Today I'm really excited to share a talk from the CEO of Distributional, Scott Clark, previously a co-founder at Sigopt
00:00 Guest Speaker Introduction: Scott Clark
01:45 Scott Clark's Background and Experience
03:55 Understanding AI Analytics and Observability
07:09 Demo: Distributional's AI Analytics Tool
14:14 Deep Dive: How Distributional Works
24:01 Q&A Session
31:26 Conclusion and Final Thoughts
Оглавление (7 сегментов)
Guest Speaker Introduction: Scott Clark
So today we're invited Scott Clark the founder of distributional to come in and talk a little bit more about how we think about monitoring production logging. Throughout the course we talk a lot about this idea of not only having the flywheel but identifying segments identifying the impact of these segments how these segments are hurting the user base and then understanding how we can make investments in improving these AI systems. Right? There's often going to be cases where in the real world in a machine learning system if you just get new users or new customers or new models the distribution of how your usage changes and that really was not the case I mean 20 years ago right it's just like database latency or what is the traffic to some application but as a result of AI things have really changed dramatically and so I'm really excited to bring in Scott today to talk a little bit more about how we think about understanding the hidden signal in production AI logs with that said Scott take it away. — Excellent. Thank you so much, Jason. Really happy to be here. I've got an agenda for us here where I'm going to talk a little bit about why you should listen to me at all and then you can make the decision about whether or not you stay for the rest of the talk. But I'm going to talk about how analytics can help augment and be this additive component to the observability stack for Genai applications. I'll walk through an explicit example showing a demo of the product that we've built a distributional. And then I'll talk about some of the underpinnings of what we did, some of the trade-offs we made, and some of the system underneath it. And then the entire product that we built is free and openly distributed. By the time this talk is over, if you get started now, you could have it running on your laptop and be using it to analyze your own AI agents. If people have questions throughout, feel free to just ping. Maybe Jason can pay attention to chat and interrupt me and we'd be happy to talk through any of this and I'll leave time for questions at the end as well too. First up, who am I? Why am I giving
Scott Clark's Background and Experience
this talk? I've been building AI tools for more than a decade now. My first company that I founded was called SIGOP. It was an optimization tool. So, think hyperparameter tuning and neural architecture search back when people were like building their own models. This was based off of my PhD thesis and we got to work with a lot of really cool people including OpenAI in their very early days, helping them tune some of their early RL models back when they were a video game RL shop. But ultimately sold that company to Intel in 2020. And this is when I started to see some of the pains not just in optimizing AI systems, but the pains that you have when you start to really try to scale these systems up. I was VP of AI and high performance computing within their supercomputing group. So we would sell these billion-dollar supercomputers to government labs and they needed to be performant. And this is where I realized that one of the big bottlenecks to getting value out of these massive investments isn't just performance. It's not about squeezing that last half a percent out of an eval. Nobody stays up at night thinking, man, if I could just overfit a little bit more, then finally I'll have value. It's about really understanding these systems and having the confidence that they'll work as expected. People stay up at night hoping that their app doesn't do harm or that it actually gets the value that they're trying to give to their end users. And that's what led me to found distributional in 2023 really about how do we get a better handle on understanding AI? And as Jason mentioned earlier, these systems are just fundamentally different than they were a decade ago. They're way more non-deterministic and chaotic and non-stationary. There's a lot more complexity. You can look at the confusion matrix of a fraud detection algorithm and say, "Oh, is it does it have the right true positive and false positive rate, etc. " It's very difficult to do with natural language and impossible to do as you start to look at these agentic systems. So, we're a well-funded small researchoriented statistically oriented shop today focusing on AI analytics. So that's me, but let me dive into the problem more specifically. So what is analytics and
Understanding AI Analytics and Observability
how is that different than just observability or monitoring more generally? Jason was hinting at, our goal is to help accelerate the AI data flywheel. As Jensen puts it, there's a lot of effort that goes into just developing apps and agents and these applications and then going into deploying them. But if all that you're doing in the observability is just monitoring alone, that can help tell you if the system is up, if a timely error happens, it can give you highlevel view into whether or not your emails are drifting or performing well on any given day. But this is this extremely macro view. And on the other hand, you have great logging and tracing and debugging platforms and it can help you really dig into and understand maybe a very specific session. But there's this missing chasm between the tool that we're claiming is agent analytics. And that's really trying to bridge this gap of when you have many things going on, how do you really discover, understand, track, and fix these hidden behavioral signals within this larger slew of data. So you can think of it similar to maybe product analytics or user analytics for a more traditional web app. But instead of treating the user as the atomic unit where you have some funnel that you're trying to get them through, now you have the agent as the atomic unit and you're trying to understand how many different agents over many different sessions perform a specific task and what specific clusters and patterns and subbehaviors they may exhibit throughout that. And this again can help complete this AI software development loop by knowing what to look for. You can create better eval. reward functions for fine-tuning or reinforcement learning. It can point you to specific issues that you could use to append your system prompt or do any other sort of improvement to the system itself. Looks like maybe there's already a question. I saw the chat thing go off, but I'll let Jason be my moderator. So again, this is part of a larger observability picture. It's not about which one is better or which one you should choose. It's about the right tool for the job. And so the very first thing you should do is just start logging. If you're not logging, then you have no way to go back and retrace your steps or figure out specific bugs. This is incredibly important in that build step as you're debugging. Monitoring can give you timely alerts and let you know if the system is broken or if you need to jump on something right away. And then analytics is less about timeliness and more about richness. And this is about how do you go about improving the system. It tells you what is happening, where it's happening, gives you evidence of it, and then starts guiding you down that path of continuous improvement. And so you can think of this as this Maslov's hierarchy of servability needs for any agentic stack. And depending on where you are, you're going to want to use one or more of these tools. But to really start to get the value of the AI data flywheel, you need a little bit of each. Cool. So I'm going to try to ground this in a very specific example. Um, and hopefully
Demo: Distributional's AI Analytics Tool
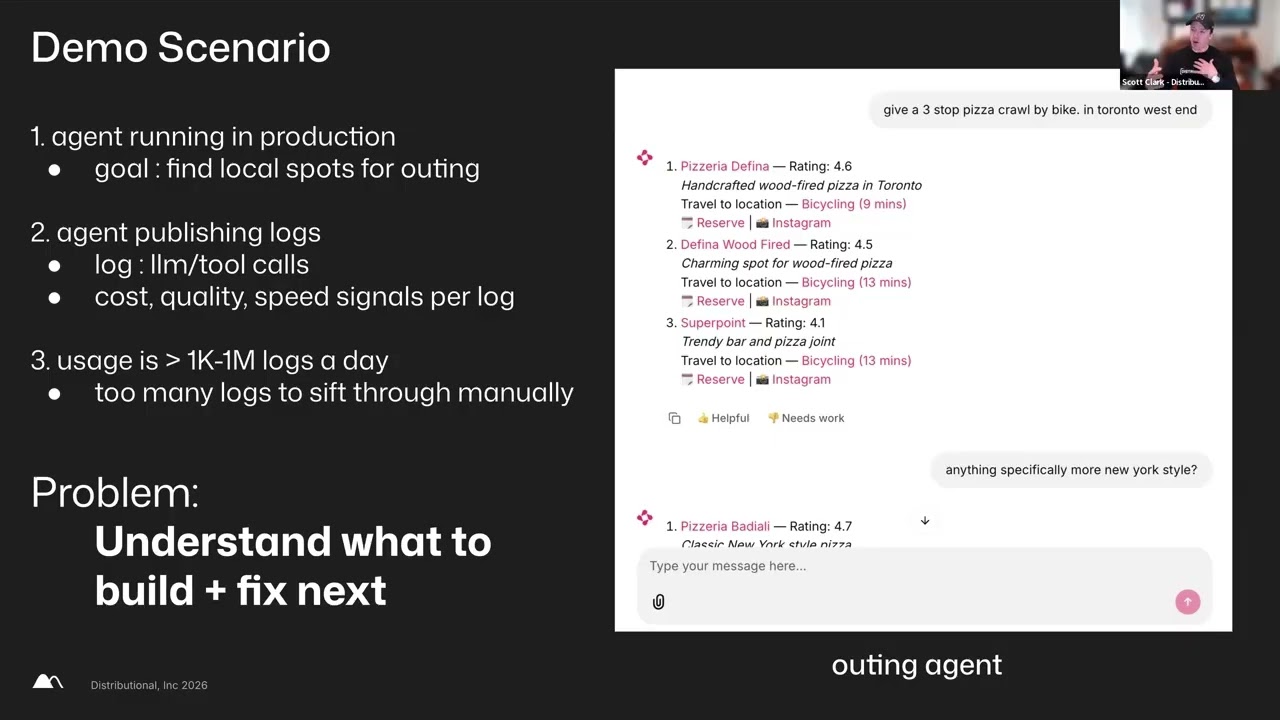
this resonates with some of you and this will also dubtail into our demo. So, I'm going to start with a very simple agent that we built internally and we use this for dog fooding our app. It's one of the many agents that we built internally. You can think of this as like a Google Maps or like a Yelp style agent where you ask it for something to do, three stop pizza crawl in the Toronto West End, and it goes through and calls a bunch of different tools and MCP servers and things like that to give you an itinerary. We're going to assume that there's an agent running in production that can kick off open telemetry traces. It's giving not only the user input and output, but you're also tracing all of these individual tool calls. This is happening automatically if you use some of the great tools like Google ADK or AWS's agent core with the Nemo Nvidia's Nemo agent toolkit, Langmith, whatever it may be. Open telemetry tracing has become this kind of lingua frana for logging how these tools interact with each other. We're also going to assume that there's more traces than you care to look at one by one. One of the things that we noticed when we talked to firms a year or two ago is when they were first getting started, they were dog fooding their own applications. They had a handful of users. they could afford to look at every single session and every single trace and deeply understand that once you get to thousands and definitely when you get to millions now you have this needle in a haystack problem. If only a small fraction of your users are actually providing feedback, how do you find the patterns? signal? How do you find that signal from that noise? And so I will show you how you would go about doing this in distributional. This is going to try to motivate how you would try to attack this problem. So at the very high level, let's assume that we have again all of these individual questions and answers from our agent. Again, relatively simplistic tooling system here. Maybe I'll make this a little bit bigger and hope that doesn't break our dynamic. But you can see this simple question could kick off Google Map searches, web searches. It's visiting web pages for these individual things. is trying to do quite a bit in order to build up this itinerary for the end user. But again, let's assume we have many of these. How do we start to see the patterns? signals of what's going on underneath? At the high level, we can start to just do some of the same aggregate statistics that a lot of other observabils have. Log counts, token counts, cost. But because we're trading off timeliness for richness, we can also start to do a bit more unsupervised learning. little bit more clustering topic analysis. We can start to look at this broader distribution of behaviors instead of each one individually or aggregate statistics alone. And so we can see different topics that people have, see the distributions of different tool calls. Here's we're zooming in caused an issue. Feedback scores correlate these things together. Start to see these segments and patterns as they start to overlap with each other and join this to richer information that you might not have at that monitoring or guardrails level like user feedback or user frustration or the relevancy of the answer after you've looked at the entire session. So, this is all good and this can help give you like a slightly different view and allow you to slice the data in different ways like you would with potentially any BI tool or tracing tool. But the real value comes from being able to go one step deeper. So now that we have all of this information, and I'll go into detail in a second. Now that we've built up these behavioral vectors for each one of these individual traces, how do we start to see the patterns in that broader distribution of behavior, that fingerprint of different behaviors that your users are using over the course of a day or multiple days? And that's where we apply this concept of insights. And so this is these are the needles in the haststack that we've pulled out of that data. Specific issues that you may or may not be aware of. The joy of an eval system is if you know the question to ask, if you have a way to phrase success or to phrase a specific behavior, you can set an alert for it. You can monitor it and it's very easy to see whether it degrades. But finding the unknown unknowns, finding the things that you didn't know to ask about or to write about can sometimes be a very difficult problem. And so by doing this unsupervised clustering, we're able to find things like redundant and inefficient tool usage and start to point to very specific issues with evidence of here's exactly what happened. We're having repeated tool calls. I made a second identical Google Maps tool call. We can look at this specific evidence for this more explicitly. But beyond that, we can also suggest potential fixes. And these can vary from, hey, you should change your system prompt and that's super simple, a quick when to maybe you should have a caching system to make sure that you're not asking the same thing multiple times if you have to do the same type of request over and then adding guard rails potentially to make sure you're actually calling those caching systems. And so this not only found what was potentially an unknown and as we were doing a lot of dog fooding with our apps and are working with our customers, it's surprising how many of these little paper cuts exist within that mountain of trace data that you would otherwise be unaware of. We also provided a potential fix and then give you the ability to track this to a make sure that your fix actually worked and potentially run an AB testing experiment, but also make sure that doesn't happen again. So from this alone, we were able to find an issue, fix an issue, track whether or not that fix actually worked, but then also go through that AI data flywheel of adjusting our prompts, potentially adjusting our reward functions as we're doing reinforcement, learning, and fine-tuning and really acknowledging the fact that not all data is created equal. You want to find these things that can actually drive you forward. Ask the right questions, find the right evidence, and use that to guide the development of your applications. — Doc, can you share a little bit more about how these suggestions are being created? Is this like a purely like unsupervised task or how you're thinking about generating these suggestions? — That is a great question and is literally the next section of the talk. So actually, so how does it actually work? Were there any other questions before I dive into that? I think one question was just mostly asking for clarification on how you think about the logging stack. I know there's ways of uploading data manually through parquet files also going through open telemetry but I think yeah Greg would love to a little bit more love to learn a little bit more about the logging and how we get data into distributional. — Great question so I'll actually cover that in this next section as well. So maybe I'll get through this section and then we'll open up for even more questions. So how does it actually work?
Deep Dive: How Distributional Works
Again, the super high data flywheel at the largest level from Jensen or whomever else is talking about this is effectively you deploy something, you observe what happens in the real world and then you use that to make your application better. So we're assuming that again there's some agentic system already deployed. Getting data into the system can happen in a variety of ways. So again a lot of these agent toolkits and frameworks already have open telemetry built in. And so this allows you to very easily just route your traces to distributional much in the same way that you would write route them to other great monitoring products like data dog or cloud watch or something like that. And so write once but send many style tooling. There's other ways to get data into our system as well too. Some of the firms we work with have already very robust ETL pipelines. So from their log stores we can get the data in through parquet files as you mentioned. We can sit on top of an iceberg table. We can do SQL ingestion if some of these exist as like user or session events within a larger table. But basically however the data is formatted we have a way to get it in and fundamentally our goal is to take the richest possible version of the data. If you only have inputs and outputs, we can get some level of insight out of that. But as you give us the tracing data, user feedback, as you start to join that to other session level events or other evals that are coming out of other tools, we can do better and better. The deeper the signal, the more we can extract from it. Underneath the hood, our system is performing this unsupervised data flywheel where we're taking in those that data. Again, let's just assume it's hotel traces for now and we're enriching that with different behavioral signals. So these can be Elm as a judge eval, they can be classic natural language processing statistical measures, they can be things again brought in from other tools. We [clears throat] provide defaults. We provide templates, but we're agnostic to how you actually come up with these. Again, the goal here is to take whatever data is being thrown off the app naturally and try to add as much enriched signal as possible to it because then every trace can fundamentally have this behavioral vector in some highdimensional space that represents what actually happened. The analysis part comes from looking at many of these vectors. So a distribution of these behaviors and be able to pull out subpockets of these distributions to be able to say this is something that didn't happen very frequently or this type of behavior is correlated with this cost latency or quality style issue that we want to be able to address. So we pull those subclusters out of this behavioral distribution and then we feed that back into an LLM. So this is hitting whatever LLM backend that you already have in place. It can be the same one that's powering your agent. We have recommendations for a variety of different open- source ones if you want to run them locally. But we're able to say given this set of 20 interesting things, what happened? And fundamentally towards the end, how would we go about fixing this problem? Because of this, we recommend using an analysis LLM that is maybe midweight, so like 20 to 70 billion parameters, has some reasoning in it. But you can actually use a variety of different LLMs for the cheaper judge style where we're looking more about quantity and throughput to be able to get a bunch of signal. And then it becomes more and more refined as we get towards those insights that are ultimately published to the user. And this is where the human comes into the loop. they can look through these insights. We're trying to build this kind of concept of tab complete analytics where instead of doing a week of data science yourself, it's just presented to you and you can very quickly triage. Oh, I care about this issue. I don't I'm going to investigate very quickly to see whether or not this is something worth solving, track it, but ultimately make some change to the underlying system itself to keep the flywheel moving. And we have examples on our GitHub and we've done some great joint work with Nvidia. We're doing more with Amazon and things like that about showing how you can make use finetuning, hyperparameter optimization, reinforcement learning, or just good old prompt or context engineering as part of this flywheel. But the goal is fix a problem, find a new one, find a new opportunity, and continually do this over time as simply as possible because our view is that we 100% of your time should be focused on building the agent itself, not digging through individual traces. So that's it at a super high level. Does that address both those questions? — That's for me. Thank you. — Wonderful. So one layer deeper and again all of this is available on our docs. The product itself again is completely free and deploys on premise in whatever cloud you have or bare metal that you have. The sandbox can work on your laptop and you could be up and running by the time I finish this talk. If people have deeper questions about these what I'm about to go over, we go through quite a bit more detail in our docs. So again, that first step is about enrichment. It's about adding a bunch of behavioral signals to that already somewhat rich trace information that we get. The goal here is again many weak signals are better than a single strong signal. So instead of trying to come up with how do I create an eval that perfectly encapsulates quality, what we want to be able to do is maybe have a whole bunch of different signals around frustration or tone or verbosity or reading level or things like that. And we can again through the next step cobble all of that together to be able to find these vectors of behavior that are actually extremely interesting. Having done about a decade of Beijian optimization with my first startup, I will say every single time we went to a company, whether it was OpenAI or the trillions of dollars worth of hedge funds that we work with or Netflix or whatever it may be, we would help them optimize a function and that equivalent to an eval today and it would do very well, but they would say, "Oh, but it missed this other thing or this went up, but this went down or this created this behavior that was not aligned with what I necessarily And so I personally view that it's impossible to have one objective function that rules them all or one eval that rules them all. But having many of them can start to get all of these different parts of that actual experience that you want and you can project that onto this much denser space to find these behavioral again pockets and segments. And that's what we do at the analysis step. So we take all of these enriched logs and we start to do unsupervised learning and clustering to be able to find these pockets. And this is more than just like looking for the outliers because while outliers might be interesting different sub peaks of that highdimensional distribution are also very interesting. You may have a very standard way of interacting with your tool but behavior especially in these agentic systems is incredibly multimodal. So finding these local optima of behavior end up being these clusters that you may want to look into of users misusing your application or trying to make it do something it doesn't do already or running into some of these issues that I showcased before. The final step is then of course publishing it. So like taking those and actually explaining it to the user, making it more visible and digestible, trying to get down to the point where you can again start to perform this kind of tab complete analytics, quick triage of this is what happened, here's the evidence, here's how hard it would be to fix, diving into what the actual underlying trade-offs are, maybe splitting that sub peak of the distribution and comparing it against the rest and understanding as a product owner, product manager or engineer responsible for this product, what's really going on and then ultimately tracking it. So over time you can make sure that whatever behavior you wanted or didn't want either continues or goes away. Cool. Last part here is a little bit about integration. How to get this spin up and running. As I mentioned a few times already, in less than an hour, you can get this spun up on your laptop. The docs go into quite a bit more detail about this. We also have some blog posts that dive into some of the kind of underlying trade-offs that we've made. I'm happy to speak about those in the Q& A session here at the end. But it's an open distribution. You can grab all of our packages off of GitHub container registry. It installs locally. We don't actually ever see any of your underlying data, but we would love any positive or negative feedback you may have. It's bundled [snorts] as a Kubernetes cluster when you do the full deploy or a small just like K3D cluster within a single Docker image when you're doing the sandbox. So relatively simplistic architecture and it can work again with any underlying system. So any cloud doesn't matter what you're using for your agent backend etc. it can bolt on top. Ideally, you're developing, you're writing these traces already as you're doing logging and monitoring and we just sit on top of the exact same ones.
Q&A Session
So, maybe I'll pause for a second, see if there's any other questions. So, one question from Greg was mostly around can you contrast this with something like just having like offline evals. I think online there's a big discussion on you just need online monitoring because that'll capture all your evals or you just need a val and if you get 100% on your eval real life which feels a little bit ridiculous to believe but yeah maybe just talk a little bit more about how you compare the your portfolio of these like metrics. — Yeah I would say so the early iteration of distributional actually as a company was very focused on testing as opposed to analytics. So it was offline testing. Having come up through like the first wave of enterprise AI, I thought there was no way people would trust these systems in the wild until they were explainable and until they could have like very rigorous confidence. That's turned out not to be true. And I think from like an information theoretic perspective, this is actually the right path because it is impossible to anticipate everything that can happen in production ahead of time. like your users will use your system in different ways. These systems themselves, whatever foundational model you're using is non-stationary and is going to be changing underneath you continuously. So, you're never going to be able to get full confidence ahead of time. The only way to see what actual behaviors emerge and these can be very emergent behaviors is by observing what happens in the real world. And a lot of this is going to be happening continuously and these improvements are going to have to be happening continuously too. So I wouldn't say this is a complete replacement from doing eval by any stretch of the imagination. But this can help point you in the right direction of maybe I should have an eval to catch this type of behavior. Maybe I should turn this unknown into a known that I test against or something that I use in my reinforcement learning as a reward function to actually optimize for. — And I think that's incredibly valuable. But it's basically this combination of I think it's impossible to understand ahead of time. You only really see what happens in the real world by observing the real world, but it can be part of that flywheel. For sure. That totally makes sense. I think a big one really is this idea of as you do your online analysis, you're going to find these failure modes that you bring into your eval. So you know the next time you build something that's not going to happen, but you're never going to get 100%. Right? I feel like I saw some posts, some YouTube videos that was like, "Yeah, we have 100% of your evals is I can pass a kindergarten math test and get 100%. " — Exactly. — That says nothing about how I'm going to perform in the real world. — Exactly. Or back in the old days when Yeah. you could overfit a random forest to get 100% on your test set, but that doesn't mean that you're going to get 100% in the real world. And especially again when you don't have these binary outcomes, when you have these either natural language or agentic style systems, it doesn't even make sense to talk about it in terms of percentages. In my mind, it's all about this way more continuous behavioral space that you're trying to guide your agent through. And our goal is to make that a little bit more natural so people can focus on the building itself. — Yeah, totally. I recently just worked with someone where they felt like the AI was being too nice and as a result was taking too long and none of these are really like categorical variables that we can track over time. You just have to hope that these judges just work and we can make progress in a direction rather than fixing an issue necessarily. — Exactly. And sometimes only by observing many weak signals for behavior are you able to extract that strong signal for performance that you actually do care about. There's been a bunch of papers around depending on how you phrase your emails or whatever it is, it like has all these false positives like you're trying to catch negativity but instead it just catches misspellings or something like that. — Yeah. — But in reality like misspellings is an interesting behavior that might actually provide something as well. So by having many of these weak signals, you can actually find that stronger signal that's just this is just a projection of — Y. You can't bring those back to just like classical ensembling. — Yeah, exactly. It's it all comes back together. I would just say it's way more chaotic and dense and complex. And that's part of why we believe that you need this tooling because again, if you were just doing binary classification, a confusion matrix is good enough. But when you're doing agents, this behavioral approach is what you need. — I have a second question, but I think this slide will address a little bit of that. So I'll ask this. — Yeah, we find people again need this when they have something deployed in production when they care about having either performance or quality like behavioral understanding of the system. We see a lot of firms in more regulated industry prefer kind of the shape of our product. this on-prem first, secure first, you own the data, you own the model style application. The main places where we've seen agents in the wild are I would say like rag type systems where again maybe it's just literally a tool two tool agent where it can retrieve and summarize. But one thing that we've seen in a lot of companies is they've built up that ask HR that ask it style system and instead of just telling the user what they can do to go fix the problem, they're actually adding in more tooling so that the system itself can go fix it. So I ask how do I do PTO instead of just pointing me to a website? It's okay, I did that for you. And one thing that we found is like those systems like can become combinatorily complex extremely rapidly that even that router of what type of tool should I call let alone the actual tooling and everything else underneath it can become really interesting. And so I would say as you start to go from that complexity of literally just here's a chatbot that I'm asking one shot to rag systems to actual agents performing work doing RPO RPA whatever it may be that's when you need to crawl up that Mazov's hierarchy observability and go beyond just monitoring is the system up is this eval that I came up with on offline still at 98% and start to look into these behaviors because again there's a lot of needles in that haststack and finding them can be very orthogonal to the job of actually building that wonderful product. — Yeah. I also just want to add here I think I've seen a lot of companies where as you just build more tools maybe your eval work really well when you had four of these like MCP servers installed but all of a sudden you both have GitHub and linear and then everything erodess because it doesn't know what an issue is. a ticket is and all of a sudden the system is failing in really nonlinear ways and again like that UI you had with having the ability to like debug how tools are being called it could just be the order of whether or not the GitHub MCP was loaded before the linear one you get some odd behavior really quickly — how do you scale up these tools — or because these directed graphs are not a cyclic like having it call the same thing over and again and get stuck in a loop it's surprising how often they're designed to try to return something And when they can't, they can go off the rails pretty quickly. Excellent. Any other questions? — I don't think so.
Conclusion and Final Thoughts
— Wonderful. Thank you all for joining on a Wednesday and sticking through to the end. Again, if you have any questions, you can shoot me an email directly at scottdistributional. com. We'd be happy to get you set up and yeah, let us know what you find. There's a lot of probably interesting behaviors in a lot of your applications and we would love to help discover those unknown unknowns and help you fix them. — Yeah. One question I had mostly was just out of my own curiosity which is like what are some sort of common failure modes you you've seen as you've deployed this product elsewhere. Um, yeah, when I've done processes like this, for example, we once went like viral in Turkey, — and so all of our prompts became like Turkish language prompts, but our system message was in English and all of a sudden the output was just like Turkish half the time or something. Or we did a marketing campaign that targeted a different user base and all of a sudden the capabilities we thought worked for this new investor user base just didn't work, but it worked for the manager. Those are some like small examples on my end. But I'm curious like what have what are some things that you've seen that are just really low hanging fruit that people should be tackling. — Yeah. So that expansion aspect of it that you were talking about, we've seen this happen before where again whatever you come up as you're building it like you are going to use your product differently than anyone else at all or than your co-build partners or who you have in your PC. And so we've talked to firms where again they're scoring well on their eval like everything's looking good and then they roll it out to the rest of the company and all of a sudden everything starts breaking or they roll it out internationally and all of a sudden all these guard rails start breaking because people ask questions slightly differently and then the systems oh someone's trying to root the system prompt or something like that when in reality it's just the way that they're interacting with the system. And again noticing that something's broken can you can figure that out in a monitoring system. this eval went down, the number of language responses in English went down or whatever it is, but then correlating that back to, oh, that happened because they're in this geo or because they were trying to address this one part of the system. This country doesn't call it parental leave, they call it maternity leave or something like that. And being able to pull all of that together is really interesting. The other thing too is just there are so many rough edges with these systems and there's so chaotic and stochastic and there's just so many weird edge cases where you're like oh I didn't think I needed to put a retry there because it's so obvious but in 2% of my traffic I get this 403 error and so it can also help you find all the — again interesting edges where yeah maybe your eval function went from 99% to 98. 8% but pointing out is that's because this specific thing happened can be really interesting — and again as you start to look at the combinatorial complexity of these directed graphs of like aentic tools like it there's a lot of edge cases and you're never going to be able to come up with all of them ahead of time. — Yeah. Yeah, it's almost like if you know you want to get a lot of users and get a big business going, you have to get demo tree, which is something I tell a lot of these companies I work with, but sometimes it's still hard to prioritize some of this work. You talked about offline on evalu logging then tracing and then you do this behavior stuff. It is a lot of work for a lot of companies and I'm curious how you try to help motivate the leadership team to really make some of these investments. Yeah, I think the — might come back and say, "Hey, we have 22 tests. They're working. Why do I need to like set up all this infrastructure? " — Yeah. And I think fundamentally it's you hit the nail on the head. If you want a lot of users and you want them to have a good experience. I feel like there's two types of ways to approach this problem. One is I don't see any problems, therefore I won't they don't exist versus I want to know about these unknown unknowns. If you stop testing for a disease, that doesn't mean the disease is cured. And by looking into this and really trying to understand it, that's why we try to typically like our ICP is a product owner. It's someone who thinks of their product as a pet or as something that they actually care about its well-being and they want to improve it as opposed to a checklist that they're like, as long as pager duty is not going off, I'm not getting yelled at, so I don't care about it. And I think more and more, especially as these agentic systems start to provide more and more value within the enterprise, more and more people are going to have to take on that agency and that care to make sure that they do what they're supposed to do. And we help you play that game of whack-a-ole because fighting disease or like parenting or whatever it is, there's always another issue that comes up and we're just going to help give you that flashlight so you're not wandering around in the dark alone or only looking at your evals and not looking at the rest of the room. — Yeah. I think that example of just not testing for the disease and your disease is a big one. This reminds me of another example where we were working on some productivity software and everyone just thought that email was the most important thing. We spent like four months or four weeks, excuse me, making email search really good and then we make a push to add observability at the very end and then we find out that 30% of search queries were based on like photos. — Exactly. — And they're like, who's working on this? We had no idea that this is actually what people cared about. They wanted to find images and like screenshots of the cell phone photo of something written on a napkin that was actually a purchase order. And that was the thing that was important because actually these people don't use email, they just use text message with JPEGs. And that was a huge blow, right? We found this out a month too late. Whereas I can imagine if we had like just a smaller product, added the observability, we may have been able to detect this weeks in advance. — Definitely. And it's there's that old adage, you optimize what you measure, but you only measure what you know to look for. And so this helps you look see more and then measure more and then hopefully optimize for the right things. — Yeah, that totally makes sense. I think that's all the questions I had. I don't know. I don't know if you have any other messages you have for the folks here. I think any other gotchas you think we should be thinking about as we build out these AI systems, as we add this observability, as we invest in our infrastructure. if you have any last final messages out and then — yeah I would the thing I would say is I mean there's that old Mark Twain quote history doesn't repeat itself but it rhymes think of the early days of web or microser architecture or mobile or whatever it is like building was a big first step and logging is important so you can actually see what happens but then you need to do monitoring but of course every single one of these massive paradigm shifts in the way you write software or the way you deploy software analytics does come in and that's where you can actually squeeze out that most value and get to that great amazing product. And so as you're building these systems, you may be in the stage of I can't even get it to work. But as you get past the stage of I want it to scale, be best in class. Um start thinking about those that observability hierarchy of needs and analytics can help push you there. I think this is an obvious and inevitable thing. We are one solution here. But in general, don't go don't be pigeonholed into the specific evalu that you're looking at. Look around and try to find as many unknowns as possible. — Yeah, totally. I feel like people feel like they have a lot of control if they just change a bunch of the words in the system prompt, but usually the big solutions are much more behavioral, right? They're investments in tooling, defining new tools, even just like understanding how people are using the product. that's generally more important than trying to just change the system prompt and see how well my 15 tests go. So, I think that's a great message to have for everyone else here and listening offline. We'll be sending an email afterwards with any of the slides materials and other links including me email and the documentation. And with that, I think we can wrap things up. Thank you so much, Scott. And — thank you, Jason. Great to chat with you as always. — Take care. We'll see everyone else online. Cheers. — Take care.