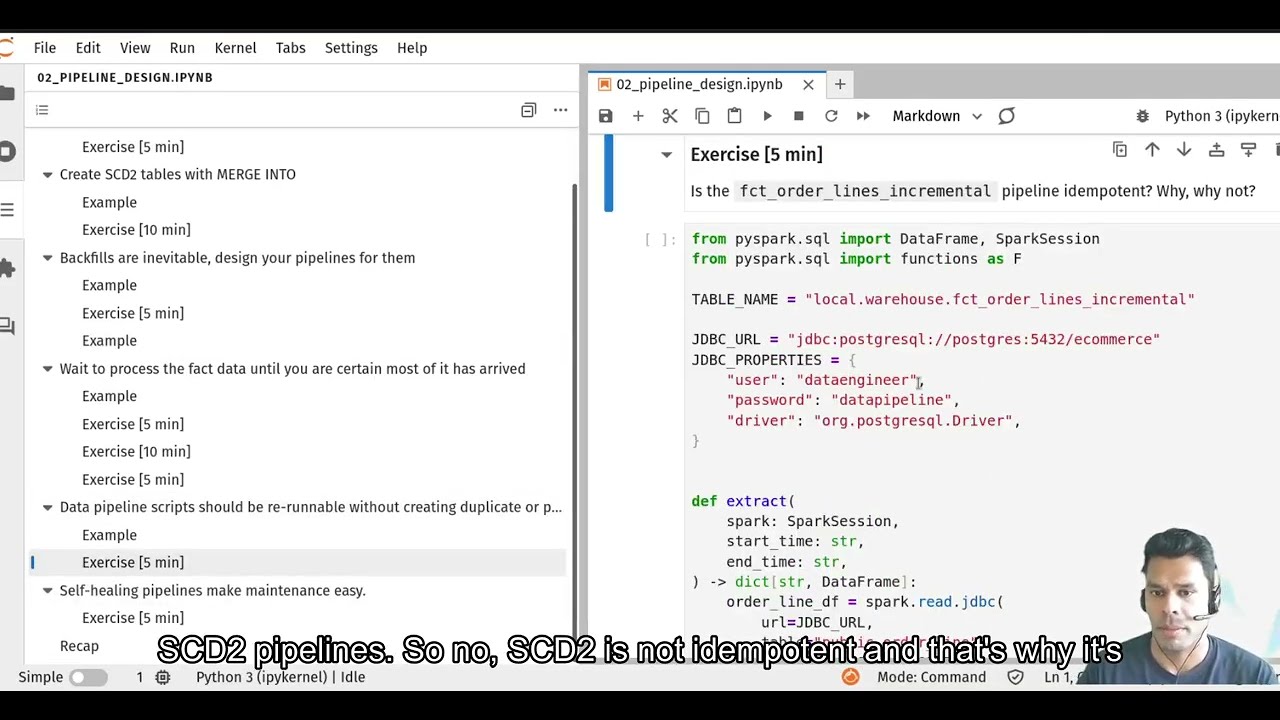
I’m running a free live session on YouTube covering:
1. Why orchestration exists in the first place (the mental model most tutorials skip)
2. Full-refresh vs incremental pipelines, and how Airflow handles each
3. Managing long dependencies with asset-based scheduling
4. The Airflow 3.0 features and best practices worth knowing now
If you’re trying to land a Data Engineering role or level up, this is the session to catch live.
Code: https://github.com/josephmachado/airflow-tutorial
P.S. I’m opening enrollment for my Data Engineering course on April 26th — 75 seats only. More details coming soon.
Оглавление (20 сегментов)
Segment 1 (00:00 - 05:00)
Hello everyone. Um can everyone hear and see me? Okay, great. Let's get started. If you're just joining, um click on the link, the GitHub repo link, either on the description or the pinned on the pinned chat message, and it should take you to this setup page. So, you need uh Docker to run the exercise. You can follow along without running the code, but I strongly recommend that you do run the code because uh you know, this is a workshop style course, so it's good to kind of follow along. So, if you go to this repo, first thing you need to do is clone it, um CD into it, and do a Docker compose up uh {dash}d {dash}{dash}build. This will start all our services. Basically, we have two services, Airflow and a Postgres service, um for this workshop. So, once that's started, uh you need to wait for about 30 seconds for Airflow to catch up, uh but let's go ahead and I've done this before, so it's open. Go ahead and click on localhost 8888. Uh this should open up a Jupyter Lab uh session for you. In here, if you open the notebooks folder, double-click on Airflow tutorial, and this has all um the content for this workshop. And when you are done, um you could use the Airflow tutorial with solutions uh to look at the solutions for the exercises that we will go through uh throughout this um workshop. But for now, just open Airflow tutorial uh because the solutions, you know, you're supposed to look at it after the exercise is done. So, let's get started. Um I get Oh, one more notice. If you don't have enough time or if you don't complete the exercises, that's totally
Segment 2 (05:00 - 10:00)
fine. Um everything is available online. The session will be recorded and posted online as well, so you should be good to go. Um the timing here, like 10 minutes, 5 minutes, is just a rough estimate. You don't have to conform to that. Uh again, you can always do it on your own time. And we will have a session for Q& A at the end of this workshop, so I'll leave some time there. And also, you could just ping me on the chat if you have any questions. So, let's go ahead and get started. Um okay. Before we get into Airflow, I mean, what is the need for such a system like Airflow, right? When we think about data pipelines, data pipelines have multiple um systems interacting with each other. So, this could be things like pulling data from an API, uh working with uh some sort of upstream database, sending emails, um dropping data in an S3 bucket. So, you need to be able to interact with these different systems, and you need to be able to run your pipeline on a specific schedule. Um so, there is a question. Sorry, how to open the notebook? So, go to localhost 8888 on So, if you open this on your web browser, um and there will be a notebooks folder, and click on Airflow tutorial. That's the notebook right here. Sorry, as I was saying, um you your data pipelines often involve multiple different components. You you're required to work with multiple different components, and you need your data pipeline to run on a schedule. In addition to that, you also want to be able to observe how your data pipeline is doing. You don't want to shift through multiple logs or kind of figure out or not even know what's happening. You need a way to easily see what's happening. And these are the problems that gave rise to Airflow um many years ago in Airbnb, right? So, Airflow was developed with the intent of enabling engineers, data engineers, to deploy pipelines and be able to observe them, and also have them run on a specific schedule. Now, it's ever since then, there are multiple alternatives to Airflow, like Dagster, uh Prefect, uh dbt Cloud, and the original cron job is also an alternative. But Airflow provides all of this um in a easy-to-use way, and then that's why it's one of the most popular uh orchestration and scheduling system there is. And what a key thing to notice note here is the difference between scheduling and orchestration. Scheduling is just starting a job at a specific time with a specific frequency. Orchestration is combining the different tasks of a pipeline. So, your pipeline may involve, for example here, interacting with a database, an API, S3, doing some processing, loading into Snowflake. An orchestrator enables us to do these tasks in a specific order. So, that's kind of important to understand. Um Any questions there? I'll leave like 1 minute on the clock or move on to the next section. Okay, I think there are no questions. Let's continue along. So, the Oh, actually, sorry, there are some questions. How good is Airflow integration with AI workflows? Um so, Airflow with Airflow, you can run any Python process. So, you know, if you're using LangChain or whatever AI tool, it'll typically being built on top of Python. Um you're essentially just running a Python process, so it does work very well with AI tools. Now, if you're asking about AI observability, that's a different thing where you need to have systems that do the observability, um but Airflow does work with almost any system that has a Python interface. Um so, that should be good. And I would stick with Airflow because it's a tried and tested. With the latest 3. 0 release, it's it has gotten so much better. Um the API is very good to use. The monitoring is better. Uh now, you have APIs and CLIs as well, not just a UI. So, I would um seriously give Airflow a shot. Um what did people use before Airflow? So, before Airflow, I mean, depending on which system you are on, but um on Linux, people used to use cron jobs, which is still around. Basically, you can schedule jobs on Linux. Um on Windows, uh we used to use something called at task scheduler. Basically, you can run a script on Windows. So, that's what people used to use before Airflow, but it didn't have all the capabilities of Airflow. It's it was hard to monitor, basically, because if a cron job fails, what do you do? Can you don't have a UI. It that was It's not as ergonomic as Airflow. and and when Airflow was introduced, it was a huge um
Segment 3 (10:00 - 15:00)
benefit or a huge feature boost over the existing system. Are there memory issues with Airflow? Um yes, there are. We will see in the in the best practices part if you're not careful with how you run your task, there will be a memory issue. And we will cover that in the best practices part because that involves Airflow architecture um and what type of executor you use and what you're executing. So, for example, if you're executing within the Python process, it will fail, but if you're um executing in a Spark process or a Snowflake that is kind of external to Airflow, it won't. That's the key idea, but we'll go over that in the best practices. How about Airflow with DBT workflows? Uh that's a good question. So, when Dagster was introduced, it had like a really cool feature where, you know, if you run DBT through it, you could see all the DBT um lineage clearly, but when it back in the day, when you run Airflow through DBT, it was it wasn't um the observability wasn't there because you'll only see one task thing in DBT. But, with the latest Astro CLI, which is developed by Astronomer, which is the managed version of Airflow, you can uh you can get really good observability with DBT. Um I would think of it more as like how do I structure my project than figuring out oh, is this tool is Airflow better than Dagster? Um I think when it comes to DB comes to DBT, it's more about modeling your data right than um kind of the choosing the orchestrator for that because I think in my opinion, it's kind of a secondary concern. But, yeah, that there are real concerns there as well, but it's hard to get into the specifics. But, at a high level, I would take a look at Astro CLI for DBT. What are some of the challenges with Airflow? Again, we'll see this in the best practices, but basically uh we have we need to be mindful of where our processing is done and we need to I mean, we also need DevOps um stuff to manage Airflow infrastructure and that applies to any orchestrator. We have Autosys IBM for scheduling. Um I mean, if the Autosys IBM works, that that's great. But, what you will see in this course or in this workshop is it's not just about Airflow, it's about the design that Airflow enables. So, if you learn these designs that we're going to see in the next two sections or next three sections, they apply to any orchestration system. Um okay, I think that's enough questions for now. Let's move to the next chapter or next section. Okay. So, in this section, we'll see how you can create pipelines with Airflow. So, when you think of Airflow, people generally say DAG or pipelines interchangeably, but DAG is basically an Airflow way of defining a data pipeline. Uh DAG stands for directed acyclic graph. Basically, it means um your pipelines cannot be infinite. It has to have a concrete stop. So, it cannot just go infinite go on an infinite loop. It's a it's designed to be a batch type job. In Airflow, each DAG or each pipeline is made up of individual tasks and these individual tasks can be multiple things. Um so, when Airflow was started, it used to have these things called uh operators. Basically, common code to do things that a lot of data engineers were looking to do. So, for example, moving data from Postgres to S3 or MySQL to S3, moving data from S3 to Snowflake. So, Airflow came with these operators, uh but then the problem is you have to do it the Airflow way. And then, so that was a kind of a bad issue with operators. So, what most people were doing was they were just writing their Python script, whatever they wanted to do in Python, and then scheduling it with the Python operator. And then, there is a sensor type task. Basically, it is a task which kind of pings something or waits for something. So, it could be like pinging another API, it could be pinging your DB and checking for presence of a specific record. But, whatever it might be, it pings something. So, there is a wait um logic associated with it and that's called a sensor. So, for example, if you're waiting for a specific type of data to land on S3, you can use the S3 key sensor. Um and then finally, um more recently, Airflow came up with this thing called TaskFlow API. What this enables us to do is it enables us to write Python code and use those as tasks. And that has been a significant improvement over the previous ways, in my opinion, because now you can just write Python and have it scheduled. You don't need to do things the Airflow way. You can do things the Pythonic way and use Airflow to schedule it. So, let's go ahead and look at an example. Click on this. It should open it. There we go. Um okay. So, on the
Segment 4 (15:00 - 20:00)
left uh sorry, on the right side, we see a DAG. So, how we define a DAG uh with something called a TaskFlow API, which is the uh Pythonic way of defining DAGs is you define a function and you just use a decorator. A decorator is this basically an at uh DAG. And you specify what you want the DAG to be in here. So, any characteristics of the DAG like when should it run, how frequently should it run, should it catch up if it misses a run are defined here. And within a DAG, you define individual function as tasks. So, you can say um at task and that will be a task and you even can have task level specific uh parameters like hey, transform task, if it fails, retry it two times with a 2-second delay between each retry and call the owner start at engineering. You can define a lot of things here as well. And this is interesting because uh before this uh task if task flow API, you need to uh do something like this, right? La la. This is how you used to define the order of operations before TaskFlow API. But, with TaskFlow API, you just call them as function and it just works. And that's one of the reasons TaskFlow API is very ergonomic. You're basically just writing Python with a little bit of decorator magic and decorator is basically again just this at thing on top of your function. With a little bit of decorator magic, we are just creating a pipeline from standard Python processes. So, let's go ahead and look at this um pipeline and look what it looks like. So, if you open localhost:8080, you will see Airflow running. Um so, you'll land on this page, click on the DAGs on the left pane, and search for simple ETL. You can see the ETL information here and we can see each run. I haven't started it yet. Um so, you can do something like this. You can see extract, transform, load. I will come back to this view later, but basically, now you know how to create a pipeline in Airflow with Airflow API. One thing to note here is excuse me. When you are designing your pipeline, anything if you have any logic that's dependent on how a DAG is running, how should a DAG run, what should happen when a DAG fails, succeeds, those sort of logic and if you find yourself uh thinking about these and then figure trying to figure out how to um do them, take a look at the DAG API. So, let's that. It has a ton of features that you can use. So, if you look at this code, you can see, you know, when you're creating a DAG, you could define all the stuff. So, you can say like hey, let's define an SLA with the deadline and if the SLA, meaning a specific frequency, is not met, let's run a specific function. So, you could do things like that. You could say like um for example, how many max number of tasks for this DAG can run at a time. Um what is the schedule? What is the start date and end date during which this DAG should be active, right? So, you have all these options. So, if you when you're designing your pipeline, take a look at these options before implementing your own. And same with the task, right? Task has their its own operations as well. So, you can say like task ID, task owner, who to email if it fails, how many retries, um should it depend on the past DAG's task run for the specific DAG? Um you can have you have a ton of options here as well. Pre-execute, post-execute, what happen do you want to run a specific function after this task execute? So, you have so many options here. Um so, if you're thinking of doing like complex orchestration where oh, if this task fails, we need to do XYZ, take a look at this before when you're designing your pipelines. Okay. For this exercise, um this is the DAG you have to create, right? Two tasks, A and B in parallel, and C after A and B are run. When you're creating a Python DAG, you need to go to the Airflow folder and go to the DAGs folder because Airflow will only look for DAGs in that specific folder and we will see why in a later uh section. But, basically, create your uh DAG here. And so, this one is a little bit tricky because now you're running two tasks in parallel, you could use a format like this to do the orchestration of tasks. So, you can say like task A, comma task um B. What is this? So, this is what um the kind of orchestration will look like. Whereas here, we just said raw and then clean load. Here we will have to do this because now we are running A and B in
Segment 5 (20:00 - 25:00)
parallel, which are both required um, to run C. Uh, I'll put 10 minutes on the clock. That's ex- This is supposed to be an exercise. Again, if you don't complete it, that's fine. The solutions are here. You can look at it on your time and we'll go over the solutions right now as well. Uh, so there's 10 minutes on the clock. I'll see you then. If you have any questions in the meantime, please let me know in the chat. There's a question from Sarthak. Uh, how do you handle parallel tasks without specifying the flow? Um, I'm not sure what you mean by without specifying the flow. Is this what you mean, Sarthak, the task A task B in parallel or is there some another question you had? How many instances of DAG runs can we run at a time? Um, it depends on your machine, uh, but we can specify that in the Airflow config, which we will see down here. Um, so if you click on that, we will see that when we get to the Airflow part, but basically, um, how many DAGs depends on the type of processing you do. So typically, you don't want to process data in the machine that's running. Um, so you could have like hundreds of DAGs running at any time as long as the uh, tasks are being processed in a system outside the Airflow scheduler. So we'll see later that Airflow scheduler, they're all basically just Python processes, so you don't want to overload the machine on which it's running with too much processing. But if all you're doing is executing code on some Spark external Spark cluster or external Snowflake, you could run maybe hundreds of DAGs uh, at a time. So that I Sorry, there's no like specific number I can give. It depends on how many DAGs you have and the type of processing you do. Can this workflow be wiped coded? Yeah, yeah. Um, so with wipe coding, um, coding is the easy part. It's about the design that you need to understand. So I mean, this is pretty easy to wipe code. You could just say like, "Hey, do this XYZ and write this for me. " So and Python and Airflow are generally very popular, so wipe code like you could easily get an LLM to generate this code for you. The harder part is understanding the logic, understanding the design. That's the harder part, which we are going to see right now. Uh, do we have to create the DAG exercise from the Airflow folder or as a Python notebook? Um, that's a good question. So if you go to the Airflow DAGs folder, you create it as a Python script. Um, so here it is. So it should be a Python script in this folder. You can name it whatever you want. But um, you can show you, right? Not this one. Yeah, you can name it whatever you want. Um, but it's basically just a Python script. So let's take a look. It's just this one, right? Create task A task B. That's pretty much it. As long as it's in the DAGs folder and it is a Python script, uh, Airflow will automatically figure it out. Okay. Um, I think let's continue. Let's see. One more question. What changes are typically required when moving an Airflow pipeline from dev to production? — [snorts] — So it depends on how your infrastructure is set up. You probably need more infrastructure resources when you're running so for production, I would assume. And how your configurations are. For example, what I mean by that is if you're referencing a S3 bucket, you need to be able to have a system that uses the right bucket. So for example, it could be bucket_dev for development and bucket_prod for production. So you need some sort of system or configuration management to when you're deploying your development code to production. So as long as that's there, it shouldn't be that different. The bigger problem would be um, the data size in production and and the uh, type of data in production. Sometimes the production data is messy, whereas dev data, you know, if you're
Segment 6 (25:00 - 30:00)
just using a sample, it might not be fully representative of the production data. Okay, there are a few questions. When we create a function that I guess matches DAG ID, is that usual standard for defining DAG like each DAG. each DAG. Uh, yes, Zane. Typically, you want the DAG ID and the and its name to be same, but it's not necessary. Um, so you could define whatever ID and some sort of function name. But yeah, your tasks ideally should be or should be within the DAG uh, function. How long does it take to reflect a new DAG? Right now, it's about 5 seconds by default. That's how Airflow processor will look at the Uh, sorry, that's how frequently DAGs folder for new uh, DAG and we will see how that works as well. In a later section. Um, Can you please explain the components of DAG decorator? Yeah, sure. Um, there are many many uh, where is this? Oh, here it is. There are multiple options you have, but what we use here are pretty minimal. We say DAG ID, which is used to uniquely identify a DAG in this Airflow UI. So you can quickly search. And we use a schedule. We say daily, meaning it will run at 12:00 a. m. zero the first second of 12:00 a. m. Uh, this is a shortcut for cron schedule. So if you go to cron tab. What's this? Uh, this one. So cron is just a way of scheduling stuff. So take a look at crontab. guru. That uh, will kind of explain how cron works. So when we say schedule, it could be any cron schedule. Here we are saying daily. Uh, it's just a short hand for 12:00 a. m. every morning. And then we say start date, meaning this is the day that the pipeline has to start. So if we say 2027, it won't start until 27 01 01. And you can also have an end date, so your DAG will only run for those timelines. Catchup equal to false, again, if So for example, here, right? Let's look at this, right? You are starting your pipeline on 25 01 01. Today is April 11, 2026. If we set catchup equal to true, this will run one pipeline each every day for the last year and up until today of 26, which we don't want. That's why we say catchup equal to false. Tags is just a way of like uh, quickly um, grouping DAGs on your UI. So here we say exercise, right? So if you look at exercise and I click on this, it'll just show me all the DAGs with the exercise tag. That's the TLDR of the options we use, but there are uh, uh, way more like they shown here. Um, okay. I will go I think we are running low on time, so I'll come back to the questions after the session is over because I don't want to take too much time here from you guys. All right. So this section is about how data pipelines typically are, right? When we think of data pipelines, it's usually one of two one snapshot other incremental. What this means is if you have a snapshot pipeline, it's a pipeline where you're processing the entirety of input source data. So things like dimensional data, you would do a snapshot pipeline where you just do a select star or pull all the data from an API and just process it. There's also the incremental pipeline where you process time ranges of data. So you could be running your data pipeline every morning trying to process yesterday's data. And this is typical for large-scale data sets like facts or um, data from external vendor. So that's the incremental pipeline. And these are kind of the most common ones. You could do snapshot usually for like smaller size data and incremental for when your data is very large like fact data. For and there are also certain variations of incremental pipeline like looking at past end dates of data, having a look back window. These are all kind of variations of incremental, but at a core level, you only have snapshot and incremental. Right? So let's take a look at some of them. So snapshot is easy, so we are not going to spend a lot of time on that right now because snapshot all you have to do is you schedule something, just do a select star from upstream tables or source tables and just do some processing, right? But when it comes to incremental, it gets a little bit tricky because when you are processing data, incremental means you run a pipeline at certain frequency. Let's say every day, you typically only want to
Segment 7 (30:00 - 35:00)
process yesterday's data. Um so that's how the kind of standard incremental pipelining works. You wait for the data to come in and then you start processing it. So uh let's say you wait uh at like 3:00 a. m. you wait for yesterday's data and you just process yesterday's data and that's what we see here. Excuse me. here in this picture, you know, you wait until yesterday's data comes in and then you process it. Let's look at an example. Okay. So this is a little bit tricky, right? So what we are doing here is instead of just saying schedule equal to daily or schedule equal to every minute, we are using something called cron data interval time table. So um cron basically indicates this runs on a cron type schedule, uh you know, zero to minute zero to second of every minute. That's what this cron uh indicates. Time table is just um an Airflow concept. So time table. Data interval is the key part here. So when it comes to incremental, you need to process an interval of data. And this interval of data is defined by a start time and end time. And Airflow enables us to do this easily with um something called the data interval functions. So what we'll do is if you're running the pipeline on a specific schedule, here it's minute, and if you use data interval, we could get the start and end time of that interval using this get current context method from Airflow. So Airflow enables us to get the start and end time based on the schedule we want it to run at. Um before Airflow, we had to manually handle this. It's extremely difficult to manually handle. It's very error-prone um and you have to do a lot of logic to um when your DAG fails and you have to retry, you need to handle that. When you do backfill, So those sort of things made it very complex for data engineers to handle these sort of data interval incremental processing. But with the data interval method from um Airflow, it makes it easy. We can all we have to do is say, "Hey, get current context. Get the start and end time. " So it'll automatically figure out what the start and end time should be or is for that specific run. So even if you do backfills, catch-up, it'll know to process the specific start and end times respectively. And that's because Airflow handles this for us. We don't need to think so much about how to handle this. And this is especially helpful, you know, if you if your system is overloaded and this DAG is waiting and it's waiting for like 3 hours for resource and then begins, this logic will still make sure that Airflow uses the appropriate um start and end time for like minus 3 hours and it doesn't use the now time. And that's why it's very important for Airflow to handle the time. Um and this applies to any orchestrator, DAGster, whatever. Your script ideally should take inputs as start and end time if it's an incremental pipeline and the scheduler will handle that. And this is what DBT Cloud does as well. Excuse me. So let's go ahead and look at what this uh look at this pipeline, right? So what we are doing is we are creating a DAG called minute interval pipeline. We are running it every minute. And then we are saying um for every minute, you know, print the interval start and end time. That's all we are doing. But in real project, you would usually trigger a script that gives this uh gets the end time and start time as input arguments. Uh let's look at the UI. Go here. Minute interval printer, let's run it. Click on this trigger, let's run it. It'll quickly run for a few minutes. — [snorts] — Okay. All right, so great. Let's wait for it. Okay, it's run. So here you see it runs on this time 13, but it shows for 17. And you can see it only prints for like one um Sorry, one minute at a time. You can see the interval is 30 to 31 minute. Window duration is 60 and similarly you can see, you know, this is 29 to 30 and the previous one would be 28 to 20. Oh. Oh, yeah. I triggered that, so don't ignore the manual trigger, but this should be 29 to 30 and this one is 30 to 31 and the next one would be 31 to um 32 because right now it's 1:30 where I am, but this time is UTC. So that's cron data interval. I know this is a little bit confusing, so I want to pause here to uh take any questions specifically with this data interval time table thing. I'll pause for like
Segment 8 (35:00 - 40:00)
2 minutes and then move on because we have a lot to cover. Um Thanks, everyone. And any questions with the data interval stuff? Yeah, I can try to summarize it. When you're doing incremental processing of data, meaning you're only processing a specific time interval of the data. So for example, yesterday's data, you want to use data interval methods. And this will allow us to use Airflow to get the start and end time. And you want time and not your data processing script because Airflow is the orchestrator. Airflow needs uh to do this for you. This is, you know, the class it's an idea of separation of concerns. Airflow handles start time, end time. Your script processes the data. That way, you know, your script is easy to test. You don't have to handle retries. backfills. You just have to process the data for a given time range. And Airflow will take care of time ranges, figuring out what is the exact time to use even when uh your pipeline is delayed, even when um you're doing retries, even when you're doing backfills. Your system doesn't need to worry about any of that. Airflow just need Airflow will do that for you. Would does that make sense? Strong and data slinger. Yeah. Uh great. Uh Wasu asks, "We have to specify the end boundary always if it the current. " I'm not sure I understand your question, Wasu. Is there a Mohid asks, "Is there a option to pass a general start date and end date for all tasks like a batch date? " Um you can define whatever start date and end date you want. Um so I mean, you could I I think I'm understanding it right. You could just say hardcode it or um we will see in the next exercise where we will use a different option called trigger to um compute uh time ranges instead of the standard schedule-based time range. What is the low time stamp of the record? Is the input record reader? Oh, that's a good point. Wasu, that's it always has to be um fact if it mostly fact data is incrementally processed, it always has to be created at time of the record, never of the DAG. Uh because our DAG is processing the data that the time range that's always uh it should always be based on the on the creation at time for the incremental processing. It should not be based on anything to do with when the DAG was created. Um so when we say start and end date, yes, the DAG is using the schedule to figure that out, but when you think about it from if you look at the uh image on the uh left side, you can think about this as one large data, but you process data interval one, let's say it's day one, once and then day two and then day three. Um that way, that should be based on created at time stamp. So if you look at this highlighted part, you could think of it as like select star from source, right? Source where um like this. Created at greater than start and uh created at oh, greater than and equal to start and less than end. That way, it's a non-overlapping uh interval. I hope that helps, Wasu. Um if you do retries and backfills, then you want Airflow to be able to handle this for you. And even if your resources are overloaded and you can't even start a DAG, you don't want to have to compute that logic on your end. You want Airflow to do that for you. Um so Airflow does the orchestration part. Your script, for example, the select star, assume that your script, that will just use the start and end time. Um I'm going to keep going cuz it's getting um time is passing. So, we'll come back to the rest of the questions at the end of the um workshop. So, right now we saw how you could use the schedule to automatically define the start and end times. But, there are
Segment 9 (40:00 - 45:00)
other cases where you might want to do something like a overlapping window. So, if you look at this example on the right side, sorry, on the left side, you might want to run a pipeline every week uh to look at a quarter to do like a quarterly look back. So, the schedule does not match the interval. Um in that case, you could use something called a trigger where it's similar to data interval, but the interval can be different from the schedule. So, let's take a look at an example, right? So, if you look at this here. Oops, sorry. One second. Okay. So, if you look at this example, instead of data interval, we are using trigger. Again, we are running it every minute, but the trick trickier is we can define our custom interval. We don't have to. We can just say trigger it and just be done with it, but we can also define a custom interval. So, in this example, what I'm doing is what we are doing is scheduling a pipeline to run every minute, but looking back an hour. So, instead of just being able to do 1 minute at a time, we can look back an hour. And you know, the logic will be the same as getting uh start and end date, but Airflow now will look back an hour instead of 1 minute. So, if you look at this DAG, let's go ahead and look at that. Let's run it. All right. There we go. So, the interval, you know, it's in it runs every minute, but the interval is sorry, the interval, if you look at this oh these three last three lines, the interval is 1 hour instead of 1 minute. So, the schedule is now different from the data interval, and that you can do with trigger. And using that um create a pipeline called with the DAG ID called custom interval. I mean, DAG ID is basically just this. That runs every minute, but interval should be 1 day. So, not 1 hour, 1 day. You could use this as an example. All you have to do is just print uh do the same thing there. Just print the start and end time. But, in your in the exercise, you should see uh this be 24 hours instead of uh the 1 hour we see right now in this example. I'll see you in 10 minutes. In the meantime, if anyone has questions, please let me know in the chat. Okay. Thomas had a question about using environment variables with Airflow when moving to higher environment. Yes, Thomas, that's typically how you want to use um you want to move from move between environments. You typically have like either be a secrets management system like AWS secrets or just like standard environment variables that you read with os. getenv environment method. Um and then you have different environment variables and specifically connection and S3 uh locations, you store it as environment or some other configuration management stuff. I hope that answers your question, Thomas. Wasu asked, what are the best practices for having Airflow workers execute tasks directly instead of using separate So, it depends Wasu, if your data is not as um small enough and your machine that you're running Airflow is large enough, you can run your process directly on tasks. Um there are also different types of ways you can run Airflow tasks. So, right now we are considering all of these tasks to be running as Python processes in the machine that you're running Airflow on. That is called the local executor, but there are ways you can run tasks on independent uh pods on Kubernetes, or you can run it on independent um resources using something called celery. Um so, in those cases, though you can just think of them as like individual Python processes running in a bigger machine. In those cases, you can um compute within the task itself. Um it depends on what infrastructure you have. If it's local executor, I would just say like use your task as a way to trigger Spark, Snowflake. Don't do the processing within the task itself. But, if you have more complex infrastructure like Kubernetes executor or celery executor, you could just process directly on that as well. Uh Zain asked for backfills. Uh yes, Zain. The data intervals are mostly just for backfills and retries um and then taking that complex logic off your hand uh because if you have to rewrite
Segment 10 (45:00 - 50:00)
it on your uh with your script, you have to handle a lot of edge cases, and it's super error-prone. Um so, it's typically best left to Airflow. Are there any other questions with the trigger pattern? Or we could look at the solution. Um so, again, similar to what the example we just saw, all you have to do is instead of 1 hour, you just say 1 day. That's pretty much it. And Airflow will take care of the rest for you as long as you get uh use the get_current_context. If you are using a old version of Airflow or if you're working on a legacy infrastructure, you will hear something called macros. Basically, it'll look something like um something like this or like this. That is essentially this part. Um so, that is something called a template. Uh so, if you see something like um data interval start, that is equivalent to what we have here. So, just keep an eye out on that. This is basically what people mean say when they mean macros. Um so, this is kind of similar concept. We are just using a function to do that here, whereas um in older Airflow or template or SQL templates that you are using, um this is basically called macros. Uh Sriram asked, but it's always better to use run date t minus 1 instead of macros. Yeah. Uh I'm not sure what you mean by run date t minus 1. Uh we can come back to that, um but can you if you can clarify that in your question, that'll be helpful. Okay. Um another key point, I mean, this is not very important. I don't see a lot of people using that, but one thing to note here is cron isn't the only way. You could use something called delta. Basically, cron when you use cron, it's usually the start of your clock. So, if you say every 30 minutes, it's 1 1:30, 2, and so on. If you say every minute, it'll be the 0th second of every minute. Whereas, you can use delta, it's just the difference between the last run and the current run. So, if you have this as delta, you know, instead of cron trigger, if you say cron delta, uh sorry, delta trigger, instead of cron, you say delta trigger, um the next run will be at uh you know, if you say it every hour, it'll be at like 2:25, and it'll do it'll just do it every hour and not snap back to the start time that cron does. I would just stick with cron. It's just easy to reason about unless you have a real uh compelling reason to use delta. So, those are how you schedule it. So, we saw scheduling with cron, what time table is, data interval, and triggers. For most cases, if you're just using snapshot, trigger should be fine. But, if you're using incremental, uh look for um data interval methods. That'll be very helpful cuz you don't want to be handling these date stuff. Um DBT does something similar as well. It uses the incremental flag to do the incremental part. Um but, it uses a logic of IDs as well. But, here or sorry, uh it uses a logic of date time column. But, here you get the date times. So, it's up to you to do whatever you want. For example, if you want to query an API for with specific dates, you can use that. So, Airflow gives us that option to get the start and end time based on the schedule. All right. So, that's end of that section. The next section is coordinating multiple pipelines. Let's go to questions real quick before we move on.
Segment 11 (50:00 - 55:00)
Uh so, the use case for this would be if you have events that have some latency being written your data to be up-to-date. Yeah. Yeah, basically, um that's right, Data Slinger. I I'm not sure I should name, but yeah, this is basically like you could use the time table to wait for a few minutes to get data events. Uh you could also do lambda architecture where you could say like hey, you know, trigger this every day or every hour, but when the time is like, I don't know, 24 or 23:59, which is 11:59, instead of interval 1 hour, do 1 day, so you could do a catch-up. So, you can do a lot of things with these sort of um trigger and interval. Okay. Uh let's move on to the next section. The next section is coordinating pipelines. Let's close this. As your team grows, as your infrastructure and use cases grow, what will happen is there will be multiple pipelines using output from other pipelines. So, it'll not just be one pipeline, it'll be like five or six lineage of pipelines. The problem there is the downstream pipelines are unaware of when the upstream pipeline completes. So, what people used to do was they used to have something called sensors that we saw in the first section in the downstream task that just pings the upstream DAG to see, "Hey, is it complete? Is it complete? " They also used to do have like upstream task trigger downstream task downstream DAGs. They used to have um the downstream task just grab do a snapshot pipeline even when the data is very large uh instead of doing incremental because they don't know when the upstream completed, right? So, when you're coordinating two DAGs, it gets really tricky for the downstream DAG to know when the upstream data is ready. Um that has caused a lot of issues, a lot of wasted resources, um a lot of time spent debugging what went wrong when it went wrong. So, recently, and I think Dagster started this and Airflow has it now as well is the idea of asset-based scheduling. So, what asset-based scheduling means is if you have a pipeline, it generally typically just produces one table for most in most companies. And you use this the this update to the table, you define it as a upstream pipeline. And all these downstream pipelines can just look at this table and see when it updated and run based on that. So, instead of downstream pipelines running on a schedule, it'll keep an eye on the data, see if the data has been updated, and then run. So, now the coordination problem is kind of solved because all the upstream has to do is update the data, and the downstream it doesn't know when it will start, it'll just look for an update, and it'll start as soon as um the upstream data is updated. But, this also has the downside of not being able to have a specific SLA because you are dependent on upstream, which is fine in most cases, especially as as, you know, with the downstream pipelines, it's typically fine. So, that's what data asset-based scheduling is, and it's not just a pipe uh excuse me, Airflow thing, it's a kind of orchestration concept. Excuse me. Let's look at an example. So, upstream DAG, and let's look at a downstream DAG. There we go. All right. So, then how to do this in Airflow? And this is similar across systems, but the idea is you create these unique data assets. It could be a data table, it could be whatever you want it to be. And here, I'm just using a fake S3 bucket URL as this data set. All you have to do is in a task, you say, "Hey, my outlet of this task is this specific data asset. " Right? This data runs this the pipeline runs every hour, but when this task completes, consider that this data set has been updated. It's not really you don't really have to update the data set, you can just specify it, and Airflow will consider that it has been updated, uh but that's just what we have right now. So, here all we are saying is, "Hey, run this task and write transform and write. " We are not doing anything, to be honest, but we are saying like, "But, if this task completes, consider this um data asset updated. " That's the upstream. This is the producer of the data set.
Segment 12 (55:00 - 60:00)
And it runs every hour. In the downstream are all the consumers, what they do is they again have to define the asset which they're reading, right? Instead of the schedule being some sort of cron or trigger, all we are saying is watch out for this data asset. The pro here is there's no schedule, it just knows when to run it based on upstream updates. The con is um again, there's no schedule, so you can't guarantee that this will this pipeline will run at a specific time, uh which may or may not be fine uh for most cases, it's fine in my uh experience. So, producer will produce, consumer will wait for this, and just consume it, and just trigger that. So, on Airflow UI, if you go to the UI, um click on assets, and we had it defined as hourly report. If you click on hourly report, you can see all the upstream data sorry, pipeline that produces it, and all the downstream pipelines that depend on it. Um so, you can see here there are two, uh the new downstream, that's an exercise you will see uh next, but uh for now, we are just using producer data asset consumer. So, now we have kind of side-stepped the coordination problem across DAGs. The main thing is that the asset has to be unique identifier. Airflow allows it to be a URL format, so it follows a specific format. It has to follow a specific format. It's like data um storage in S3 is one of those, so you could use that. Again, the output needs to you need to specify that a task is updating this data asset with the outlets uh uh uh input parameter to task. And on the consumer side, all you have to do is schedule it as an hour. And if you want to get information about the upstream pipeline that triggered this downstream pipeline, you could use something called triggering asset events, and you can get their information here as well. And I'm not going to run this now because it's going to take a while, but basically, if you switch on both these pipelines, um you will see something like this. You'll see something like this, you know, the downstream will run, which will trigger the upstreams. Now, for an exercise, I want you to create a pipeline called simple data pipeline, and this data pipeline has to have a simple data asset, right? That the that it outputs. It could be any just some simple task that just says, "Hey, this asset has been outdated sorry, updated. " And I want you to create a new downstream DAG called new downstream, and this new downstream instead of just depending on one pipeline oh sorry, one asset, it should depend on two. So, hourly report that we just created, and sample data asset that you will create in this exercise. Um this is a pretty complex exercise. I'll put 10 minutes on the clock, and I will see you then. And in the UI, it should look like this. If you have any questions in the meantime, um let me know in the chat. Okay, there are a couple of questions. Um Sriram is asking, "How can data engineers ensure they're not replaced by AI um feel that technically strong? " Um so, yeah, that's a good question, Sriram. I think code generation is easy with LLM. And it's not complete though because LLMs still make a lot of mistakes. I mean, people say it's one-shot stuff, but honestly, it's not always one-shotting stuff. It's sometimes it makes pretty stupid mistakes. I think you need someone, and I know a lot of people a lot of engineers know this, too, you need an engineer who knows what it's doing to be able to uh use it. I think I generally think it's it's very helpful to generate code only when you know exactly what you're doing because it makes these subtle changes, and it kind of throws off your entire output. So, you do need to know what you're doing when it when it comes to like the implementation details. Um for example, in this uh example we were seeing here, right? If it suddenly uses trigger instead of data interval, we don't know that, you know, if you don't know the code, you don't know what it's doing. So, you still need to know System design has become more important for sure, especially with the speed LLMs can generate data uh sorry, generate code. System design is is critical because with outputs being so fast with outputs, I mean the number of lines of code, I guess. You need to make sure that your system is solid, otherwise things will fail. It's going to be a pain to fix. And you know, you don't want to wake up at 3:00
Segment 13 (60:00 - 65:00)
a. m. with like something failing and some critical data stuff failing and no one knows what's going on. So, you need system design and you need sort of a gatekeeper, if you will, who knows what the [snorts] AI is trying to create. Vasu asks, "Basically, upstream notifies downstream with the trigger rather than downstream and That's basically it, Vasu. It's more of a I would think of it as like a The update is an attribute of the data set. And the downstream just watches the data set. Um so, you can have like multiple upstreams updating the same data set. And the downstream is just watching the data set. It's not watching the upstream DAGs. So, the update time is a characteristic of the data set. And a lot of big tech companies do this internally. So, when I was at Netflix, we did have a system that tells you when the upstream data is updated. And that was a characteristic of the data. So, they also have like complete things like this data is 80% complete, 99% complete, 95% complete. So, those are characteristics of the data. So, think of it as the data has its characteristics. Your downstream is looking at the data, not at the pipelines because you can have like five pipelines updating the same data set. You don't want to do that, but you can do that. So, I would think of it as a attribute of the data rather than the attribute of the data pipeline. So, data singer said as so that could be a non-public S3 bucket, but you would just You don't actually that that's a implementation detail. You don't need access to the S3 at all. It doesn't even have to be real. Like for like here in this example, I just made it up. It's not real. But, Airflow doesn't understand that yet. It just thinks that when someone defines a unique URL, it exists. Uh it doesn't verify anything about that. So, it's just a way to say this is what we are doing. We don't really have to do that. Even here, right? We are saying we are transforming and writing or the output is this asset, but I'm not doing anything regarding that asset. I'm just printing some stuff. Um so, yeah, it's just a way to define the dependence. Airflow doesn't verify that it the update is actually happening. Zain asks, "When creating a cloud deployed project Um Zain, is this for what is the objective of the project? Is it for showcasing your skills or Yeah, I think that will dictate what you're trying to do. If it's your work, but I got I'm not sure what this means, but I'm assuming you're may you're saying you want to showcase your skills. Um I'll come I can we can come back to that later, Zain, after the session is over. I'll hang around for a bit for any questions you have. Vasu asks, "We can when we use AI for PR reviews, etc., we expose Um I think if you're an enterprise client, you typically have privacy stuff written into your contract. But, uh I'm not sure how you will safeguard your code because you need the AI to know your code to um review it. I mean, you can locally run your AIs in internally. Uh that way your company has access to it. Only Um but otherwise, I'm not sure how you if you're sending data to cloud or uh Codex, I'm not they will see what you are sending them. So, Al-Hassan asks, "But how does the data downstream know if the update is complete? " So, that's a tricky part. I I'm hope I hope you're I'm pronouncing your name right, Al-Hassan. Airflow doesn't understand that right now. All it understands is hey, someone said uh someone updated the metadata for this data saying it has been updated. That's all it considers. It doesn't really verify that it's actually being updated. So, that's I mean, that's a really tricky one to follow, right? implement. Like, how does an orchestration system know that the data is updated? So, I guess Airflow offloads that to the engineer. Hey, you know, it's your responsibility. The engineer or whoever is building it needs to do make sure that the data is updated and it's not just fake saying fake news, I guess. Um yeah, I can touch base with you on that, Zain, after the after we
Segment 14 (65:00 - 70:00)
end the session or sorry, after we end this workshop. Sriram, what's your favorite IDE, or sir? Oh, I I just use Cloud. So, yeah. All right, let's continue on because we are running low on time. Okay. So, for this example all you have to do is uh Is it this one? Yeah. Let's look at the downstream. So, what we are doing is again, we are just creating a simple producer pipeline that produces this data asset thing. Um it is a asset that we are saying, "Hey, this sample task updates, right? " And then we are creating the downstream. But here, the interesting part is instead of just one which we saw in the previous example, we have two as part of the schedule. So, what this means is this new downstream pipeline will wait for hourly report and sample data both to complete at least once before uh starting. So, if you look at this UI example or sorry, this screenshot, you can see that, you know, downstream waits for at least one run of both. So, simple data pipeline could have run like 10 times, but it will the downstream will not start on at least until uh both of those upstream have one runs. So, that's what you are seeing here. Simple pipeline run twice, but producer DAG only once, and which triggered the downstream. So, it depends on both assets being updated at least once for downstream to start running. Okay. Um so so, that's um cross-pipeline dependencies. So, let's move on to the Airflow processors. But, I'll just take a quick question before we move on. Um Pra asks, "When you try to write the data basically Um Yeah, sure. I think we went through this earlier, but yeah, I can go through a quick example just to it's a recap before we move on to the architecture section. Um so, there are multiple ways in Python sorry, in Airflow to write a DAG. Back in the day, it used to be like something like with DAG. Uh you can create a DAG object, but these days most of the pipelines use task flow API, which basically means you create a function and then you just put this decorator on top. You just say like, "Hey, this is a DAG. You know, this is its ID. It's scheduled to run every day. It should start on 2021 um and other attributes you want. And within this DAG function, you can have individual functions and define them as tasks, right? So, you can say like, "This simple ETL DAG has these three tasks and this is the order in which we are running the tasks. " All we are doing here is extracting the data. So, we are running the first extract task. And then we are running the transform task with the output from extract task extract task, and then finally we are loading doing a load task. So, that's basically what um kind of a DAG and pipeline would look like. Now, you can do complex things like parallelizing uh creating task groups, etc. But essentially, the idea is if you put tasks in this array format, it runs in parallel. That's imagine. Ravi asks, "Is there any method in Airflow to use the watermark buffer for CDC implementation? " I'm not sure I understand your question, Ravi. Watermark buffer for CDC implementation? Uh is it the is it waiting for late events? Is that what you mean? Deepak asks, "Uh architecture to run Airflow? " Uh in large companies, Airflow runs with something called a Kubernetes executor or custom executor. So, what that would mean is Uh let's look at this, right? Like, if you consider this DAG this as a DAG, all of this will run in the independent um infrastructure either as a Kubernetes pod or celery. Um again, if you go to large companies like Fang or stuff, they usually have their own implementation. I mean, Apache Airflow was from Airbnb, so they still use Airflow, but a lot of companies have their own internal Airflow that essentially just like triggers its own like virtual machine somewhere in like Kubernetes and it runs there most of the time. That's what I saw at LinkedIn and uh Netflix, they just run their own system. It's similar, you just trigger a Kubernetes pod or something similar.
Segment 15 (70:00 - 75:00)
Pras for the real-time project, real-time I would not use Airflow. And by real-time I'm assuming you mean under micro millisecond latency, not micro, sorry, millisecond latency, I would not use Airflow because Airflow you want to be using Airflow only if that timeline is like 10 minutes or longer. Anything shorter than that um you are typically looking at a system which requires a shorter SLA, I wouldn't use Airflow, I would just use something completely different like Flink or Spark Structured Streaming. Okay, very very. All right, let's go to the next section. I think we're running way over time. Okay. Um so, Airflow. This is kind of an architectural overview. We're not going too deep into it, but it'll give you a good idea to prevent some fopa. So, uh when we think about Airflow, there are like two things. One is the SDK side of it. So, things like, "Hey, from airflow. dag SDK import dag task. " So, that's the Python part of it. Then there are also processes that run Airflow. So, Airflow has two main processes. One is the dag processor, one is the scheduler. So, when you create a dag, what you have to create it in the Airflow dags folder, excuse me. Sorry. What happens is there is a Python process running in the background continuously that every 5 seconds by default parses the files in this dag folder. So, it'll like just parse through the entire file and see if any of those are new dags that have been added. If it finds a new dag, it'll take that information, so basically this information and store it in the metadata DB, which is the Airflow database powering Airflow. And Airflow UI. So, that's the responsibility of the dag processor. And then there's the scheduler. So, what the scheduler does is it continuously looks at your metadata DB to see if any dags need to be scheduled and what frequency to and when it should be scheduled. So, dag processor reads the files, stores the information in the DB. Scheduler reads the DB, starts your pipeline. And this is basically these are basically the processes. So, here, oh not this one. Here we are seeing, you know, this is just Python process, so you can see Python running this dag processor. And then scheduler. So, these are just processes. PS aux is the Unix command that is I think PS stands for process status. Aux is just a way of making it human readable. So, you could just say like dag processor and scheduler are basically just Python processes running in the background. Now, the What the scheduler will do is it'll use something called an executor. So, executor is a mechanism by which Airflow runs your tasks. So, when you have a dag, a dag can have multiple tasks. You need to tell Airflow how to run these tasks. By default, Airflow will do something called local executor, meaning it'll take your the machine it's running on, it'll run one Python process per task. Um that's the local executor. And the task data called worker, so one Python process is called a worker. It'll run one task at a time. But there are different types of executors, so you can have something like a Kubernetes executor. So, what that means is instead of running individual task as a process on your on the single machine, it will create a Kubernetes pod and run it on Kubernetes. There are There's a system called Celery as well. What that would mean you can use Celery executor and what that would mean is instead of running each task as a Python process in the machine, it'll just run it as a Celery worker. And Celery worker is its own thing, but basically think of it as like an older version of Kubernetes. I'm making a bad assumption, but that's essentially what it how Airflow uses it. But local executor can take you a long way. For example, in my machine I have 32 cores, so you can see Airflow sets as 32 workers running and by default it sets my parallelism to 32. And all this setting is stored in something called a configuration file, airflow. config. So, if you go to here, you can look at all the settings you want for your Airflow. So, here you can see it has the local executor set up by default. You can change everything here. Um if you're an admin, you could also see do it via this UI. Um I mean, I chose not to expose it by default, but you can do that. If you have admin access and you have that set up properly, you can change it via the UI as well. Any question with the with these Airflow
Segment 16 (75:00 - 80:00)
processes? Basically, dag processor to identify which Python scripts are dags, scheduler to start your um dags and executor is a mechanism by which your tasks are executed. By default, it's local executor, meaning one Python process is per task. And that's what we see as Airflow worker here. Any questions with that? Okay, I guess there are no questions. All right, so let's move on to the best practices section. Okay. Oh, there is a question. Uh dags are always independent runs or can we run dependent dag runs? What do you mean by dependent dag runs, Wasu? Do you mean to say if a dag should be dependent on its past run? If that's your question, yes, we can define that as part of your dag definition. We could go to our dags and we could just say depends on past. Like it's intelligence not working, but there basically there's a operation or there's an input argument says that says depends on past, you can use that. So, Pras how do you audit logs, check performance and job metrics? That's a good question. So, typically I would go here, right? And I'll look at like what's running, if there's any queued or if there's something has been running, I would typically like go to the individual dags. So, if you look at this, right? I'll go to that dag and I can look at all these individual runs. So, you'd see every run. And you can look at the logs. Um you can even like look at a gantt like all these charts here to figure out how it has been performing over time. Um I just look at this duration for most of the time. Uh but honestly, most of the time I just look at queued and see what's been running for a long time. And I try to manage it in the dag itself. So, I With Airflow 3, there is a something called timeline. Uh I forget the exact name. Let's see here. You look here. Yeah. Should be here. You could say like, "Hey, has this dag been running for a long time? " Uh if so, oh, deadline, that's the one. Has it Has it been running for a long time? If yes, uh send me an alert. So, I try to manage it programmatically because I don't want to be managing it via the UI all the time. I just want it to alert me. But there it's a double-edged sword because you don't want it to be too um too tight, and you'll get a lot of false alerts, you don't want that. But you also don't want it to be too um vague as in just depending on the UI, then it's hard for a engineer to manage because now we have to go to the UI and look at it and think about it. Does that answer your question, Pra? So, Wasu asks, "So, the life cycle of a dag is its own dag current dag run? " Yes, a dag is typically independent. Um when you do need a coordination between dags, you use something like the data asset approach, but for the most part a dag is independent and it should be independent. Okay. All right, let's move on to the next section. Again, I'll leave I'll stay a bit after the session for any questions. So, let's quickly go over some best practices when you're using Airflow. Use Airflow for scheduling and orchestration. Like what we saw in the incremental pipeline, keep the logic to determine the start and end dates in Airflow and keep the logic to process your code in whatever code you're writing. We didn't cover the code part here, but basically you need a separation of concerns. That way if there's an issue, you can clearly see what the inputs to your script were and where the issue happened. Um the second part is specifically for local executors, not for all types of executors. If you're using local executors, your Airflow task should only trigger the processing
Segment 17 (80:00 - 85:00)
of data. So, you could use things like uh you know, trigger a Spark job, trigger a Snowflake job, trigger a BigQuery job, but it shouldn't bring in the data into the task because if you remember, a local executor is just a Python process. If you bring data into a Python process, you can bring down the entire system. So, make sure that you're just triggering it. Unless it's quite small, then it shouldn't matter. But, make sure you're using like an external system if you're processing large amounts of data. Again, this doesn't apply if you're using like Celery or Kubernetes executor where it is in a sense distributed and each task is running in an individual VM by itself, so you should be fine. This one is quite important. Do not write high-level code. So, what that means is when you're writing a DAG pipeline, right? The DAG processor Python process will look at this file every five seconds actually by default. What it'll do is it'll look at this and say like, "Oh, I need to run simple ETL. " And it'll look at each simple ETL, but then it'll see it's a DAG, so it won't actually run it. It'll just take this function and store it in the D or take this information metadata DB. But, if you have like a process here, for example, if you start a Spark if you're trying to start a Spark session here, which is a which is takes a long time, it will crash your DAG processor. I mean, make it really slow. It can't crash your DAG processor because this is a heavy process and you don't and if you just do this Python sorry, DAG processor will run the Spark session creation, which will take a long time and DAG processor will not be able to catch up. So, that's what people say people mean when they say don't write high-level code here. Put everything inside a DAG or inside a task. If you write it here, it will get executed. So, if you say like if you say here save some file, it will immediately get saved, so don't do that. Don't do any processing outside the DAG or task. If it's inside the DAG or task, Airflow will recognize it and not execute it. It'll just store it to be executed at its schedule frequency. What's the next one? Um The next best practice is um We saw this executors our system. The next one is use XCom for small processing data. Okay, we saw it, but we didn't really go through it. So, here's an example that we saw initially, right? So, what's happening here is we are creating some data in extract, sending it over to transform task, which is then sent over to load task. That's what this does. So, let's see what this would look like, right? So, if you look at simple ETL, let's run it. So, this is our task. We are taking extract, we are sending data to transform, which is then sent to load. The data transfer between task is done using something called XCom, which is cross communication what it stands for. So, you can see the data being sent over here. Here. Uh this is a hardcoded value that we created in extract. For this case, it's fine because the data is small. However, in real large-scale project, you don't want to be sending data between task directly because, you know, you don't want to bring in the data into your Python process. What you typically do is you'll put create the extract, put it in an S3 bucket, and transform will read from that S3 bucket, and put it to another S3 location, and load will read from that S3 location. So, you don't want to be moving data between task, especially if your data is large. If it's small, under 1,000 or maybe even a million small records, it should be fine. But, if your data gets large, don't use XCom, use a intermediate cloud storage system. So, those are the best practices. Um The final one is if you are if you're just starting out, um I would strongly recommend not creating your own system to handle scheduling and orchestration. For the most part, you can get away with just a Python script uh when you need to when you're just starting out. But, again, keep the Python script clean. Keep the start and end time generator separate. But, don't recreate your own because Airflow comes with a lot of inbuilt features like you could check the state, you could see history, you can take logs. Uh you have all these like asset-based things. You can also look at um performance over time. And it also has R back, which is role-based sorry, role-based authentication control. If you have a lot of users and you want uh role-based access, meaning data engineers can modify um stakeholders can only view your Airflow UI. And it also has CLI and API, so don't recreate all this stuff. So, that's the end of the workshop. Um the solutions are all available in the repo link in the description. Let's
Segment 18 (85:00 - 90:00)
open up for some questions. So, Anand asks, "How about using local executor as sensor in S3? " Yeah, you can use local executor uh to watch S3 sensors because it it's it's a very lightweight process. So, it's basically just a task that is just pinging an S3 location and see if it exists. That's basically what S3 file watcher does. Um okay. Um so, if you like this sort of like design-based approach uh workshop style, um I'm uh opening a data engineering course for end of this month, so 26th. I'll cover like everything from warehouse, pipeline design, data quality, medallion, orchestration, Spark, data processing, um optimizations, and um deep dive into data processing, um how it actually happens, and also interview prep and capstone projects. Um I am releasing a course end of this month. It's $499 for if you're a newsletter subscriber. If you're just joining for YouTube, maybe not. And it has about 10 hours of content, about 160 exercises and examples similar to what we saw here right now, and uh the main part is it has office hours Tuesday and Thursday 7:00 to 9:00 p. m. for 2 months. Um so, the idea is you would go through the courses on your own and come to the office hours with questions or any comments you want to make. And it also ends with building a capstone project intended for capturing an interviewer's attention. So, for example, this you'll build this basically this is based on real Stack Overflow data. So, you'll say like, "Hey, this is what happened. " Um but the idea is you will build projects that are designed for um kind of quickly grabbing a potential employer's interest. So, I don't know if I have it open yet. Still working I'm still working on it, but basically the idea is you build the foundations, right? You build the design aspect of it, and then you build capstone projects. So, if you're interested, let me know. I'll send out information as well. Um if you are if you're in the email um subscriber, and I only I'm only opening it to 75 spots for now because uh I don't I want to be able to answer everyone individually. Okay, so that's that. Do we have any other questions? Uh Zane, I will send an email. And then there's any Yeah, just send an email to joseph. machado@startdataengineering. com and I'll get back to you. Here's my email. That's my email address, so you can send it to me. Pras, thanks for explaining, but maybe a beginner. Um I So, Pras, I know we covered a lot, and that's why it's it's good to like go over and recreate it. I would recommend not just one-shotting this um this workshop because it it's quite involved, right? Like you know, we covered a lot. I would recommend you go, try it out, try out the example, try out the exercises. Um and in the exercises, spend time trying it out before looking at the answer. I'm not saying you do that, but a lot of people do that. So, try out the examples, try out the exercises without looking at the solutions for a while, and then try and then I think you should be able to catch up even if you're a beginner, especially if you're a beginner because these design concepts uh apply to all the orchestrators that you will be working with, right? And Airflow is just a way to implement these design principles. Okay. Uh Zane, yeah, you're welcome, Zane. When it comes Sar Sart Sartak asks, "When it comes to system design um in data engineering interviews, is it restricted to um Typically, system design with data engineering, it's mostly pipeline design mixed with data modeling mixed with metric computation. So, it depends on the company. Some companies ask like, "Hey, can you design a metric design metrics that for this specific use case? " Um so, it depends on the company, but mostly it's pipeline design with data modeling with some partitioning clustering thrown in and also with the sometimes metric computation like figuring out what metrics to even calculate. Um Rarely have I been asked about like Kubernetes. I remember one company asked me about Kubernetes. Uh but yeah, mostly it's pipeline design and data modeling.
Segment 19 (90:00 - 95:00)
Any other questions? I'll stay for like 5 more minutes if there are any questions. Uh data structure and algorithms I think there are some for sure because I mean, even with the AI, you don't you can't just do today AI, but there DSA and DSA is still being asked just for the companies to understand that you can still code. Um and it's not like super complex lead code. It's usually one of like the easy mediums typically two-pointer question or merge intervals. I mean, I can't tell you how many times I've been asked the same question um at multiple companies. I've been asked merge intervals like at least three, four times uh up till now. Um Facebook and Netflix and DoorDash, everyone asked merge intervals for some reason. So, two-point so TLDR, two pointers, merge intervals, number of islands, those are like critical questions. They always get recycled maybe with a little bit of nuances. Uh but I also notice companies asking more of cleaning of data. So, they'll give you like a list of JSON or a list of dictionary of some sort and ask you to clean it up or find certain elements in it. So, those are the type of question they ask. You are typically not going to be asked like graph traversal or anything dynamic programming recursion things like that you won't be asked. Wasu asked, "Why would we use Kubernetes if we have EMR cluster that do? " Hm, that is a good I mean, those are two different things, Wasu. Kubernetes is a infrastructure system where you can run anything. EMR is specifically for Spark, right? If you want to use Spark job and that's all you're going to do, EMR cluster should be good enough. I'm not saying you have to use Kubernetes just FYI, it's just an option. Kubernetes is typically used when companies have multiple systems they're inter- interacting with. So, if I want to run a EMR Spark job, I could do that. If I want to run a Snowflake job, I could do that in Kubernetes. If I want to run a local job with Polaris, I could do that in Kubernetes. So, Kubernetes is just a more advanced way of or not sorry, I shouldn't say it. It's a more general way of running a process independently. Whereas EMR is a managed Spark. So, you're basically just running Spark with auto scaling. Does that answer your question, Wasu? Oh, it's a paid one for it's uh because it involves like um office hours. Sarthak asked about data DevOps skills for data engineering role. So, typically with data if you see a lot of data engine the DevOps skills, it's usually on the data infra engine- in the in that sorry, data infra engineer side of things. But even if you're just standard data engineer, you need to understand how to scale your system. So, you need to know like what are the system limitations. So, if you're just using Spark, you need to know where is the Spark running? How many what resources does it have? How will it be able to scale? So, Spark has like uh what's that? Flexible scaling. I forget the exact terms. But you need to understand a little bit of that, but if you're seeing a lot of DevOps skills like Jenkins or um actions for CICD, that typically falls on data infra job. So, that would be things like building the infrastructure that other data engineers use. Does that answer your question, Sarthak? You also asked rundown on what to focus. So, yeah, if you're looking for data infra, you would typically want to understand a little bit about distributed processing like specifically Kubernetes or how it works. You want to understand how to uh scale your systems and how to make sure there's no resource contention. Um yeah, I would typically
Segment 20 (95:00 - 96:00)
that would typically lead towards the DevOps side of data infra. Hope that helps. All if there are no more questions, I don't see any. I will end this in a few minutes. Right. All right, everyone. Uh thank you everyone for joining. Again, please let me know if you have any questions about the course. If you are subscribed to my newsletter, I will send out um more information in that over the next few weeks. Still kind of finishing up on some things, but yeah. But the main idea is you have [snorts] 10 hours of content that you watch and then 4 hours of office hours every week for any questions you have, which I'm sure people will um have a good rest of your weekend. Thanks, everyone.