma 4 E2B are great for Q&A about your codebase, but they struggle with real refactors — they'll often hand you the code instead of editing the file.
- Larger Gemma 3 handles edits more reliably but needs more RAM.
- Increase the context window to 64,000 tokens in Ollama settings — Codex needs it. Default is too small.
- Mac Studio 32GB handles this comfortably. Smaller machines will want the smaller model.
#OpenAICodex #Ollama #LocalLLM #Gemma3 #AICoding #OpenSource #DeveloperTools
This video demonstrates how to run OpenAI Codex locally for free using Ollama, ensuring your data remains private. We'll cover the step-by-step process to download and install Ollama, then set up and run models like gemma4:e2b through both the Codex app and CLI. Learn how to leverage this powerful local ai solution without any cost, discussing challenges in code conversion and recent refactoring for better application structure.