Backpropagation calculus | Deep Learning Chapter 4
Machine-readable: Markdown · JSON API · Site index
Описание видео
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to share the videos.
Special thanks to these supporters: http://3b1b.co/nn3-thanks
Written/interactive form of this series: https://www.3blue1brown.com/topics/neural-networks
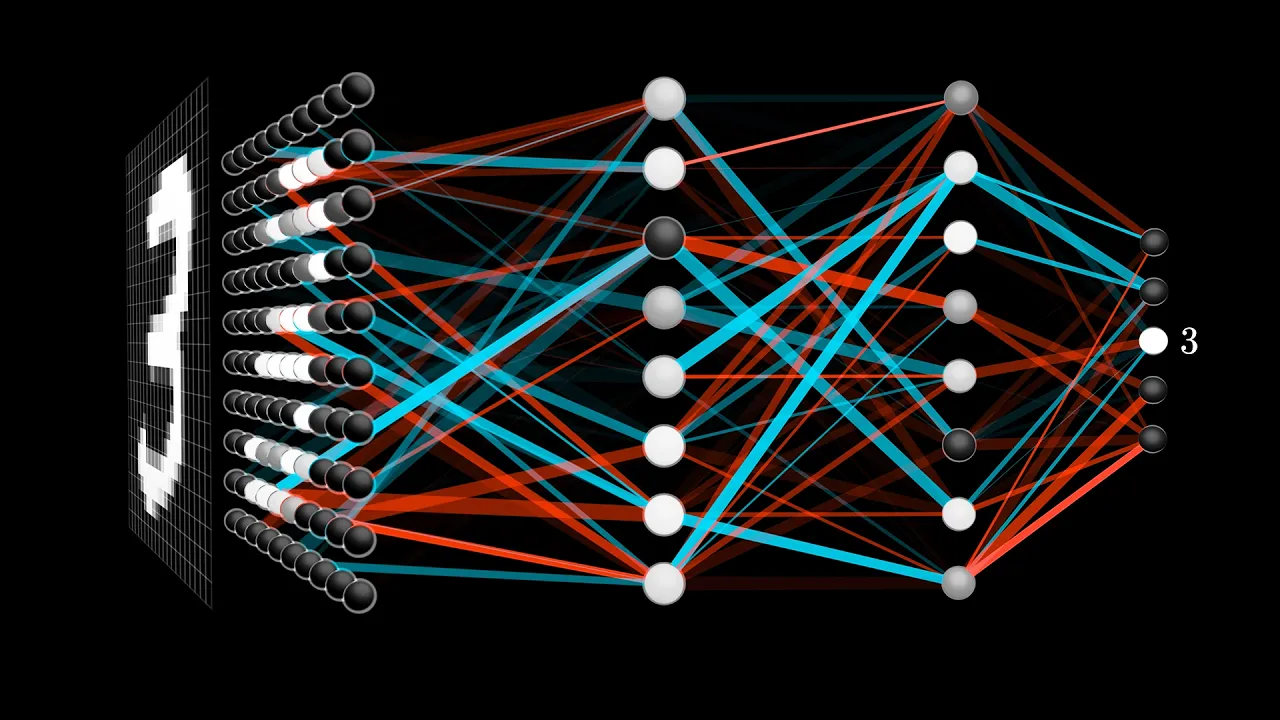
This one is a bit more symbol-heavy, and that's actually the point. The goal here is to represent in somewhat more formal terms the intuition for how backpropagation works in part 3 of the series, hopefully providing some connection between that video and other texts/code that you come across later.
For more on backpropagation:
http://neuralnetworksanddeeplearning.com/chap2.html
https://github.com/mnielsen/neural-networks-and-deep-learning
http://colah.github.io/posts/2015-08-Backprop/
Music by Vincent Rubinetti:
https://vincerubinetti.bandcamp.com/album/the-music-of-3blue1brown
Thanks to these viewers for their contributions to translations
Звуковая дорожка на русском языке: Влад Бурмистров.
Hebrew: Omer Tuchfeld
------------------
Video timeline
0:00 - Introduction
0:38 - The Chain Rule in networks
3:56 - Computing relevant derivatives
4:45 - What do the derivatives mean?
5:39 - Sensitivity to weights/biases
6:42 - Layers with additional neurons
9:13 - Recap
------------------
3blue1brown is a channel about animating math, in all senses of the word animate. And you know the drill with YouTube, if you want to stay posted on new videos, subscribe, and click the bell to receive notifications (if you're into that): http://3b1b.co/subscribe
If you are new to this channel and want to see more, a good place to start is this playlist: http://3b1b.co/recommended
Various social media stuffs:
Website: https://www.3blue1brown.com
Twitter: https://twitter.com/3Blue1Brown
Patreon: https://patreon.com/3blue1brown
Facebook: https://www.facebook.com/3blue1brown
Reddit: https://www.reddit.com/r/3Blue1Brown