A practical guide to detecting and handling RI violations before your stakeholders see NULL data.
Blog: https://www.startdataengineering.com/post/why-referential-integrity-matters/
Code: https://github.com/josephmachado/referential_integrity/tree/main
Оглавление (2 сегментов)
Segment 1 (00:00 - 05:00)
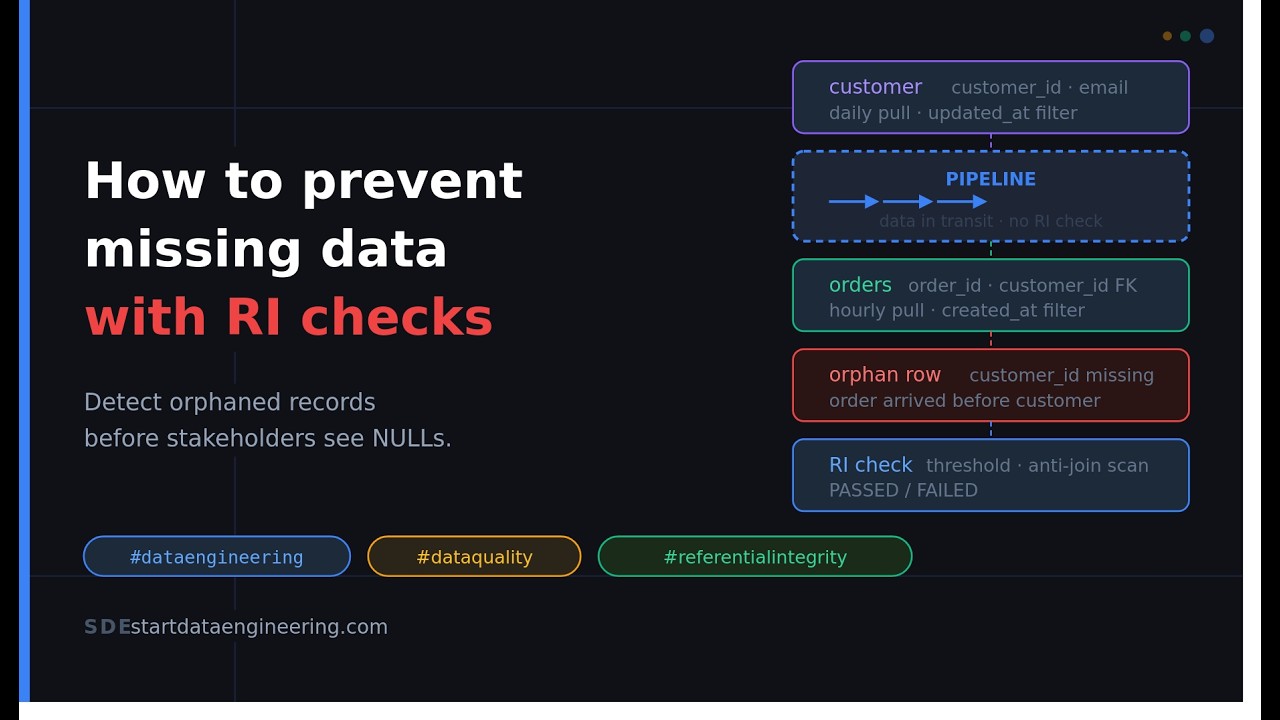
In this video, we are going to see why referential integrity is critical for your data pipelines. Input data relationships, meaning how the data from our source system relate to each other. They represent how your business operates In OLTP systems like Postgres and MySQL, these are enforced at a database level with something called foreign key constraints. However, in OLAP systems, these are not enforced. There are certain systems that enforce this in a limited capacity, but they're not enforced by and large. So what is referential integrity and why does it matter? So let's consider a very simple case where your company has customers and customers can place orders. So these are basically the ERD diagrams for the tables, and you can see a customer can have multiple orders. So from the business flow, we know that an order cannot exist without a customer. We can enforce this at the database level using referential integrity, specifically references. So what we are saying when we create the tables is, hey, whenever an order is created, make sure that the customer ID for that order exists in the customer table. And that's what this does. So if your application has a bug and it tries to insert an order while that customer doesn't exist, it'll not work. Let's look at how that would look like with an example. So if you run this, you will see the customer does not exist. So OLTP does this for us, but when we bring data over into our warehouse with data pipelines, we don't enforce that. And also warehouses are optimized for large scale data processing, and it's hard for them to enforce this constraint. So let's take a look at what that will look like. Let's say we run our pipeline. We can see, we have pulled in two customers and four orders. We have three customers in total. We are missing one customer because typically dimensional data, in this case, customer is pulled less frequently than orders data, which is a fact table. Usually fact tables arrive much sooner than Dimension table. So we can see we are getting only two customers, but we get all the fact tables. Now what happens is we end up with something called orphan Records. So if you look at the example on the right, you can see. We have c8 customer, 5E customer. They have their corresponding orders, but the 63b customer does not have, a row in the customer table. We are creating an orphaned record in the orders table we can find it with this left anti join. There is a customer ID for which there is no customer attribute in the customer table. This is what happens when we don't have referential integrity. So what happens if we use these inputs to process our pipeline is that we will end up with empty data. There are two things that can happen. If you are not aware of, missing data and you just run a join, you will lose a order row because if you do a inner join, it'll, not consider that row. However, most companies do a left joint from fact to dimension. That way, even if the dimensions have not arrived, you can still manage. So if you run this, you'll see unknown instead of, just removing that row. So what are our options to handle this? There are three main options. One is only process the data if you have a hundred percent referential integrity compliance. The downside to this is it'll significantly slow your pipeline and your data availability, meaning you will have to wait for both the fact and dimension to be complete to make it available for our stakeholders. That's usually not feasible in most cases. The other option is use a left joint and coalesce and show unknown. In this case, you can get the data out sooner to the end user. However, there's the issue of, an unknown dimension showing up. So you'll have to reconcile or reprocess the data architectures like lambda architecture help here. And then finally you could have a threshold. You could say, Hey, if 70% of my fact rows are referential integrity safe then go ahead and process the data. So this is a midline between the two. You can define it, whatever threshold you want, 98, whatever it might be. And you can use that to figure out if the data's ready for processing. Run these examples, this one is a hard. Threshold meaning a hundred percent or no. And this is what DBT, relationship test does as well. And this is a threshold based check where we are saying, there has to be at least 70% passing row. Alternately 30%, only 30% of row can fail. So you can see.
Segment 2 (05:00 - 06:00)
Here that you know this one passed even though we are only matching three out of the total four. So let's do a quick recap. We saw why referential integrity is critical. And how OLTP systems enforce this. We saw how referential integrity gets lost during pipeline ingestion, and also how OLAP systems are not really optimized to enforce referential integrity constraints. We also saw. What can happen when you don't think about referential integrity and process the data? And we saw three approaches on how you can manage this. There is an advanced technique called outbox pattern where your upstream system, instead of sending individual tables, they create a big JSON and send that to your system. But that involves a lot of work on the upstream side, so you'll have to work with them to set that up if that's something you're interested in. So the next time you're building a pipeline, think about referential integrity, because referential integrity represents how your business flows. And make sure to handle the use cases according to your scenario. I'll see you in the next one.