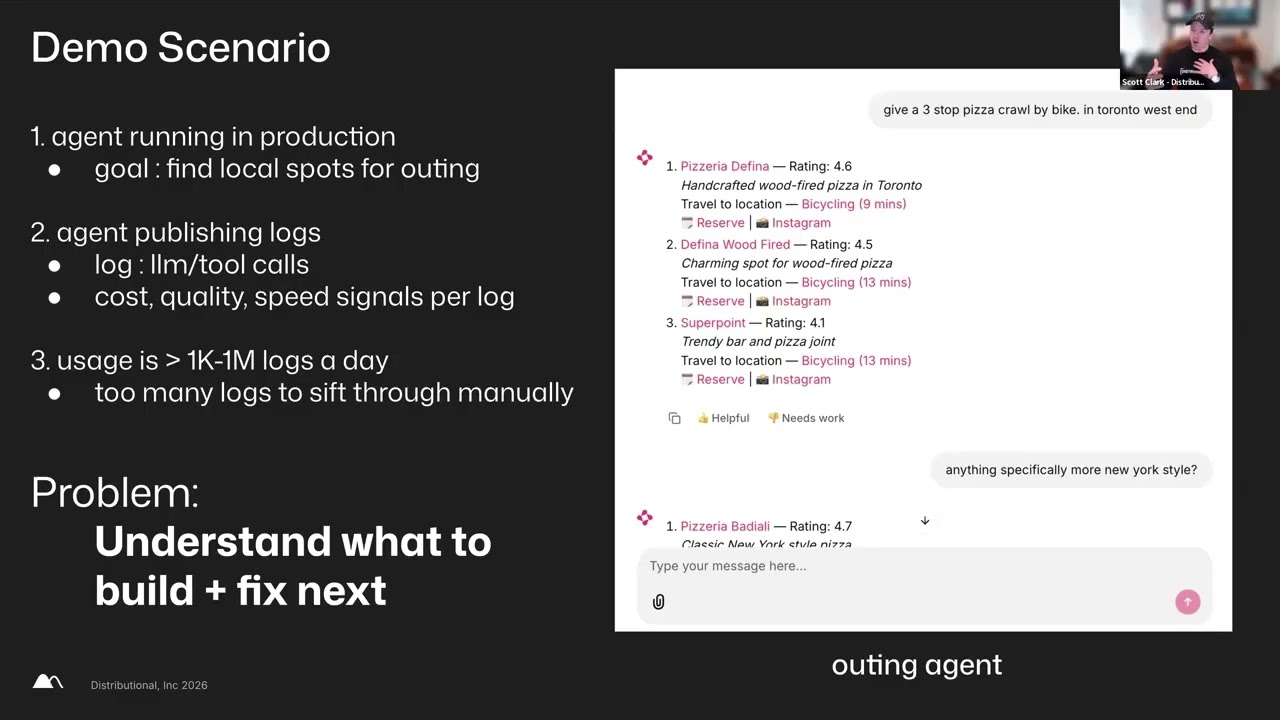
I'm happy to sort of uh I believe I'm answering questions now. But uh yeah, we we'll definitely jump into some questions. Thank you for this talk. This has been super insightful. Um I actually just saw the GitHub action slam. might want to ask about that later, but let's go over some of the top questions first. How's that sound? Cool. Um, I think the first question folks asked was actually around some of the scoring tools that you had. Uh, you know, they said that Brain Trust offers many LLMs of a judge such as things like which ones did you find to be most useful for the team and how often do you have to make your own evaluators? I saw some correctness conciseness stuff. I would love to hear more. — Yeah. So I we use so to the question of which ones are most helpful. This is a top answer but I think it just depends on like what the thing is that you're evaluating. But uh what I can say is I didn't use our uh we call them auto evals. It's like our like out of the box evaluators. I didn't use them uh exactly as is. I started with them when I first designed the evals, but I would see the evals and I would see, okay, wait, it's scoring things, but the vibes are really off here. So then I would go about, okay, like I want this to uh score them the way I wanted to and sort of uh change up the LLM as a judge as I went along. So I think they're great as a starting point and we provide that a lot of them but what I would say is they're not perfect and uh I would say use them as a starting point. Use this prompts uh LM judge prompts as a starting point but create your own uh go out go off of the auto eval and build the one that you feel like would uh is judging the task the way you would want it to judge. Uh and I think I wish there was like a perfect answer but like see the vibes see how it's uh judging and compare it against like you know take a data set or take sort of an eval uh you score it and have an have that LM judge uh LM judge score it see how it differs and prompt tweak the judge itself to get it to behave the way you would score the thing and at that point I think uh you're going to get better response instead using the thing out of the box. Totally makes sense. Um Evan had another great question here which is around the best practices on deploying and hosting agents on the web. Uh do you use something like the cloud agent SDKs? Do you have your own SDKs? Um how is everything done behind the scenes? — Yeah, I think we like personal projects like I love like AI SDK coming out of our cell. For us, we just built our own. We didn't use any SDKs and we just like built uh our own code on top of the uh the proxy that we have. We have a proxy that allows us to hit uh sort of any model that we have configured. Uh but outside of that, we didn't use any SDK and we sort of uh wrote our own code uh on top of things to have like the most minuteed control over how things work. But I've heard uh from our customers great success using AI SDK and other SDK. So I don't think you can go wrong with any of those solutions. Um just you know make sure like you know it's really going to depend on the specific kind of interaction the UX you want to provide uh to the user but I'm sure you'll find success with any of those as well. Makes sense. Um, one of the big questions that people had was really around your comment on sort of finding looking at the logs and finding these other use cases, right? So, how did you can you walk us through a little bit more about how you went through this analysis process? Were you just reading at like, you know, a 100,000 logs day one and just understanding what people wanted? Were you interviewing people or were you maybe doing something like clustering or trying to understand or maybe building classifiers to understand what is the proportion? because I thought I heard you mention that you know one use case has now been growing compared to another. Um I think clarity on that would be super helpful. — Yeah. No, that's great. Uh so at first when we shipped I was going by them one by one because you know when first release it's not like you have a bunch of users like hammering this thing at all times. And so that's how at first we were gathering signals around oh wait the users are asking to generate data set rows. uh but we obviously can't do that yet and we saw like many cases of that. So then we sort of built up the uh the confidence that that's what we should build next. And then um at some point and at the point when we had uh the capability for loop to be able to slice and dice the logs to do fuzzy things with the logs, we did start classifying things into like okay look at the past week's interactions and break them down into like what kind of workflow uh that users are trying to do and we use that. It's like the dumb classifying thing, but we use that to also inform ourselves at some points. Um, but a lot of it for us was like going through the logs and sort of combing then seeing where users are asking things that were a bit different than uh like optimize this prompt for us. Um, the other thing is this is not to say if I gave the sort of uh the nuance that you don't have to talk to users because you have logs. Please know like we have our users tell us all the time, hey, this is cool, but I want to be able to do this with the agents and we use that as a signal as well. Uh, and that's a huge signal for us. And so we talk to users as well uh to inform what we do. Another good question that Evan had was around using things like sub aents. I think a lot of folks have had different uh experiences with like write only sub aents, read only sub agents. Um you know do you feel like have you explored that at all and does it make sense for the team to explore these things? — What have your experiences been so far? We haven't explored it yet, but we uh the conversation came up recently because with like with more tools at play and the more we like give the agent the ability to grab more context, we're seeing more and more it runs out of the context window. And so then we started thinking what are some strategies we can have to make the most out of the context window. uh impression or sub agents and things like that. So we haven't done anything on that front yet but uh that's something that we want to try and when we try I'm sure we'll see a block coming out of us with some evals. So u that's something that you can look forward to but to be honest we haven't tried yet but the idea of it sounds sounds good for certain use cases to be able to sort of — throw a sub agent to do a certain task come back with only the important parts. Uh but yeah that makes sense. Um oh this is a good question. One of the questions was around how do you recommend organizing your prompts to make them easy to find or update? Um, in the past I've seen a lot of companies just have prompts in code in which case I'm actually a little bit confused on how brain trust will be able to edit that or does brain trust now have some prompt management features as well. Yeah. So we have our prompt in code but there's I think there's multiple strategies uh if we're thinking specifically brain trusts you can upload a prompt uh to our uh product and edit in the UI but in code do something like prompt. load load and it will just grab the latest version of that prompt. So if you have a someone who wants to edit prompts in the UI and make that sort of the prompt that's being used in your app, you can sort of create links like that as well. Another thing is we have this thing called remote eval uh which allows you to sort of like run the agents locally but open up parameters to the agents and surface that up to the UI. So for example and this is what I did with uh MYN exactly in this slide when I talked about collaborating with uh non-technical uh teammates very convenient uh I sort of opened up a parameter called system prompt and you can sort of hook that into the agent that's running locally and so in the UI someone can just go and edit that prompt to see how that uh sort of tweaks the behavior of the LM. Um, so there's multiple things you can do. Uh, it's just whatever fits uh the workflow best for us. This the source of truth system prompts lives in code. Uh, but there's other ways I think you could go about it. I see. That's very cool. Um, another thing I want to just would love for you to share a little bit more on was the GitHub actions. Can you talk a little bit about that? I think that we really glossed over some of those really cool features. — Yeah. So uh we have like a GitHub actions where you can say uh you know so I'm not an expert with uh like the GitHub actions but what I know that we can do is uh like you can say when there's changes to these files run them. So in this case for us it's when there's changes to system prompts or any of the tool code uh run the GitHub actions and you can define these are exactly the eval you want to run and for us it would be uh the eval that we think are the most important workflows. So like the prompt optimization, uh the quality of synthetic data generations, quality of BTQL query generations and we run them whenever there's any kind of changes to code that could affect the agent. And so that way uh you can sort of uh watch out for regressions um if you've made a change to sort of other surface area in in the agent uh if the other parts regress or not. And you know, you'll just see and it's obviously like not deterministic. You'll sometimes see like it didn't actually regress, but the scores might come down a little bit. So, it will be sort of a requirement for you to, you know, once again go in there and see if the vibes are off or it's just like, okay, it dropped 3% but it's not really regression and sort of do that uh critical thinking uh yourself. But yeah. I feel like if you just offload all the thinking to the LLM, what you're saying is you believe it's smarter than you. Um, didn't take another look at some of these questions. — Oh, yeah. One question here I'm really curious about is you talked about how these GPD models or these OpenAI models are really underperforming the anthropic models. Um, how do you feel like the solution would actually look like? Do you feel like you would have two separate prompts for two separate models? Maybe you would just say, you know what, I just want to move forward with Cloud Four until GP sort of like cleans up their mess. Um, yeah. How do you think about the situations where Yeah, like one family of models really underperforms another. — Yeah. So, for us that answer the answer is really easy. I think it would be harder for other products. For us, we are a infrastructure provider model agnostic and we are strictly like bring your own key. So there's we have a bunch of customers — who because of the company layout like they they're only allowed to use sort of open AI models or they're only allowed to use anthropic or they can use whatever. So we want to have separate prompts uh each prompt sort of uh specialize for the model or the provider. If there's like a generalized thing we can do for the provider rates. But I think what will happen is we'll have a specific prompting strategy for the 03 models and then the GBT models separate and then we're going to use the ones we use today for claude. Um so for us it's easy because we want to be agnostic for uh if you know if you have a product and you're bringing your own inference and you might even say we're going to hide what model we use and in that case you know you can just use one prompt for that case but yeah — yeah that definitely makes sense I didn't realize that even these models were on their own keys that's actually a pretty good uh that's a pretty good feature actually um yeah let me take another look at the question. But before I do that, one question I like to ask everyone is, uh, you know, what do you think is something folks are not really thinking about as they build out these agents? We went over some of the, you know, key takeaways from having better evals, looking at your logs, but um, like what do you think is still one mistake folks are making as they uh, build these things out? — Sorry, was that a question for me? — Yes. — Oh, sorry. totally zoned out. Um, one mistake I think like I get in this mindset as well and I've seen like my co-workers or others as well is when you sort of and this is going to be a very designic uh when you sort of like see evals and think like okay like let me move the needle for this percentage uh let me make this perform you sort of hyper optimize for that. But what you have to sort of I think always keep in mind is the thing that you're the thing that matters the most is the user experience that you're providing. And so like the eval will if you do a great job designing the eval there will be a good mapping between the success criteria of that eval and the user experience the user has. But like keep in mind that the person on the other end of the thing using this agent is another human. And like there's a human aspect of it. For example, you can have let's say I'm going to make him an example like GPT5 incredibly smart and have it run forever and like tackle a complex task. But if that took let's say like five 10 minutes but uh is that a better experience than clock if we said like clock 4 took 2 minutes uh did a little worse but you know which one's a better experience. So like I think you have to think about like what would users like what kind of experience would users want to have and evaluating it but I think you still have to think about that as well. That totally makes sense. I think with that we can definitely wrap things up. Um before we go, is there any other message you wanted to have for the audience here? Yeah, I think uh I mean I'm pretty sure everyone says this, but it's an incredibly exciting time and we have this thing here where uh just by tweaking the prompt, you can mold a program to behave in a way that sort of you know you can sort of inject your uh belief about how it should behave through prompts whereas prior uh you had to write incredibly complex code to make programs behave a certain way. So like experiments and like build out new things and try things out whether you're technical or non-technical like system prompts can like really change the way models behave and the more evas I write and I see that and so have fun with it and I think you'll find that it is really fun. — Thank you for sharing your knowledge here. Thank you everyone for coming by. — Thank you. Take care.